BAT解密:互联网技术发展之路(4)- 存储层技术剖析
2015-05-29 17:48
686 查看
BAT解密:互联网技术发展之路(4)- 存储层技术剖析
1. SQL即关系数据。前几年NoSQL火了一阵子,很多人都理解为NoSQL是完全抛弃关系数据,全部采用非关系型数据,但事实经过几年的试验后,大家发现关系数据不可能完全抛弃,NoSQL不是No SQL,而是Not Only SQL,即NoSQL是SQL的补充。所以互联网行业也必须依赖关系数据,考虑到Oracle太贵,还需要专人维护,一般情况下互联网行业都是用MySQL、PostgreSQL这类开源数据库。这类数据库的特点是开源免费,拿来就用;但缺点是性能相比商业数据库要差较多。随着互联网业务的发展,性能要求越来越高,必然要面对一个问题:将数据拆分到多个数据库实例才能满足业务的性能需求(其实Oracle也一样,只是时间早晚的问题)。数据库拆分满足了性能的要求,但带来了复杂度的问题:数据如何拆分、数据如何组合。这个复杂度的问题解决起来并不是那么容易,如果每个业务都去实现一遍,重复造轮子将导致投入浪费、效率降低,业务开发想快都快不起来。所以互联网公司流行的做法是发展到一定阶段后,就会将这部分功能独立成中间件,例如百度的DBProxy、淘宝的TDDL。不过这部分的要求很高,将分库分表做到自动化和平台化,不是一件容易的事情,所以一般是很牛逼的公司才会做。典型的有:百度的DBProxy、淘宝TDDL如下是淘宝TDDL的结构图:
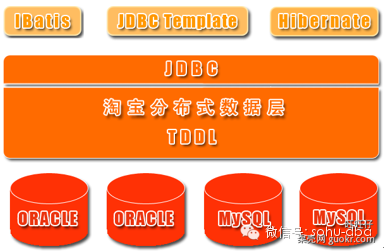
2. NoSQLNoSQL首先体现在数据结构上与传统的SQL的不同,例如典型的memcache的Key-value结构、Redis的复杂数据结构、MongoDB的文档数据结构;其次NoSQL无一例外的都会将性能作为自己的一大买点。NoSQL的这两个特点很好的弥补了关系数据库的不足,因此在互联网行业NoSQL的应用基本上是基础要求,要是你听到一个号称自己是互联网公司却连NoSQL都没用,那基本上可以判断是挂羊头卖狗肉类型的。由于NoSQL方案一般都会自己本身就提供集群的功能,例如memcache的一致性hash集群、Redis 3.0的集群,因此NoSQL在刚开始应用的时候很方便,不像SQL分库分表那么复杂。一般公司也不会在开始的时候就考虑将NoSQL包装成存储平台,但如果公司发展很大,例如memcache的节点有上千甚至几千的时候,NoSQL集群就很有意义了:首先是集中管理能够大大提升运维效率;其次是集中管理可以大大提升资源利用效率,2000台机器,如果利用率能提升10%,就是减少200台机器,一年几十万就节省出来了。所以,NoSQL发展到一定规模后,一般都是走集群路线,当然要发展到这个阶段,一般也是很牛逼的公司才会这么做。典型的有:Twitter的Twemproxy,豆瓣的BeansDB、腾讯TTC如下是Twemproxy的结构图:
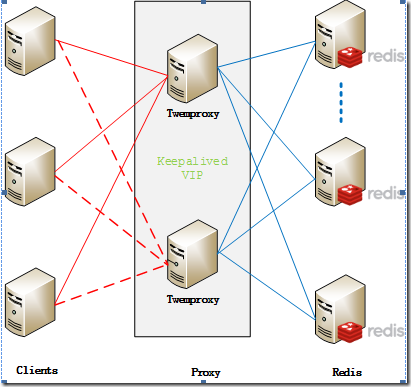
3. 小文件存储除了关系型的业务数据外,互联网行业还有很多用于展示的数据,例如淘宝的商品图片、商品描述;Facebook的用户图片,新浪微博的一条微博内容等等。这些数据具有3个典型特征:一是数据小,一般在1M一下;二是数量巨大,Facebook 2013年就达到了每天上传3.5亿张的照片;三是访问量巨大,Facebook每天的访问量超过10亿。由于互联网行业基本上每个业务都会有大量的小数据,如果每个业务都自己去考虑如何设计海量存储和海量访问,效率自然会低,重复造轮子,投入浪费,自然而然的想法就是将小文件存储做成统一的和业务无关的平台。和SQL和NoSQL不同的是,小文件存储不一定需要公司或者业务规模很大,基本上可以认为业务在起步阶段就可以考虑做小文件统一存储。得益于开源运动的发展和最近几年大数据的火爆,在开源方案的基础上封装一个小文件存储平台并不是太难的事情。例如HBase、Hadoop、Hypertable、FastDFS等都可以作为小文件存储的底层平台,只需要在这些开源方案三再包装一下基本上就可以用了。典型的有:淘宝的TFS、京东JFS、Facebook的Haystack如下是淘宝TFS的架构:
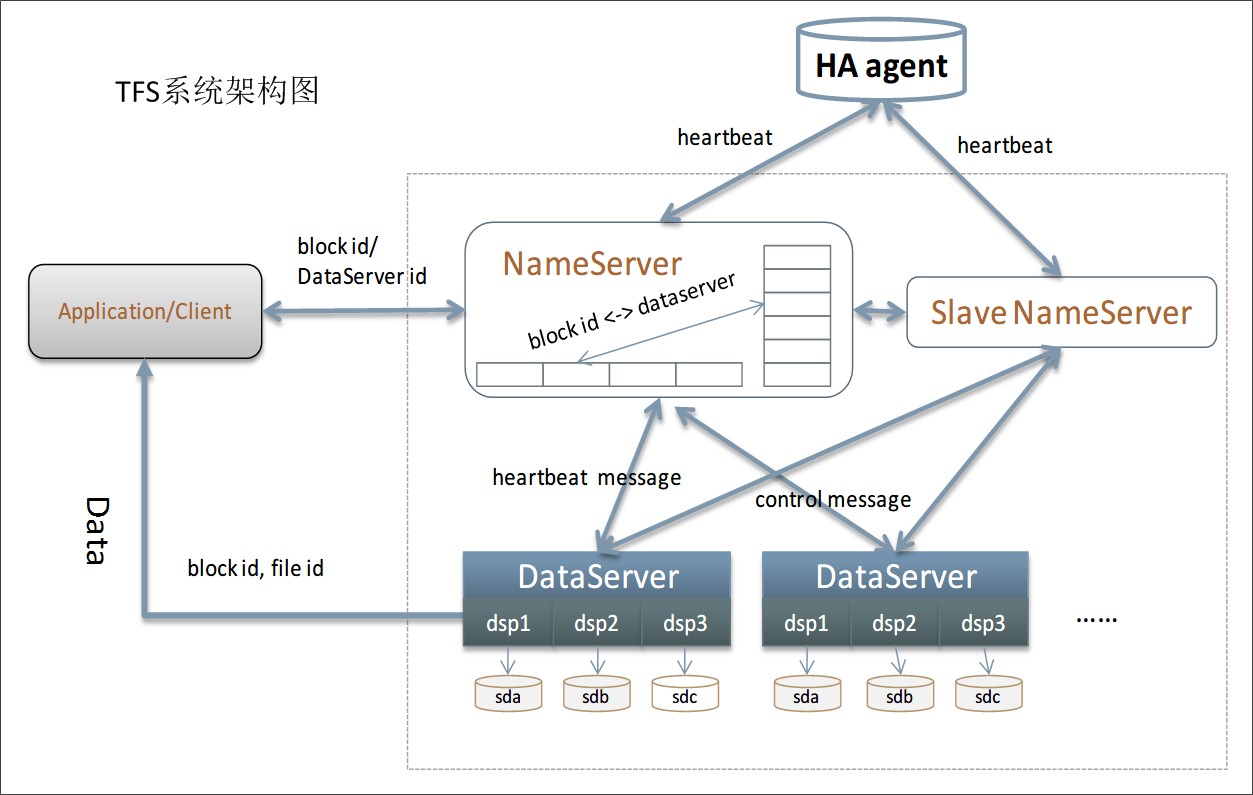
4. 大文件存储互联网行业的大文件主要分为两类:一类是业务上的大数据,例如Youtube的视频,电影网站的电影;一类是海量的日志数据,例如各种访问日志、操作日志、用户轨迹日志等。和小文件的特点正好相反,大文件的数量没有小文件那么多,但每个文件都很大,几百M几G都是常见的,几十G,几T也是有可能的,因此在存储上和小文件有较大差别,不能直接将小文件存储系统拿来存储大文件。说道大文件,不得不特别要提到Google和Yahoo,Google的3篇大数据论文(Bigtable/Map-Reduce/GFS)开启了一个大数据的时代,而Yahoo开源的Hadoop系列(HDFS、HBase。。。。。。),基本上垄断了开源界的大数据处理,当然,江山代有人才出,长江后浪推前浪,Hadoop后又有更多优秀的开源方案贡献出来,现在随便走到大街上拉住一个程序员,如果他不知道大数据,那基本上可以确定是火星程序员 :)对照Google的论文构建一套完整的大数据处理方案难度和成本实在太高,而且开源方案现在也很成熟了,所以大数据存储和处理这块反而是最简单的,因为你别无选择,只能用这几个流行的开源方案。例如:Hadoop、HBase、Storm、Hive等。如下是Hadoop的生态圈:
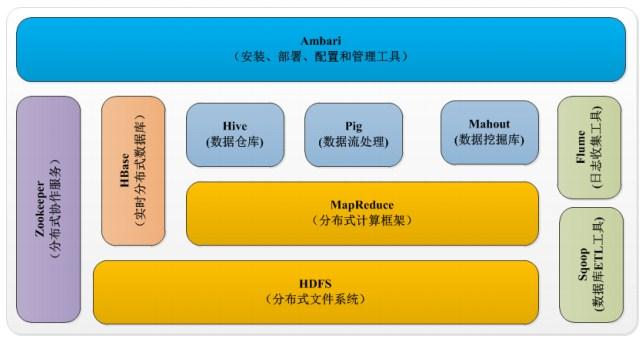
========================================================================转载请注明出处:BAT解密:互联网技术发展之路(4)- 存储层技术剖析
1. SQL即关系数据。前几年NoSQL火了一阵子,很多人都理解为NoSQL是完全抛弃关系数据,全部采用非关系型数据,但事实经过几年的试验后,大家发现关系数据不可能完全抛弃,NoSQL不是No SQL,而是Not Only SQL,即NoSQL是SQL的补充。所以互联网行业也必须依赖关系数据,考虑到Oracle太贵,还需要专人维护,一般情况下互联网行业都是用MySQL、PostgreSQL这类开源数据库。这类数据库的特点是开源免费,拿来就用;但缺点是性能相比商业数据库要差较多。随着互联网业务的发展,性能要求越来越高,必然要面对一个问题:将数据拆分到多个数据库实例才能满足业务的性能需求(其实Oracle也一样,只是时间早晚的问题)。数据库拆分满足了性能的要求,但带来了复杂度的问题:数据如何拆分、数据如何组合。这个复杂度的问题解决起来并不是那么容易,如果每个业务都去实现一遍,重复造轮子将导致投入浪费、效率降低,业务开发想快都快不起来。所以互联网公司流行的做法是发展到一定阶段后,就会将这部分功能独立成中间件,例如百度的DBProxy、淘宝的TDDL。不过这部分的要求很高,将分库分表做到自动化和平台化,不是一件容易的事情,所以一般是很牛逼的公司才会做。典型的有:百度的DBProxy、淘宝TDDL如下是淘宝TDDL的结构图:
2. NoSQLNoSQL首先体现在数据结构上与传统的SQL的不同,例如典型的memcache的Key-value结构、Redis的复杂数据结构、MongoDB的文档数据结构;其次NoSQL无一例外的都会将性能作为自己的一大买点。NoSQL的这两个特点很好的弥补了关系数据库的不足,因此在互联网行业NoSQL的应用基本上是基础要求,要是你听到一个号称自己是互联网公司却连NoSQL都没用,那基本上可以判断是挂羊头卖狗肉类型的。由于NoSQL方案一般都会自己本身就提供集群的功能,例如memcache的一致性hash集群、Redis 3.0的集群,因此NoSQL在刚开始应用的时候很方便,不像SQL分库分表那么复杂。一般公司也不会在开始的时候就考虑将NoSQL包装成存储平台,但如果公司发展很大,例如memcache的节点有上千甚至几千的时候,NoSQL集群就很有意义了:首先是集中管理能够大大提升运维效率;其次是集中管理可以大大提升资源利用效率,2000台机器,如果利用率能提升10%,就是减少200台机器,一年几十万就节省出来了。所以,NoSQL发展到一定规模后,一般都是走集群路线,当然要发展到这个阶段,一般也是很牛逼的公司才会这么做。典型的有:Twitter的Twemproxy,豆瓣的BeansDB、腾讯TTC如下是Twemproxy的结构图:
3. 小文件存储除了关系型的业务数据外,互联网行业还有很多用于展示的数据,例如淘宝的商品图片、商品描述;Facebook的用户图片,新浪微博的一条微博内容等等。这些数据具有3个典型特征:一是数据小,一般在1M一下;二是数量巨大,Facebook 2013年就达到了每天上传3.5亿张的照片;三是访问量巨大,Facebook每天的访问量超过10亿。由于互联网行业基本上每个业务都会有大量的小数据,如果每个业务都自己去考虑如何设计海量存储和海量访问,效率自然会低,重复造轮子,投入浪费,自然而然的想法就是将小文件存储做成统一的和业务无关的平台。和SQL和NoSQL不同的是,小文件存储不一定需要公司或者业务规模很大,基本上可以认为业务在起步阶段就可以考虑做小文件统一存储。得益于开源运动的发展和最近几年大数据的火爆,在开源方案的基础上封装一个小文件存储平台并不是太难的事情。例如HBase、Hadoop、Hypertable、FastDFS等都可以作为小文件存储的底层平台,只需要在这些开源方案三再包装一下基本上就可以用了。典型的有:淘宝的TFS、京东JFS、Facebook的Haystack如下是淘宝TFS的架构:
4. 大文件存储互联网行业的大文件主要分为两类:一类是业务上的大数据,例如Youtube的视频,电影网站的电影;一类是海量的日志数据,例如各种访问日志、操作日志、用户轨迹日志等。和小文件的特点正好相反,大文件的数量没有小文件那么多,但每个文件都很大,几百M几G都是常见的,几十G,几T也是有可能的,因此在存储上和小文件有较大差别,不能直接将小文件存储系统拿来存储大文件。说道大文件,不得不特别要提到Google和Yahoo,Google的3篇大数据论文(Bigtable/Map-Reduce/GFS)开启了一个大数据的时代,而Yahoo开源的Hadoop系列(HDFS、HBase。。。。。。),基本上垄断了开源界的大数据处理,当然,江山代有人才出,长江后浪推前浪,Hadoop后又有更多优秀的开源方案贡献出来,现在随便走到大街上拉住一个程序员,如果他不知道大数据,那基本上可以确定是火星程序员 :)对照Google的论文构建一套完整的大数据处理方案难度和成本实在太高,而且开源方案现在也很成熟了,所以大数据存储和处理这块反而是最简单的,因为你别无选择,只能用这几个流行的开源方案。例如:Hadoop、HBase、Storm、Hive等。如下是Hadoop的生态圈:
========================================================================转载请注明出处:BAT解密:互联网技术发展之路(4)- 存储层技术剖析

相关文章推荐
- 针对特定市场需求和应用模式标准
- 淘宝网和铁道部订票网站采用什么技术架构来实现网站高负载的呢
- 关于架构师的那些事儿
- 如何进行软件架构设计?
- 高可用可伸缩架构实用经验谈
- 我被中国计算机教育的现实打败了
- 开发流程
- 使用.net Remoting技术构建应用系统架构系列(1)
- 面向服务架构(SOA)的原则
- 从此落户-开篇
- 2011数据库技术大会总结
- 设计模式理解
- 软核,硬核、固核的区别!(整理总结)
- VS2010串口通讯架构设计初探
- Discuz!NT数据访问层分析
- 从节能角度看数据中心软硬件设计(一)
- [从架构到设计]第一回:设计,应该多一点
- 过程
- 架构师能力模型解析(转载)
- [读]4. Communication is King; Clarity and Leadership its humble servants