Java基础:正则表达式
2015-05-09 20:31
363 查看
第一部分:正则表达式概述
一、概念
正则表达式:符合一定规则的表达式。
二、作用
专门用于操作字符串。虽然String类中有许多操作字符串的方法,但是这些方法操作起来比较复杂。
对字符串进行操作即便捷、又简单的方式就是正则表达式。
示例:校验QQ号码(传统方法)
正则表达式校验QQ号码:
三、优缺点
1、优点
正则表达式其实就是在用一些特定的符号表示一些代码操作,简化了书写。如JSP中用一些标签代表Java类可以简化书写。(底层的原理还是方法)
学习正则表达式就是学习这些特殊符号的使用。
2、缺点
符号定义越多,正则越长,阅读性极差。
四、正则表达式的构造摘要(构造与匹配)
1、字符

2、字符类

注意:一个[]只能校验一个字符
3、预定义字符
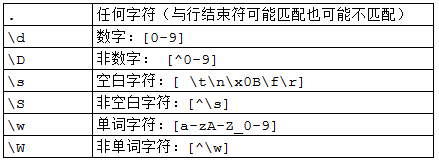
注意:
1)定义类似\d的规则时,要用\\d表示
2)\f代表换页符;\r代表回车符
3)\w(数字、字母、下划线)可用于校验邮箱名
4、边界匹配器

5、Greedy 数量词

注意:X代表一个规则或字符,如[a-zA-Z]?表示该位是字母,可能出现1次或0次。
6、反斜线、转义和引用
1)在不表示转义构造的任何字母字符前使用反斜线都是错误的;它们是为将来扩展正则表达式语言保留的。可以在非字母字符前使用反斜线,不管该字符是否非转义构造的一部分。
2)在java中\代表转义字符,在使用带有\的符号时,必须转义。
3)“.”在正则表达式中代表任意字符,要用“.”切割则需要转义成\\.才代表字符串中的“.”字符。(“abc
4000
.def”)
4)在正则表达式中\必须是成对出现的。
7、组合捕获
1)在定义规则(正则表达式)时,如果后一个字符需要使用前一个字符的结果(与前一个字符相同)。即当想要对一个规则的结果进行重用时,可以将其封装成一个组,用()完成。
2)封装成组后就存在一个自动的编号从1开始。可以通过\的形式反向引用组。
\n 捕获组。想要使用组可以通过\n的形式获取(n就是组的编号)。
3)捕获组时在字符串中需要使用\\表示\。
4)多个组出现时,如:((())()),有几个组就看有几个左括号,第一个(是第一个组,第二个(就是第二个组。
5)虽然组的操作都比较简单,底层已经完成。但是阅读性极差。
6)获取前一个规则中的组,$n(表示获取前一个规则中第n组中的字符)。如:"(.)\\1+","$1"第一个规则表示叠词,第二个规则表示获取前一个规则第1个组中的字符。
第二部分:正则表示式操作
一、匹配
String类中:
boolean matches(String regex)
告知此字符串是否匹配给定的正则表达式(拿一个规则匹配整个字符串,某一个位置不符合规则,校验结束,返回false)
示例代码:
二、切割:
String类中:
String[] split(String regex) 根据给定正则表达式的匹配拆分此字符串
示例代码:
三、替换
String类中:
String replaceAll(String regex, String replacement)
使用给定的 replacement 替换此字符串所有匹配给定的正则表达式的子字符串
String replaceFirst(String regex, String replacement)
使用给定的 replacement 替换此字符串匹配给定的正则表达式的第一个子字符串
示例代码:
运行结果:
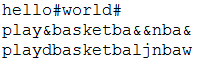
四、获取
1、 操作步骤:
1)将正则表达式封装成对象
2)让正则对象和要操作的字符串相关联
3)关联后,获取正则匹配引擎
4)通过引擎对符合规则的子串进行操作,比如取出
2、Pattern类(java.util.regex)
正则表达式的编译表示形式。
CharSequence:接口,字符序列。String的父类。
常用方法:
static Pattern compile(String regex) 将给定的正则表达式编译到模式中 (将规则封装成对象)
Matcher matcher(CharSequence input) 创建匹配给定输入与此模式的匹配器(获取匹配对象)
3、Matcher类(java.util.regex)
匹配器。通过解释 Pattern 对 character sequence 执行匹配操作的引擎。
常用方法:
boolean find() 尝试查找与该模式匹配的输入序列的下一个子序列
String group() 返回由以前匹配操作所匹配的输入子序列(获取匹配后的结果)
boolean matches()
尝试将整个区域与模式匹配。String类中的matches方法(replaceAll)是用的Pattern与Matcher类实现的
int start() 返回以前匹配的初始索引
int end() 返回最后匹配字符之后的偏移量
示例代码:

图解:

注意:
1)同一个匹配器对象使用的是同一个索引。如在对匹配器进行matches操作后,指针在匹配后的结果处,接着使用find方法会从当前位置开始往下查找。
2)获取类似于集合中的迭代器。
3)String类中替换、切割、匹配方法都是通过Pattern类与Matcher类实现的。
4)切割是获取规则以外的子串,获取是获取符合规则的子串。
五、总结
到底使用匹配、替换、切割与获取中的哪一个功能呢?思路如下:
1、如果想知道该字符串是否对与错,使用匹配。
2、想要将已有的字符串变成另一个字符串,使用替换。
3、想要按照指定的方式将字符串变成多个字符串,使用切割。(获取规则以外的字符串)
4、想要拿到符合规则需求的字符串,使用获取。(获取符合规则的字符串)
示例代码1:
运行结果:

示例代码2:(匹配邮箱)
六、网页爬虫(蜘蛛)
在互联网中获取符合指定规则的数据。
示例代码:
运行结果:

一、概念
正则表达式:符合一定规则的表达式。
二、作用
专门用于操作字符串。虽然String类中有许多操作字符串的方法,但是这些方法操作起来比较复杂。
对字符串进行操作即便捷、又简单的方式就是正则表达式。
示例:校验QQ号码(传统方法)
package day.day15;
/*
* 对QQ号码进行校验
* 要求:5-15位 0不能开头,只能是数字
*/
public class CheckQQ {
public static void main(String[] args) {
checkQQByParse("12e452354");
}
//第一种方式(使用Sring类中的方法组合完成需求,代码过于复杂)
public static void checqQQ(String qq){
int len = qq.length();
//判断长度
if(len>=5 && len<=15){
//是否0开头
if(!qq.startsWith("0")){
//是否是数字
char[] arr = qq.toCharArray();
boolean flag = true;
for(int x=0;x<arr.length;x++){
if(!(arr[x]>='0' && arr[x]<='9')){
flag = false;
break;
}
}
if(flag){
System.out.println("qq:"+qq);
}else{
System.out.println("出现非法字符");
}
}else{
System.out.println("不可以0开头");
}
}else{
System.out.println("长度错误");
}
}
//第二种方式,转换成数字判断
public static void checkQQByParse(String qq){
int len = qq.length();
if(len>=5 && len<=15){
if(!qq.startsWith("0")){
try{
//直接转换成long型,如果出现字母会抛出数字格式异常(判断字符串是否是纯数字)
Long num = Long.parseLong(qq);
System.out.println("qq::"+qq);
}catch(NumberFormatException e){
System.out.println("出现非法字符...");
}
}else{
System.out.println("不能以0开头");
}
}else{
System.out.println("长度错误");
}
}
}正则表达式校验QQ号码:
package day.day15;
/*
* 通过正则表达式校验QQ号码
* boolean matches(String regex)
告知此字符串是否匹配给定的正则表达式
*/
public class CheckQQNew {
public static void main(String[] args) {
checkQQ("23354245");
}
public static void checkQQ(String qq){
/*
* 第一位:1-9 第二位:是数字就可以,而且出现4-14次
*/
String regex = "[1-9][0-9]{4,14}";
//校验字符串是否符合指定规则
boolean flag = qq.matches(regex);
if(flag){
System.out.println(qq+"...is OK");
}else{
System.out.println("nono.....不合法");
}
}
}三、优缺点
1、优点
正则表达式其实就是在用一些特定的符号表示一些代码操作,简化了书写。如JSP中用一些标签代表Java类可以简化书写。(底层的原理还是方法)
学习正则表达式就是学习这些特殊符号的使用。
2、缺点
符号定义越多,正则越长,阅读性极差。
四、正则表达式的构造摘要(构造与匹配)
1、字符
2、字符类
注意:一个[]只能校验一个字符
3、预定义字符
注意:
1)定义类似\d的规则时,要用\\d表示
2)\f代表换页符;\r代表回车符
3)\w(数字、字母、下划线)可用于校验邮箱名
4、边界匹配器
5、Greedy 数量词
注意:X代表一个规则或字符,如[a-zA-Z]?表示该位是字母,可能出现1次或0次。
6、反斜线、转义和引用
1)在不表示转义构造的任何字母字符前使用反斜线都是错误的;它们是为将来扩展正则表达式语言保留的。可以在非字母字符前使用反斜线,不管该字符是否非转义构造的一部分。
2)在java中\代表转义字符,在使用带有\的符号时,必须转义。
3)“.”在正则表达式中代表任意字符,要用“.”切割则需要转义成\\.才代表字符串中的“.”字符。(“abc
4000
.def”)
4)在正则表达式中\必须是成对出现的。
7、组合捕获
1)在定义规则(正则表达式)时,如果后一个字符需要使用前一个字符的结果(与前一个字符相同)。即当想要对一个规则的结果进行重用时,可以将其封装成一个组,用()完成。
2)封装成组后就存在一个自动的编号从1开始。可以通过\的形式反向引用组。
\n 捕获组。想要使用组可以通过\n的形式获取(n就是组的编号)。
3)捕获组时在字符串中需要使用\\表示\。
4)多个组出现时,如:((())()),有几个组就看有几个左括号,第一个(是第一个组,第二个(就是第二个组。
5)虽然组的操作都比较简单,底层已经完成。但是阅读性极差。
6)获取前一个规则中的组,$n(表示获取前一个规则中第n组中的字符)。如:"(.)\\1+","$1"第一个规则表示叠词,第二个规则表示获取前一个规则第1个组中的字符。
第二部分:正则表示式操作
一、匹配
String类中:
boolean matches(String regex)
告知此字符串是否匹配给定的正则表达式(拿一个规则匹配整个字符串,某一个位置不符合规则,校验结束,返回false)
示例代码:
package day.day15;
/*
* 匹配电话号码:
* 13xxxxx
* 15xxxxx
* 18xxxxx
*/
public class CheckTel {
public static void main(String[] args){
checkTel("18608500129");
}
public static void checkTel(String tel){
//第一位1,第二位3或5或8,其他9位是数字
String regex = "[1][358]\\d{9}";
boolean flag = tel.matches(regex);
System.out.println(flag);
}
}二、切割:
String类中:
String[] split(String regex) 根据给定正则表达式的匹配拆分此字符串
示例代码:
package day.day15;
/*
* 用正则表达式切割字符串("\"在正则表达式中是成对出现的)
* String[] split(String regex) 根据给定正则表达式的匹配拆分此字符串
String[] split(String regex, int limit) 根据匹配给定的正则表达式来拆分此字符串
规则:空格出现一次多多次(多个空格进行切割)String regex = " +";
*/
public class SplitDemo {
public static void main(String[] args){
//1、用.切割
String str1 = "zhangsan.lisi.wangwu";
String regex1 = "\\.";//在正则表达式中代表任意字符,要用.切割则需要转义成\\.才代表字符串中的.字符
splitRegex(str1,regex1);
//2、用空格切割,出现1次或多次
splitRegex("zhangsan lisi wangwu"," +");
//3、用\\切割
String str2 = "c:\\abc\\e\\d";
String regex2 = "\\\\";//两个\转义后代表一个\
splitRegex(str2,regex2);
//4、按叠词切割
//split与matches方法不一样,matches方法捕获到不符合规则的字符就结束,split方法会继续向下匹配
splitRegex("helloguiyangbbbaceccc","(.)\\1+");//叠词出现不定的次数(第一组任意字符、第二个字符与第一组相同,出现1次或多次
}
public static void splitRegex(String str,String regex) {
String[] strs = str.split(regex);
for(String s:strs){
System.out.println(s);
}
}
}三、替换
String类中:
String replaceAll(String regex, String replacement)
使用给定的 replacement 替换此字符串所有匹配给定的正则表达式的子字符串
String replaceFirst(String regex, String replacement)
使用给定的 replacement 替换此字符串匹配给定的正则表达式的第一个子字符串
示例代码:
package day.day15;
/*
* 正则表达式:替换字符串
* 将字符串中的数字信息(电话号码、qq等)替换成#
* String replaceAll(String regex, String replacement)
使用给定的 replacement 替换此字符串所有匹配给定的正则表达式的子字符串
*/
public class ReplaceString {
public static void main(String[] args) {
String str = "hello3230928349world345546";
//用#替换符合指定正则表达式(规则)的字符串
replaceAllDemo(str,"\\d{5,}","#");
//将叠词替换成&
replaceAllDemo("playdddbasketballjjjnbawwww","(.)\\1+","&");
//将叠词替换成单个字符,获取前一个组中的字符$
replaceAllDemo("playdddbasketballjjjnbawwww","(.)\\1+","$1");//$1获取前一个规则中的第一个组(在外面获取)
}
public static void replaceAllDemo(String str,String regex,String replaceStr){
str = str.replaceAll(regex,replaceStr);
System.out.println(str);
}
}运行结果:
四、获取
1、 操作步骤:
1)将正则表达式封装成对象
2)让正则对象和要操作的字符串相关联
3)关联后,获取正则匹配引擎
4)通过引擎对符合规则的子串进行操作,比如取出
2、Pattern类(java.util.regex)
正则表达式的编译表示形式。
CharSequence:接口,字符序列。String的父类。
常用方法:
static Pattern compile(String regex) 将给定的正则表达式编译到模式中 (将规则封装成对象)
Matcher matcher(CharSequence input) 创建匹配给定输入与此模式的匹配器(获取匹配对象)
3、Matcher类(java.util.regex)
匹配器。通过解释 Pattern 对 character sequence 执行匹配操作的引擎。
常用方法:
boolean find() 尝试查找与该模式匹配的输入序列的下一个子序列
String group() 返回由以前匹配操作所匹配的输入子序列(获取匹配后的结果)
boolean matches()
尝试将整个区域与模式匹配。String类中的matches方法(replaceAll)是用的Pattern与Matcher类实现的
int start() 返回以前匹配的初始索引
int end() 返回最后匹配字符之后的偏移量
示例代码:
package day.day15;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/*
* 正则表达式:获取(按指定规则获取子串)
* 将字符串中符合规则的子串取出
*
* 匹配、切割、替换都只能按照规则去操作字符串
*
* 操作步骤:
* 1、将正则表达式封装成对象
* 2、让正则对象和要操作的字符串相关联
* 3、关联后,获取正则匹配引擎
* 4、通过对引擎符合规则的子串进行操作,比如取出。
*/
public class GetString {
public static void main(String[] args) {
getDemo();
}
public static void getDemo(){
String str = "ming tian yao fang jia le ,da jia";
String regex = "\\b[a-z]{4}\\b";// \b代表单词边界
//将规则封装成对象(无构造函数,静态方法返回本类对象)
Pattern p = Pattern.compile(regex);
//让正则对象与要作用的字符串相关联。获取匹配器对象(并没有进行匹配操作)
Matcher m = p.matcher(str);
//匹配后不满足规则(4个字母单词)返回假,但是匹配器已经走到tian的t上(索引位置在改变),用find从新的索引位开始查找(同一匹配器使用同一指针)
System.out.println("matches:"+m.matches());
//find方法匹配一次,matches方法是整个匹配
while(m.find()){//将规则作用域字符串上并进行符合规则的子串查找
System.out.println(m.group());//用于获取匹配后的结果
System.out.println(m.start()+"..."+m.end());//符合规则的字符串的头角标与尾角标(不含尾)(索引位)
//切割字符串就是将start→end之间的部分去掉,获取就只取start→end
}
//System.out.println(m.matches());//String类中的matches方法,用的就是Pattern和Matcher对象完成的
}
}运行结果:图解:
注意:
1)同一个匹配器对象使用的是同一个索引。如在对匹配器进行matches操作后,指针在匹配后的结果处,接着使用find方法会从当前位置开始往下查找。
2)获取类似于集合中的迭代器。
3)String类中替换、切割、匹配方法都是通过Pattern类与Matcher类实现的。
4)切割是获取规则以外的子串,获取是获取符合规则的子串。
五、总结
到底使用匹配、替换、切割与获取中的哪一个功能呢?思路如下:
1、如果想知道该字符串是否对与错,使用匹配。
2、想要将已有的字符串变成另一个字符串,使用替换。
3、想要按照指定的方式将字符串变成多个字符串,使用切割。(获取规则以外的字符串)
4、想要拿到符合规则需求的字符串,使用获取。(获取符合规则的字符串)
示例代码1:
package day.day15;
import java.util.TreeSet;
/*
* 正则表达式练习
*/
public class RegexDemo {
public static void main(String[] args) {
test_1();
test_2();
}
/*
* 需求:将下列字符串转换成 我要学编程
* 思路:将已有的字符串变成另一个字符串。使用 替换 功能
* 1、可以先去掉.
* 2、去掉重复字符
*
*/
public static void test_1(){
String str = "我我...我我...我要..要要..要要...学学学...编编编...程程.程...程.....程";
str = str.replaceAll("\\.+", "");//去掉.
//第一个字符与第二个字符相同(或者...第n个),用第一个字符替代
str = str.replaceAll("(.)\\1+", "$1");//去掉重复的字只保留一个
System.out.println(str);
}
/*
* 192.68.1.254 102.49.34.013 10.10.10.10 2.2.2.2 8.109.90.30
* 将IP地址进行地址段顺序的排序
*
* 思路:按照字符串的自然顺序,只有它们每一段都是3位即可
* 1、按照每一段需要的最多的0补齐,那么每一段就会至少有3位
* 2、将每一段只保留3位
*/
public static void test_2(){
String ip ="192.68.1.254 102.49.34.013 10.10.10.10 2.2.2.2 8.109.90.30";
//给
a8a4
每个数字都补两个 0
ip = ip.replaceAll("(\\d+)", "00$1");
//每一个数字只保留3位(后3位封装成一个组)
ip = ip.replaceAll("0*(\\d{3})", "$1");
//切割
String[] ips = ip.split(" +");
//进行自然顺序的比较(可以通过集合,先存入集合)
TreeSet<String> set = new TreeSet<String>();//有重复元素则采用Arrays.sort方法
for(String str:ips){
set.add(str);
}
//对集合进行遍历
for(String s:set){
//去除前面多余的0并输出
System.out.println(s.replaceAll("0*(\\d+)", "$1"));
}
}
}运行结果:
示例代码2:(匹配邮箱)
package day.day15;
/*
* 需求:匹配邮箱
*/
public class MailMatches {
public static void main(String[] args) {
String mail = "abc132@qq.com";
//较为精确的匹配
String regex = "[a-zA-Z_0-9]+@[a-zA-Z0-9]+(\\.[a-zA-Z]+){1,3}";//将.com封装成一个组
//相对不大精确的匹配
regex = "\\w+@\\w+(\\.\\w+){1,3}";
boolean flag = mail.matches(regex);
System.out.println(flag);
}
}六、网页爬虫(蜘蛛)
在互联网中获取符合指定规则的数据。
示例代码:
package day.day15;
/*
* 网页爬虫:获取网页中的指定信息(如获取某一个指定网页中的邮箱)
*/
import java.io.*;
import java.util.regex.*;
import java.net.*;
public class HtmlRegex {
public static void main(String[] args) throws Exception{
netMail();
}
//获取某一个网页中的邮箱
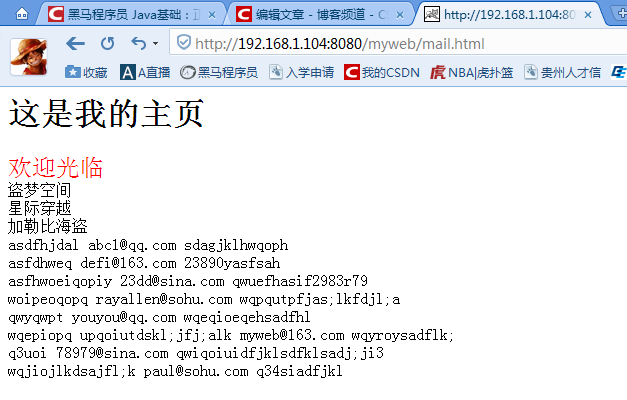
public static void netMail() throws Exception{
//获取资源定位符对象
URL url = new URL("http://192.168.1.104:8080/myweb/mail.html");
//获取连接对象
URLConnection conn = url.openConnection();
BufferedReader bufr =
new BufferedReader(new InputStreamReader(conn.getInputStream()));
String line = null;
//定义邮箱的正则表达式
String regex = "\\w+@\\w+(\\w+){1,3}";
//获取正则对象
Pattern p = Pattern.compile(regex);
//读取网页文件中的数据
while((line=bufr.readLine())!=null){
//获取正则匹配器
Matcher m = p.matcher(line);
//通过匹配器中的方法获取数据
while(m.find()){
System.out.println(m.group());
}
}
}
//获取硬盘中的邮箱
public static void showMail() throws Exception{
BufferedReader bufr =
new BufferedReader(new FileReader("mail.txt"));
String line = null;
//定义邮箱的正则表达式
String regex = "\\w+@\\w+(\\w+){1,3}";
//获取正则对象
Pattern p = Pattern.compile(regex);
//读取硬盘文件中的数据
while((line=bufr.readLine())!=null){
//获取正则匹配器
Matcher m = p.matcher(line);
//通过匹配器中的方法获取数据
while(m.find()){
System.out.println(m.group());
}
}
}
}运行结果:

相关文章推荐
- 黑马程序员——java基础之正则表达式
- Java基础之一组有用的类——使用正则表达式搜索子字符串(TryRegex)
- 黑马程序员-Java语言基础–正则表达式 第25天
- 黑马程序员——Java语言基础——09.正则表达式
- Java语言基础-反射机制、正则表达式
- Java基础巩固--正则表达式
- 黑马程序员——java基础——正则表达式
- Java基础学习总结(35)——Java正则表达式详解
- Java正则表达式基础入门知识
- 【JAVA基础】正则表达式
- Java基础知识强化73:正则表达式之分割功能
- 黑马程序员-->Java基础-->正则表达式
- java基础11:正则表达式与反射
- java基础--正则表达式
- [原]java专业程序代写(qq:928900200),学习笔记之基础入门<正则表达式>(三十一)
- Java--正则表达式基础入门(一)
- Java基础-14总结正则表达式,Pattern,Mactcher,Math,BigInteger,BigDeximal,System等
- 黑马程序员__JAVA基础__正则表达式
- Java基础高级一(正则表达式)
- 黑马程序员_java基础之正则表达式及API(StringBuffer和其它常用类)