MongoDB的分片集群配置
2015-04-29 17:59
381 查看
1、分片
概念:在Mongodb里面存在另一种集群,就是分片技术,可以满足MongoDB数据量大量增长的需求。当MongoDB存储海量的数据时,一台机器可能不足以存储数据也足以提供可接受的读写吞吐量。这时,我们就可以通过在多台机器上分割数据,使得数据库系统能存储和处理更多的数据。
1.分片简介
分片是指将数据拆分,将其分散存在不同机器上的过程.有时也叫分区.将数据分散在不同的机器上,不需要功能
强大的大型计算机就可以存储更多的数据,处理更大的负载.
使用几乎所有数据库软件都能进行手动分片,应用需要维护与若干不同数据库服务器的连接,每个连接还是完全
独立的.应用程序管理不同服务器上的不同数据,存储查村都需要在正确的服务器上进行.这种方法可以很好的工作,但是也
难以维护,比如向集群添加节点或从集群删除节点都很困难,调整数据分布和负载模式也不轻松.
MongoDB支持自动分片,可以摆脱手动分片的管理.集群自动切分数据,做负载均衡.
2.MongoDB的自动分片
MongoDB分片的基本思想就是将集合切分成小块.这些块分散到若干片里面,每个片只负责总数据的一部分.应用程序不必知道
哪片对应哪些数据,甚至不需要知道数据已经被拆分了,所以在分片之前要运行一个路由进程,进程名mongos,这个路由器知道
所有数据的存放位置,所以应用可以连接它来正常发送请求.对应用来说,它仅知道连接了一个普通的mongod.路由器知道和片的
对应关系,能够转发请求到正确的片上.如果请求有了回应,路由器将其收集起来回送给应用.
在没有分片的时候,客户端连接mongod进程,分片时客户端会连接mongos进程.mongos对应用隐藏了分片的细节.
从应用的角度看,分片和不分片没有区别.所以需要扩展的时候,不必修改应用程序的代码.
什么时候需要分片:
a.机器的磁盘不够用了
b.单个mongod已经不能满足些数据的性能需要了
c.想将大量数据放在内存中提高性能
一般来说,先要从不分片开始,然后在需要的时候将其转换成分片.
3.片键
设置分片时,需要从集合里面选一个键,用该键的值作为数据拆分的依据.这个键成为片键.
假设有个文档集合表示的是人员,如果选择名字"name"做为片键,第一篇可能会存放名字以A-F开头的文档.
第二片存G-P开头的文档,第三篇存Q-Z的文档.随着增加或删除片,MongoDB会重新平衡数据,是每片的流量比较
均衡,数据量也在合理范围内(如流量较大的片存放的数据或许会比流量下的片数据要少些)
4.将已有的集合分片
假设有个存储日志的集合,现在要分片.我们开启分片功能,然后告诉MongoDB用"timestamp"作为片键,就要所有数据放到
了一个片上.可以随意插入数据,但总会是在一个片上.
然后,新增一个片.这个片建好并运行了以后,MongoDB就会把集合拆分成两半,成为块.每个块中包含片键值在一定
范围内的所有文档,假设其中一块包含时间戳在2011.11.11前的文档,则另一块含有2011.11.11以后的文档.其中
一块会被移动到新片上.如果新文档的时间戳在2011.11.11之前,则添加到第一块,否则添加到第二块.
5.递增片键还是随机片键
片键的选择决定了插入操作在片之间的分布.
如果选择了像"timestamp"这样的键,这个值可能不断增长,而且没有太大的间断,就会将所有数据发送到一个片上
(含有2011.11.11以后日期的那片).如果有添加了新片,再拆分数据,还是会都导入到一台服务器上.添加了新片,
MongoDB肯能会将2011.11.11以后的拆分成2011.11.11-2021.11.11.如果文档的时间大于2021.11.11以后,
所有的文档还会以最后一片插入.这就不适合写入负载很高情况,但按照片键查询会非常高效.
如果写入负载比较高,想均匀分散负载到各个片,就得选择分布均匀的片键.日志例子中时间戳的散列值,没有模式的"logMessage"
都是复合这个条件的.
不论片键随机跳跃还是稳定增加,片键的变化很重要.如,如果有个"logLevel"键的值只有3种值"DEBUG","WARN","ERROR",
MongoDB无论如何也不能把它作为片键将数据分成多于3片(因为只有3个值).如果键的变化太少,但又想让其作为片键,
可以把这个键与一个变化较大的键组合起来,创建一个复合片键,如"logLevel"和"timestamp"组合.
选择片键并创建片键很像索引,以为二者原理相似.事实上,片键也是最常用的索引.
6.片键对操作的影响
最终用户应该无法区分是否分片,但是要了解选择不同片键情况下的查询有何不同.
假设还是那个表示人员的集合,按照"name"分片,有3个片,其名字首字母的范围是A-Z.下面以不同的方式查询:
db.people.find({"name":"Refactor"})
mongos会将这个查询直接发送给Q-Z片,获得响应后,直接转发给客户端
db.people.find({"name":{"$lt":"L"}})
mongos会将其先发送给A-F和G-P片,然后将结果转发给客户端.
db.people.find().sort({"email":1})
mongos会在所有片上查询,返回结果时还会做归并排序,确保结果顺序正确.
mongos用游标从各个服务器上获取数据,所以不必等到全部数据都拿到才向客户端发送批量结果.
db.people.find({"email":"refactor@msn.cn"})
mongos并不追踪"email"键,所以也不知道应该将查询发给那个片.所以他就向所有片顺序发送查询.
如果是插入文档,mongos会依据"name"键的值,将其发送到相应的片上.2.如何分片?
1.建立分片
建立分片有两步:启动实际的服务器,然后决定怎么切分数据.
分片一般会有3个组成部分:
a.片
片就是保存子集合数据的容器,片可是单个的mongod服务器(开发和测试用),也可以是副本集(生产用).所以一片
有多台服务器,也只能有一个主服务器,其他的服务器保存相同的数据.
b.mongos
mongos就是MongoDB配的路由器进程.它路由所有的请求,然后将结果聚合.它本身并不存储数据或者配置信息
但会缓存配置服务器的信息.
c.配置服务器
配置服务器存储了集群的配置信息:数据和片的对应关系.mongos不永久存房数据,所以需要个地方存放分片的配置.
它会从配置服务器获取同步数据.
8.启动服务器
首先要启动配置服务器和mongos.配置服务器需要先启动.因为mongos会用到其上的配置信息.
配置服务器的启动就像普通的mongod一样
mongod --dbpath "F:\mongo\dbs\config" --port 20000 --logpath "F:\mongo\logs\config\MongoDB.txt" --rest
配置服务器不需要很多的空间和资源(200M实际数据大约占用1kB的配置空间)
建立mongos进程,一共应用程序连接.这种路由服务器连接数据目录都不需要,但一定要指明配置服务器的位置:
mongos --port 30000 --configdb 127.0.0.1:20000 --logpath "F:\mongo\logs\mongos\MongoDB.txt"
分片管理通常是通过mongos完成的.
添加片
片就是普通的mongod实例(或副本集)
mongod --dbpath "F:\mongo\dbs\shard" --port 10000 --logpath "F:\mongo\logs\shard\MongoDB.txt" --rest
mongod --dbpath "F:\mongo\dbs\shard1" --port 10001 --logpath "F:\mongo\logs\shard1\MongoDB.txt" --rest
连接刚才启动的mongos,为集群添加一个片.启动shell,连接mongos:
确定连接的是mongos而不是mongod,通过addshard命令添加片:
>mongo 127.0.0.1:30000
mongos> db.runCommand(
... {
... "addshard":"127.0.0.1:10000",
... "allowLocal":true
... }
... )
Sat Jul 21 10:46:38 uncaught exception: error { "$err" : "can't find a shard to
put new db on", "code" : 10185 }
mongos> use admin
switched to db admin
mongos> db.runCommand(
... {
... "addshard":"127.0.0.1:10000",
... "allowLocal":1
... }
... )
{ "shardAdded" : "shard0000", "ok" : 1 }
mongos> db.runCommand(
... {
... "addshard":"127.0.0.1:10001",
... "allowLocal":1
... }
... )
{ "shardAdded" : "shard0001", "ok" : 1 }
当在本机运行片的时候,得设定allowLocal键为1.MongoDB尽量避免由于错误的配置,将集群配置到本地,
所以得让它知道这仅仅是开发,而且我们很清楚自己在做什么.如果是生产环境中,则要将其部署在不同的机器上.
想添加片的时候,就运行addshard.MongoDB会负责将片集成到集群.
切分数据 --- 继续在mongos连接上操作
MongoDB不会将存储的每一条数据都直接发布,得先在数据库和集合的级别将分片功能打开.
E:\mongo\bin>db.runCommand({"enablesharding":"test"})//将test数据库启用分片功能.
对数据库分片后,其内部的集合便会存储到不同的片上,同时也是对这些集合分片的前置条件.
在数据库级别启用了分片以后,就可以使用shardcollection命令堆积和进行分片:
db.runCommand({"shardcollection":"test.refactor","key":{"name":1}})//对test数据库的refactor集合进行分片,片键是name
如果现在对refactor集合添加数据,就会依据"name"的值自动分散到各个片上.3.操作示例:
1.启动配置服务器D:\mongodb\mongo1\bin>mongod --dbpath=D:\mongodb\mongo1\config --port 20000 --logpath=D:\mongodb\mongo1\logs\config\MongoDB.txt --rest

2.MongoDB配置的路由器进程服务器 -- 分片管理通常是通过mongos完成的.
D:\mongodb\mongo1\bin>mongos --port 3000 --configdb 127.0.0.1:20000 --logpath=D:\mongodb\mongo1\logs\mongos\MongoDB.txt

3.建立分片,即普通的mongod实例
分片1:
D:\mongodb\mongo1\bin>mongod --port 10000 --dbpath=D:\mongodb\mongo1\db1 --logpath=D:\mongodb\mongo1 \logs\shard\MongoDB.txt --rest
分片2: D:\mongodb\mongo1\bin>mongod --port 10001 --dbpath=D:\mongodb\mongo1\db2 --logpath=D:\mongodb\mongo1 \logs\shard1\MongoDB.txt --rest

4.连接刚才启动的mongos,为集群添加一个片.启动shell,连接mongos:
D:\mongodb\mongo1\bin>mongos --port 3000 --configdb 127.0.0.1:20000 --logpath=D:\mongodb\mongo1\logs\mongos\MongoDB.txt

关于MongoDB集群
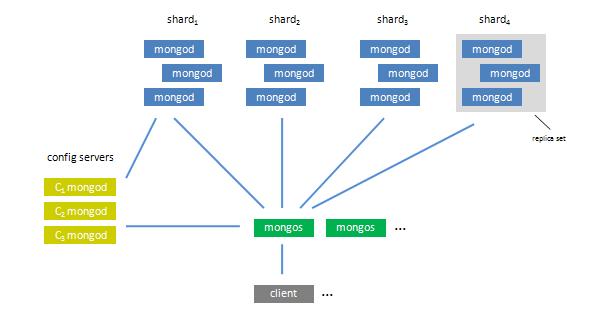
集群由以下3个服务组成:
Shards Server: 每个shard由一个或多个mongod进程组成,用于存储数据
Config Server: 用于存储集群的Metadata信息,包括每个Shard的信息和chunks信息
Route Server: 用于提供路由服务,由Client连接,使整个Cluster看起来像单个DB服务器
另外,Chunks是指MongoDB中一段连续的数据块,默认大小是200M,一个Chunk位于其中一台Shard服务器上
下面,搭建一个Cluster,它由4台服务器组成,包括2个Shard,3个Config,1个Route
其中每个Shard由一个Replica Set组成,每个Replica Set由2个Mongod节点,1个vote节点组成
需要分别建立目录/opt/soft/mongodb/data/data ,/opt/soft/mongodb/log
192.168.11.229
/opt/soft/mongodb/bin/mongod –fork –shardsvr –port 10000 –replSet set1 –dbpath /opt/soft/mongodb/data/data –logpath /opt/soft/mongodb/log/log.log
/opt/soft/mongodb/bin/mongod –fork –shardsvr –port 10001 –replSet set2 –dbpath /opt/soft/mongodb/data/data1 –logpath /opt/soft/mongodb/log/log1.log
192.168.11.17
/usr/local/mongodb/bin/mongod –fork –shardsvr –port 10000 –replSet set1 –dbpath /opt/soft/mongodb/data/data –logpath /pvdata/mongodb_log/mongod.log
192.168.11.227
/usr/local/mongodb/bin/mongod –fork –shardsvr –port 10000 –replSet set2 –dbpath /opt/soft/mongodb/data/data –logpath /opt/soft/mongodb/log/mongod.log
/usr/local/mongodb/bin/mongod –fork –shardsvr –port 10001 –replSet set1 –dbpath /opt/soft/mongodb/data/data1 –logpath /opt/soft/mongodb/log/mongod1.log
192.168.11.228
/usr/local/mongodb/bin/mongod –fork –shardsvr –port 10000 –replSet set2 –dbpath /opt/soft/mongodb/data/data –logpath /opt/soft/mongodb/log/mongod.log
192.168.11.229上mongo –port 10000连接mongo
config = {_id: 'set1', members: [
{_id: 0, host: '192.168.11.229:10000'},
{_id: 1, host: '192.168.11.17:10000'},
{_id: 2, host: '192.168.11.227:10001', arbiterOnly: true}
]}
rs.initiate(config)
rs.status()
192.168.11.227上mongo –port 10000连接mongo
config = {_id: 'set2', members: [
{_id: 0, host: '192.168.11.227:10000'},
{_id: 1, host: '192.168.11.228:10000'},
{_id: 2, host: '192.168.11.229:10001', arbiterOnly: true}
]}
rs.initiate(config)
rs.status()
192.168.11.229:;192.168.11.17;192.168.11.228上启动进程
mongod --configsvr --fork --logpath /opt/soft/mongodb/log/config.log --logappend --dbpath /opt/soft/mongodb/data/configdata --port 20000
192.168.11.227上启动进程
mongos --fork --configdb "192.168.11.229:20000,192.168.11.17:20000,192.168.11.228:20000" --logpath /opt/soft/mongodb/log/mongos.log
192.168.11.227
mongos> use admin
mongos> db.adminCommand({ addShard : "set1/192.168.11229:10000,192.168.11.17:10000"})
mongos> db.adminCommand({ addShard :"set2/192.168.11.227:10000,192.168.11.228:10000"})
mongos> db.adminCommand({enablesharding:'test'})
mongos> db.adminCommand({listshards:1})
mongos> printShardingStatus()
mongos> db.adminCommand({shardcollection:'test.test2', key:{_id:1}, unique : true})
导入文本数据(数据以,号隔开)
mongoimport -h 192.168.11.227 -d test -c test --type csv -f ip,sid,uid,cateid,type --file /opt/dm/meta/uidip_20111017
分片集群
Mongodb中数据分片叫做chunk,它是一个Collection中的一个连续的数据记录,但是它有一个大小限制,不可以超过200M,如果超出产生新的分片。
下面是一个简单的分片集群实例
分片集群的构成:
Shard server:mongod实例,用于存储实际的数据块
Config server:mongod实例,用于存储整个Cluster Metadata,其中包括chunk信息。
Route server:mongos实例,做为整个集群的前端路由,整个集群由此接入。从而让整个集群看着像单一进程数据库。
备注:route做为路由会将请求转发到实际的目标服务进程,并将多个结果合并并回传客户端。在route并不存储任何的数据和状态,所有的信息都是启动的时候从Config server上获取,当Config server上有信息更新,也会同步到route server上。
构建一个简单的集群
集群目录:
总共有四个mongodb,目录分别为/home/scotte.ye/mongo1,mongo2,mongo3,mongo4
其中mongo1,mongo2做为shard server
mongo3做为config server
mongo4做为route server
1、启动Shard server
// 启动shard server 1
$ cd /home/scotte.ye/mongo1
$ ./mongo -shardsvr -port 10000 -dbpath=/home/data/10000/ -fork -logpath=/home/log/10000/null
$ all output going to: /home/log/10000/null
$ fork process: 10657
//启动shard server 2
$ cd /home/scotte.ye/mongo2
$ ./mongo -shardsvr -port 10011 -dbpath=/home/data/10011/ -fork -logpath=/home/log/10011/null
$ all output going to: /home/log/10011/null
$ fork process: 10661
//启动Config server
$ cd /home/scotte.ye/mongo3
$ ./mongo -configsvr -port 20000 -dbpath=/home/data/20000/ -fork -logpath=/home/log/20000/null
$ all output going to: /home/log/20000/null
$ fork process: 10857
//启动Route server
$ cd /home/scotte.ye/mongo4
$ ./mongos -configdb 192.168.35.106:20000 -fork -logpath=/home/log/20000/null
$ all output going to: /home/log/20000/null
$ fork process: 10900
//注在启动Route server的时候,还可以通过-chunksize参数来进行配置分块的大小
2、配置相关
配置相关命令说明:
addshard:添加shard server到集群。相类似的命令还有,listshards和removeshard
enablesharding:用于设置那些数据库可以被分布存储
shardcollection:用于设置具体被分片的集合的名称,且必须指定 share key,系统会自动创建索引
注:shardcollection的集合必须只有一个unique index且必须是shard key
开始配置:
$ cd /home/scotte.ye/mongo3/bin
$ ./mongo
$ >use admin
$#只有在admin数据库才可以操作
$ switched to db admin
$ >db.runCommand({addshard:'192.168.35.106:10000'})
$ {"shardAdded":"shard0000","OK":1}
$ >db.runCommand({addshard:'192.168.35.106:10011'})
$ {"shardAdded":"shard0001","OK":1}
$#添加相应到shard server到shard cluster
$ >db.runCommand({enablesharding:'test'})
$#使相应的数据库表test可以分布存储,test可以更换成相应的其它数据库名字
$ >db.runCommand({sahrdcollection:'test.user',key:{_id:1}})
$ {"OK":1}
$#指明相应的集合和shard key
$ {"collectionsharded":"test.user","OK":1}
3、常用的状态查询命令
printShardingStatus():查看Sharding信息
db.<collection_name>.stats():查看具体shard存储信息
isdbgrid:用于确认当前是否是sharding cluster
ismaster:判断是不是master

相关文章推荐
- 【mongoDB】测试使用gridfs,配置一个分片服务器集群
- 配置MongoDB3.04集群分片
- mongoDB分片集群配置详解
- 配置MongoDB集群分片
- mongodb高可用配置之分片集群
- 配置MongoDB集群分片
- MongoDB的分片集群基本配置教程
- MongoDB 集群分片配置
- mongodb单机配置shard分片集群
- MongoDB 主从+分片集群配置
- MongoDB的分片集群基本配置教程
- 配置MongoDB集群分片
- springboot和mongoDB分片配置 集群配置
- MongoDB 3.05集群分片配置
- 配置MongoDB集群分片
- 配置MongoDB3.04集群分片
- MongoDB 双机集群配置与管理
- 搭建高可用mongodb集群(一)——mongodb配置主从模式
- mongodb模拟生产环境的分片集群
- mongodb sharding cluster(分片集群)