应用于文本分类问题的TF-IDF改进方法
2015-03-03 19:52
253 查看
应用于文本分类问题的TF-IDF改进方法
一、传统意义上的TF-IDF(以下内容摘自维基百科)
TF-IDF是一种统计方法,用以评估某一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了TF-IDF以外,因特网上的搜索引擎还会使用基于链接分析的评级方法,以确定文件在搜寻结果中出现的顺序。
TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TF-IDF实际上是:TF
* IDF,TF词频(Term Frequency),IDF逆向文件频率(Inverse
Document Frequency)。TF表示词条在文档d中出现的频率。IDF的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。
在一份给定的文件里,词频(term frequency,TF)指的是某一个给定的词语在该文件中出现的频率。这个数字是对词数(term
count)的归一化,以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词数,而不管该词语重要与否。)对于在某一特定文件里的词语
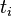
来说,它的重要性可表示为:
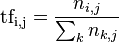
以上式子中
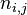
是该词在文件
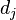
中的出现次数,而分母则是在文件
中所有字词的出现次数之和。
逆向文件频率(inverse documentfrequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到:
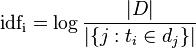
其中
|D|:语料库中的文件总数
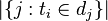
:包含词语
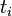
的文件数目(即
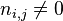
的文件数目)如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用
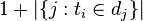
然后
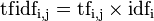
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
二、传统TF-IDF的不足
对于传统的TF-IDF而言,可以计算出在一文档集合中特定文档里所包含的区别于其他文档的重要词语,换言之就是关键词。而在文本分类问题中,仅仅是每篇文档区分度强的关键词还不足以作为分类的评判标准,即传统的TF-IDF还存在许多不足,在查阅了很多相关论文后我列举了以下一些传统TF-IDF的不足之处如下:
1、没有考虑特征词的位置因素对文本的区分度,词条出现在文档的不同位置时,对区分度的贡献大小是不一样的。
2、按照传统TF-IDF函数标准,往往一些生僻词的IDF(反文档频率)会比较高、因此这些生僻词常会被误认为是文档关键词。(换句话说,如果一个特征项只在某一个类别中的个别文本中大量出现,在类内的其他大部分文本中出现的很少,那么不排除这些个别文本是这个类中的特例情况,因此这样的特征项不具有代表性。)
3、传统TF-IDF函数中的IDF部分只考虑了特征词与它出现的文本数之间的关系,而忽略了特征项在一个类别中不同的类别间的分布情况。
4、对于文档中出现次数较少的重要人名、地名信息提取效果不佳。
三、TF-IDF的改进
1、TF部分的改进
这里考虑将文档内的词频率更改为同一类文档内的词频率可以在一定程度上解决上面提到的第2项不足之处。
2、IDF部分的改进
传统的IDF通常可以写作:IDF=log(总文档数N/所有含特征词文档数n+0.01)
在我查阅的所有论文中都提到了上面的第3项不足,这是TF-IDF应用于分类问题上的一个很明显的不足,针对这个不足,这些论文中也提到了不同的解决方法:
①IDF=log(本类含特征词文档数m*总文档数N/所有含特征词文档数n+0.01)
②用P(Mk)表示特征词Mk在当前类别中的频率,P(Mk)’表示特征词Mk在其他类别中的频率,对IDF计算改进如下:

用一个例子来简单计算一下:

以表1为例,有C1,C2两个类,C1类中有14篇文档,C2类中有6篇文档,共计20篇文档,m1,m2为两个特征值词。在C1,C2中包含m1,m2特征词的文档数分别为9篇、5篇、1篇、5篇。根据传统的IDF计算方法,m1,m2在类C1,C2中IDF值分别为IDF1,IDF2,则IDF1=IDF2=log(20/10+0.01),两者之间无法判断哪个词更易于区分类别,而根据实际观察m1分布不均匀而m2分布很均匀,表明m1比m2具有更好的类别区分能力。
根据改进方法①,IDF1=log(9*20/10+0.01)=1.2555,IDF2=log(5*20/10+0.01)=1.0004
根据改进方法②,IDF1=log(1+(9/14)/(1/6))=0.552,IDF2=log(1+(5/14)/(5/6))=0.155
不难看出用传统IDF无法判断而实际又有很好区分能力的特征词在使用2种改进方法后均可以找出区分能力更强的特征词,但这两种改进方法到底哪一个比较好我暂时还没得出明确结果,还需要用实际的训练测试集进行分类测试再来判定。
四、改进后应用在分类中的测试
目前的测试看来IDF的两种改进方法差别还不是很明显,但TF-IDF的改进较传统的TF-IDF而言确实有很大提升,当然根据之前列举的不足还有很多可以改进的地方,至于使用IDF改进方法1还是IDF改进方法2还需要进一步的测试,目前我也还在进行这方面的实验,结合分类算法对2种改进方法进行测试,目前因为预处理的问题和脏数据的存在所以还在进行中,得出结论后我会再来更新比较一下这两种改进方法,现在就先总结到这里吧。
参考文档:
1、基于改进TF_IDF的文本信息热点话题发现_薛征
2、文本分类中TF_IDF方法的改进研究_覃世安
3、一种基于改进TF_IDF函数的文本分类方法_卢中宁
本文固定链接:http://blog.csdn.net/fyfmfof/article/details/44034401转载请注明出处
一、传统意义上的TF-IDF(以下内容摘自维基百科)
TF-IDF是一种统计方法,用以评估某一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了TF-IDF以外,因特网上的搜索引擎还会使用基于链接分析的评级方法,以确定文件在搜寻结果中出现的顺序。
TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TF-IDF实际上是:TF
* IDF,TF词频(Term Frequency),IDF逆向文件频率(Inverse
Document Frequency)。TF表示词条在文档d中出现的频率。IDF的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。
在一份给定的文件里,词频(term frequency,TF)指的是某一个给定的词语在该文件中出现的频率。这个数字是对词数(term
count)的归一化,以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词数,而不管该词语重要与否。)对于在某一特定文件里的词语
来说,它的重要性可表示为:
以上式子中
是该词在文件
中的出现次数,而分母则是在文件
中所有字词的出现次数之和。
逆向文件频率(inverse documentfrequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到:
其中
|D|:语料库中的文件总数
:包含词语
的文件数目(即
的文件数目)如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用
然后
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
二、传统TF-IDF的不足
对于传统的TF-IDF而言,可以计算出在一文档集合中特定文档里所包含的区别于其他文档的重要词语,换言之就是关键词。而在文本分类问题中,仅仅是每篇文档区分度强的关键词还不足以作为分类的评判标准,即传统的TF-IDF还存在许多不足,在查阅了很多相关论文后我列举了以下一些传统TF-IDF的不足之处如下:
1、没有考虑特征词的位置因素对文本的区分度,词条出现在文档的不同位置时,对区分度的贡献大小是不一样的。
2、按照传统TF-IDF函数标准,往往一些生僻词的IDF(反文档频率)会比较高、因此这些生僻词常会被误认为是文档关键词。(换句话说,如果一个特征项只在某一个类别中的个别文本中大量出现,在类内的其他大部分文本中出现的很少,那么不排除这些个别文本是这个类中的特例情况,因此这样的特征项不具有代表性。)
3、传统TF-IDF函数中的IDF部分只考虑了特征词与它出现的文本数之间的关系,而忽略了特征项在一个类别中不同的类别间的分布情况。
4、对于文档中出现次数较少的重要人名、地名信息提取效果不佳。
三、TF-IDF的改进
1、TF部分的改进
这里考虑将文档内的词频率更改为同一类文档内的词频率可以在一定程度上解决上面提到的第2项不足之处。
2、IDF部分的改进
传统的IDF通常可以写作:IDF=log(总文档数N/所有含特征词文档数n+0.01)
在我查阅的所有论文中都提到了上面的第3项不足,这是TF-IDF应用于分类问题上的一个很明显的不足,针对这个不足,这些论文中也提到了不同的解决方法:
①IDF=log(本类含特征词文档数m*总文档数N/所有含特征词文档数n+0.01)
②用P(Mk)表示特征词Mk在当前类别中的频率,P(Mk)’表示特征词Mk在其他类别中的频率,对IDF计算改进如下:
用一个例子来简单计算一下:
以表1为例,有C1,C2两个类,C1类中有14篇文档,C2类中有6篇文档,共计20篇文档,m1,m2为两个特征值词。在C1,C2中包含m1,m2特征词的文档数分别为9篇、5篇、1篇、5篇。根据传统的IDF计算方法,m1,m2在类C1,C2中IDF值分别为IDF1,IDF2,则IDF1=IDF2=log(20/10+0.01),两者之间无法判断哪个词更易于区分类别,而根据实际观察m1分布不均匀而m2分布很均匀,表明m1比m2具有更好的类别区分能力。
根据改进方法①,IDF1=log(9*20/10+0.01)=1.2555,IDF2=log(5*20/10+0.01)=1.0004
根据改进方法②,IDF1=log(1+(9/14)/(1/6))=0.552,IDF2=log(1+(5/14)/(5/6))=0.155
不难看出用传统IDF无法判断而实际又有很好区分能力的特征词在使用2种改进方法后均可以找出区分能力更强的特征词,但这两种改进方法到底哪一个比较好我暂时还没得出明确结果,还需要用实际的训练测试集进行分类测试再来判定。
四、改进后应用在分类中的测试
目前的测试看来IDF的两种改进方法差别还不是很明显,但TF-IDF的改进较传统的TF-IDF而言确实有很大提升,当然根据之前列举的不足还有很多可以改进的地方,至于使用IDF改进方法1还是IDF改进方法2还需要进一步的测试,目前我也还在进行这方面的实验,结合分类算法对2种改进方法进行测试,目前因为预处理的问题和脏数据的存在所以还在进行中,得出结论后我会再来更新比较一下这两种改进方法,现在就先总结到这里吧。
参考文档:
1、基于改进TF_IDF的文本信息热点话题发现_薛征
2、文本分类中TF_IDF方法的改进研究_覃世安
3、一种基于改进TF_IDF函数的文本分类方法_卢中宁
本文固定链接:http://blog.csdn.net/fyfmfof/article/details/44034401转载请注明出处

相关文章推荐
- 文本分类tf-idf地址搜藏
- python中对不CountVectorizer与TfidfVectorizer,去停用词,对文本特征量化结合Bayes算法进行分类,可视化分析
- 文本特征抽取的向量空间模型(VSM)和TF/IDF方法
- 文本挖掘——基于TF-IDF的KNN分类算法实现
- 资讯的文本分类用lucene——TFIDF
- 《Spark机器学习》笔记——Spark高级文本处理技术(NLP、特征哈希、TF-IDF、朴素贝叶斯多分类、Word2Vec)
- 文本特征值提取,采用结巴将文本分词,tf-idf算法得到特征值,以及给出了idf词频文件的训练方法
- 【思考】tf/idf之于文本分类
- 中文文本分类--TF-IDF--朴素贝叶斯-01
- 数学之美 系列十八 - 矩阵运算和文本处理中的分类问题
- 数学之美 系列十八 - 矩阵运算和文本处理中的分类问题
- 文本分类入门(九)文本分类问题的分类
- asp.net 数据绑定 使用eval 时候报 字符文本中的字符太多 问题的解决方法
- c# 疑难(一)之打开“OpenFileDialog”文本对话框后默认路径改变问题和解决方法
- 数学之美 系列十八 - 矩阵运算和文本处理中的分类问题
- 文本分类入门(十一)特征选择方法之信息增益
- 文本分类入门(一)文本分类问题的定义
- 文本自动分类方法介绍
- 从文本分类问题中的特征词选择算法追踪如何将数学知识,数学理论迁移到实际工程中去
- 数学之美 系列十八 - 矩阵运算和文本处理中的分类问题