oracle编程入门笔记2015-01-25--浅说cube
2015-01-25 16:14
691 查看
有一次因为一个业务需求。查找客户进九十天的订单金额总和,近九十天最后一次订单生成时间以及总订单数,具体sql代码如下,由于业务场景以及表结构关系不能详述,所以代码片段只做感官认识。
select fcustid, dd, income, amount, mindd, num
from (select fcustid,
dd,
income,
amount,
mindd,
row_number() over(partition by fcustid order by dd desc) num
from (SELECT fcustid,
dd, --
SUM(income) income,
count(1) amount,
min(dd) mindd
FROM (SELECT cly1.fcustid, --订单数据
trunc(cly1.fanalyseday) dd,
sum(farrivedaount + ffprepayamount -
fagentreceivepay - frefundrabate) income
from DPCRM.t_crm_custanalysebyday cly1,
DPCRM.T_CUST_CUSTBASEDATA cust
--取90天订单数据
where cly1.fanalyseday >= (sysdate - 90 - 1)
and cly1.fanalyseday <= (sysdate - 1)
and cly1.fcustid = cust.fid
AND cust.Fcuststatus = '0'
and cust.FCUSTGROUP = 'RC_CUSTOMER' --固定客户
AND CLY1.FCANALYSETYPE = 1 --客户
group by cly1.fcustid, trunc(cly1.fanalyseday) --一天内多票算一票
) res
GROUP BY rollup(fcustid, dd))) --根据客户编码和订单日期分组
where num <= 2
这里使用的rollup,其实还有一个与之类似的cube。rollup可以说是cube的一种变形以便满足特定业务场景。
下面就来介绍cube
cube和group by连用。可以先根据原始表生成一个一个临时的表,再在临时表的基础上group by。 可以理解cube就是生成临时表的。
下面盗用别人的一个例子给大家说明。原始连接http://blog.itpub.net/519536/viewspace-610997/

例子使用的表以及里面的数据如上所示。现在我想知道相同group人的工资总和和相同job人的工资总和。
下面分析:
相同group 只需要按照group_id分组。
相同job按照job分组。
两个结果union一下。
再使用一列来区分这两个不同的集合。

使用cube,一下子所有需要的信息都有了
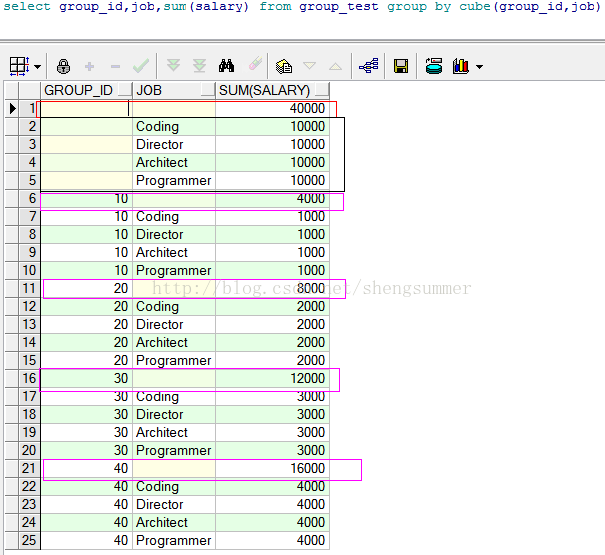
cube可以理解为先按照第一个字段分组,返回结果,再按照后面字段分组,接着按照两个字段同时分组,最后再返回一个统计结果。
下面使用union 和group by 模拟cube。

这就是cube的原理。同理,rollup可以理解为这样。

当然cube还有一个非常好用的grouping函数,可以告诉你,哪些数据行是cube额外生成的。

select fcustid, dd, income, amount, mindd, num
from (select fcustid,
dd,
income,
amount,
mindd,
row_number() over(partition by fcustid order by dd desc) num
from (SELECT fcustid,
dd, --
SUM(income) income,
count(1) amount,
min(dd) mindd
FROM (SELECT cly1.fcustid, --订单数据
trunc(cly1.fanalyseday) dd,
sum(farrivedaount + ffprepayamount -
fagentreceivepay - frefundrabate) income
from DPCRM.t_crm_custanalysebyday cly1,
DPCRM.T_CUST_CUSTBASEDATA cust
--取90天订单数据
where cly1.fanalyseday >= (sysdate - 90 - 1)
and cly1.fanalyseday <= (sysdate - 1)
and cly1.fcustid = cust.fid
AND cust.Fcuststatus = '0'
and cust.FCUSTGROUP = 'RC_CUSTOMER' --固定客户
AND CLY1.FCANALYSETYPE = 1 --客户
group by cly1.fcustid, trunc(cly1.fanalyseday) --一天内多票算一票
) res
GROUP BY rollup(fcustid, dd))) --根据客户编码和订单日期分组
where num <= 2
这里使用的rollup,其实还有一个与之类似的cube。rollup可以说是cube的一种变形以便满足特定业务场景。
下面就来介绍cube
cube和group by连用。可以先根据原始表生成一个一个临时的表,再在临时表的基础上group by。 可以理解cube就是生成临时表的。
下面盗用别人的一个例子给大家说明。原始连接http://blog.itpub.net/519536/viewspace-610997/
例子使用的表以及里面的数据如上所示。现在我想知道相同group人的工资总和和相同job人的工资总和。
下面分析:
相同group 只需要按照group_id分组。
相同job按照job分组。
两个结果union一下。
再使用一列来区分这两个不同的集合。
使用cube,一下子所有需要的信息都有了
cube可以理解为先按照第一个字段分组,返回结果,再按照后面字段分组,接着按照两个字段同时分组,最后再返回一个统计结果。
下面使用union 和group by 模拟cube。
这就是cube的原理。同理,rollup可以理解为这样。
当然cube还有一个非常好用的grouping函数,可以告诉你,哪些数据行是cube额外生成的。

相关文章推荐
- oracle编程入门笔记2015-01-08--查询
- oracle编程入门笔记2015-01-13--数据库原理1之硬解析软解析
- oracle编程入门笔记2015-01-30--model子句性能
- oracle编程入门笔记2015-01-09--插入
- oracle编程入门笔记2015-01-22--解释计划
- oracle编程入门笔记2015-02-05--递归查询
- oracle编程入门笔记2015-01-26--分析函数使用举例
- oracle编程入门笔记2015-01-12--数据合并
- oracle编程入门笔记2015-01-19--表连接
- oracle编程入门笔记2015-01-17--一个例子告诉你共享池和数据缓存对效率的影响
- oracle编程入门笔记2015-01-06--sqlplus
- oracle编程入门笔记2015-01-12--数据库原理1
- oracle编程入门笔记2015-01-18--执行计划中的索引扫描方式说明
- oracle编程入门笔记2015-01-19--index fast full scan
- oracle编程入门笔记2015-01-28--model子句原理
- oracle编程入门笔记2015-01-23--执行计划
- oracle编程入门笔记2015-01-27--分析函数性能
- oracle编程入门笔记2015-01-18--常用oracle查询语句
- oracle编程入门笔记2015-01-14--查询转换
- oracle编程入门笔记2015-01-10--更新,删除