数据库设计 Step by Step
2014-12-24 11:26
190 查看
Step by Step (1)
引言:一直在从事数据库开发和设计工作,也看了一些书籍,算是略有心得。很久之前就想针对关系数据库设计进行整理、总结,但因为种种原因迟迟没有动手,主要还是惰性使然。今天也算是痛下决心开始这项卓绝又令我兴奋的工作。这将是一个系列的文章,我将以讲座式的口吻展开讨论(个人偷懒,这里的总结直接拿去公司培训新人用)。系列的第一讲我们先来回答下面几个问题

数据库是大楼的根基
大多数程序员都很急切,在了解基本需求之后希望很快的进入到编码阶段(可能只有产出代码才能反映工作量),对于数据库设计思考得比较少。
这给系统留下了许多隐患。许多软件系统的问题,如:输出错误的数据,性能差或后期维护繁杂等,都与前期数据库设计有着密切的关系。到了这个时候再想修改数据库设计或进行优化等同于推翻重来。
我经常把软件开发比作汽车制造。汽车制造会经过图纸设计,模型制作,样车制造,小批量试生产,最后是批量生产等步骤。整个过程环环相扣,后一过程是建立在前一过程正确的前提基础之上的。如果在图纸设计阶段发现了一个纰漏,我们可以重新进行图纸设计,如果到了样车制造阶段发现这个错误,那么我们就要把从图纸设计到样车制造的阶段重来,越到后面发现设计上的问题,所付出的代价越大,修改的难度也越大。
数据库是整个应用的根基,没有坚实的根基,整个应用也就岌岌可危了。
强大的数据库面对不良设计也无能为力
现代数据库管理系统(DBMS)提供了方便的图形化界面工具,通过这些工具可以很方便的创建表、定义列,但我们设计出的结构好吗?
关系数据库有许多非常好的特性,但设计不当会使这些特性部分或完全的丧失。
我们来看看以下几个数据库不良设计造成的场景:
1. 数据一致性的丧失
一个订单管理系统,维护着客户和客户下的订单信息。使用该系统的用户在接到客户修改收货地址的电话后,在系统的客户信息页面把该客户的收货地址进行了修改,但原先该客户的订单还是送错了地址。
2. 数据完整性的丧失
公司战略转移,准备撤出某地区。系统操作人员顺手把该地区的配置信息在系统中进行删除,系统提示删除成功。随后问题就来了,客服人员发现该地区的历史订单页面一打开就出错。
3. 性能的丧失
一个库存管理系统,仓库管理员使用该系统记录每一笔进出货情况,并能查看当前各货物的库存情况。在系统运行几个月后,仓库管理员发现打开当前库存页面变得非常慢,而且整个趋势是越来越慢。
上面这些场景都是由于数据库设计不当造成的,根源包括:设计时引入了冗余字段,没有设计合理的约束,对性能没有进行充足设计等,上面的例子也只是沧海一粟。

数据库平台无关性
我在这个系列博客里讨论的数据库设计不针对任何一个关系数据库产品。无论你使用的是Oracle,SQL Server,Sybase,亦或是开源数据库如:MySQL,SQLite等,都可以用来实践我们这里讨论的设计方法和设计理念,设计是这个系列博文的核心和灵魂。
注:在文中我会选用一个数据库产品来进行演示,大家可以选用自己熟悉的数据库产品来实验。本文最后会给出一些免费数据库产品的链接,大家可以下载学习。
一起学习共同进步
无论你是数据库设计师,应用架构师,软件工程师,数据库管理员(DBA),软件项目经理,软件测试工程师等项目组成员,都能从该系列博文中有所收获。大家一起讨论,共同进步。
内容涉及领域
我对这一系列博文现在的设想是涉及数据库设计的整个过程。从需求分析开始,到数据库建模(概念数据建模),进行范式化,直至转化为SQL语句。

在我们一头扎进数据库设计之前,我们先了解一下除了关系型数据库之外的数据存储方式。
平面文件(Flat File)
包括以.txt和.ini结尾的文件。
eg: 一个.ini文件的内容:
------------------------------------------------------------
[WebSites]
MyBlog=http://www.cnblogs.com/DBFocus
[Directorys]
Image=E:\DBFocus Project\Img
Text=E:\DBFocus Project\Documents
Data=E:\DBFocus Project\DB
------------------------------------------------------------
优点:
文件的存储形式非常简单,普通的编辑器都能对其进行打开、修改
缺点:
无法支持复杂的查询
没有任何验证功能
对平面文件中间的内容进行插入、删除操作其实是重新生成了一个新文件
适用场景:
存放小量,修改不频繁的数据,如应用配置信息
Windows注册表
错误的修改Windows注册表会引起系统的紊乱,故不建议把很多数据存放在注册表中。
Windows注册表为树形结构,存放着一些系统配置信息和应用配置信息。
通过把不同的配置存放在注册表的不同分支上,使得应用程序公共配置信息与用户个人配置信息分离。
eg:某文档版本管理系统,能通过配置与本主机上安装的文件比较器建立关联进行文档比较。这是一个公共配置信息,文件比较器路径可以存放在注册表的HKEY_LOCAL_MACHINE\SOFTWARE分支下。
同时该文档版本管理系统能记录用户最近打开的10个文档路径。这是用户个人配置信息,对于不同的Windows用户最近打开的10个文档可以不同,这些配置信息可存放在注册表的HKEY_CURRENT_USER\Software分支下。
Excel表单(Spreadsheets)
优点:
Excel 非常普及,用户对于Spreadsheet的表现形式非常熟悉
可以进行简单统计,方便出各种图表
缺点:
不适用于许多Spreadsheet之间关系复杂的情况
无法应对复杂查询
数据验证功能弱
适用场景:
数据量不是非常大的办公自动化环境
XML
XML是一种半结构化的数据。相比于超文本标记语言(HTML),其标签是可以自行定义的,即可扩展的。
eg:一个XML文件内容
-----------------------------------------------------
<?xml version=”1.0” encoding=”UTF-8” ?>
<ClassSchedule>
<Class Name=“Psychology” Room=”Field 3”>
<Instructor>Richard Storm</Instructor>
<Students>
<Student>
<FirstName>Ben</FirstName>
<LastName>Breaker</LastName>
</Student>
<Student>
<FirstName>Carol</FirstName>
<LastName>Enflame</LastName>
<NickName>Candy</NickName>
</Student>
</Students>
</Class>
</ClassSchedule>
-----------------------------------------------------
XML文件有几个特点。
首先,XML标签要求严格对应,且不能出现交错的现象。
其次,XML文件必须有一个根节点,该节点包含所有其他元素。
第三,同级别的不同节点内不必包含相同的元素,如上例中第二个学生Carol有一个特别的节点NickName。这个特性使得在某些场景中XML比关系数据库更能应对变化。
优点:
自然的层次型结构
文本内容通过标签是自解释的
通过XSD(XML Schema语言)可以验证XML的结构
有许多辅助型技术如:XPath, XQuery, XSL, XSLT等
一些商业数据库(如Oracle,SQL Server)已支持XML数据的存储与操作
缺点:
数据的冗余信息较多
无法支持复杂的查询
验证功能有限
对XML中间的内容进行插入、删除操作其实是重新生成一个新文件
适用场景:
适合存放数据量不大,具有层次型结构的数据,如树形配置信息
NoSQL数据库
非关系型数据库我接触的不是很多,除了给出一些产品名称之外不做很多展开。园子里已有一些文章,本文最后也给出了链接供大家学习、研究。
1. Key-Value数据库
Redis, Tokyo Cabinet, Flare
2. 面向文档的数据库
MongoDB, CouchDB
3. 面向分布式计算的数据库
Cassandra, Voldemort
这几年NoSQL非常热。我认为NoSQL并不是“银弹”,在某些SNS应用场景中NoSQL显示了其优越性,但在如金融行业等对数据的一致性、完整性、可用性、事务性高要求的场景下,现在的NoSQL就未必适用。我们应充分分析应用的需求,非常谨慎地选择技术和产品。

主要内容回顾
1.数据库设计对于软件项目成功的关键作用
2.本课程与数据库产品无关,核心是设计的理念和方法
3.各种数据存储所适用的场景
Step by Step (2)
引言:数据库设计 Step by Step (1)得到这么多朋友的关注着实出乎了我的意外。这也坚定了我把这一系列的博文写好的决心。近来工作上的事务比较繁重,加之我期望这个系列的文章能尽可能的系统、完整,需要花很多时间整理、思考数据库设计的各种资料,所以文章的更新速度可能会慢一些,也希望大家能够谅解。系列的第二讲我们将站在高处俯瞰一下数据库的生命周期,了解数据库设计的整体流程

数据库生命周期
大家对软件生命周期较为熟悉,数据库也有其生命周期,如下图所示。
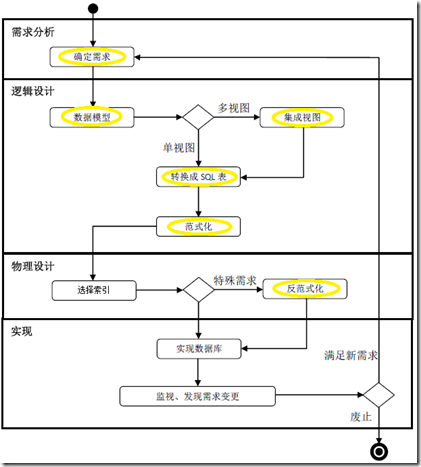
图(1)数据库生命周期
数据库的生命周期主要分为四个阶段:需求分析、逻辑设计、物理设计、实现维护。
这个系列的博文将主要关注数据库生命周期中的前两个阶段(需求分析、逻辑设计),还会涉及反范式化设计的一些内容。如图中高亮圈出的部分。
数据库的物理设计,包括索引的选择与优化、数据分区等内容。这些内容也非常丰富,而且可以自成体系,园子里也有很多好文章,故在本系列中不作主要关注。本文最后将给出一些链接供大家参考。
数据库生命周期的四个阶段又能细分为多个小步骤,我们配合图(1)来看看每一小步包含的内容。
阶段1 需求分析
数据库设计与软件设计一样首先需要进行需求分析。
我们需要与数据的创造者和使用者进行访谈。对访谈获得的信息进行整理、分析,并撰写正式的需求文档。
需求文档中需包含:需要处理的数据;数据的自然关系;数据库实现的硬件环境、软件平台等;

图(2)阶段1 需求分析
阶段2 逻辑设计
使用ER或UML建模技术,创建概念数据模型图,展示所有数据以及数据间关系。最终概念数据模型必须被转化为范式化的表。
数据库逻辑设计主要步骤包括:
a) 概念数据建模
在需求分析完成后,使用ER图或UML图对数据进行建模。使用ER图或UML图描述需求中的语义,即得到了数据概念模型(Conceptual Data Model),例如:三元关系(ternary relationships)、超类(supertypes)、子类(subtypes)等。
eg: 零售商视角,产品/客户数据库的ER模型简图
注:ER图的含义,以及详细标记方法将在该系列的下一篇博文中进行讨论
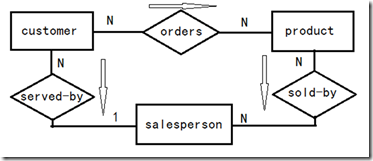
图(3)阶段2(a) 概念数据建模
b) 多视图集成
当在大型项目设计或多人参与设计的情况下,会产生数据和关系的多个视图。这些视图必须进行化简与集成,消除模型中的冗余与不一致,最终形成一个全局的模型。多视图集成可以使用ER建模语义中的同义词(synonyms)、聚合(aggregation)、泛化(generalization)等方法。多视图集成在整合多个应用的场景中也非常重要。
eg: 集成零售商ER图与客户ER图
零售商ER图如图(3)所示。客户视角,产品/客户数据库的ER模型简图如下:
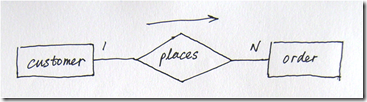
图(4)以客户为关注点绘制的ER图
注:现在市面上有许多辅助建模工具可以绘制ER图。使用Sybase的PowerDesigner绘制与图(4)相同语义的ER图如下:
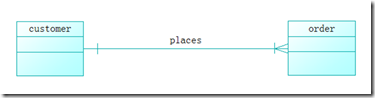
其标记法与图(4)中略有不同,这将在今后的博文中加以说明。
这里需要指出的是辅助软件的使用不是设计的核心,大家不要被这些工具迷惑。所以后文中我们将主要使用手绘。只要掌握了ER图的语义,使用这些软件都不会是件难事。
集成零售商ER图与客户ER图
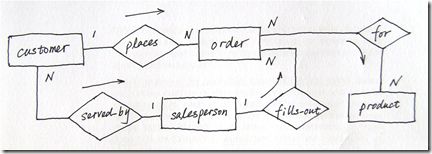
图(5) 阶段2(b) 多视图集成
c) 转化概念数据模型为SQL表
根据映射规则,把ER图中的实体与关系转化为SQL表结构。在这一过程中我们将识别冗余的表,并去除这些表。
eg: 把图(5)中的customer, product, salesperson实体转化为SQL表

图(6) 阶段2(c)转化概念数据模型为SQL表
d) 范式化
范式化是数据库逻辑设计中的重要一步。范式化的目标是尽可能去除模型中的冗余信息,从而消除关系模型更新、插入、删除异常(anomalies)。
讲到范式化就会引出函数依赖(Functional Dependency)这一概念。函数依赖(FDs)源自于概念数据模型图,反映了需求分析中的数据关系语义。不同实体之间的函数依赖表示各个实体唯一键之间的依赖。实体内部也有函数依赖,反映了实体中键属性与非键属性之间的依赖。在保证数据完整性约束的前提下,基于函数依赖对候选表进行范式化(分解、降低数据冗余)。
eg: 对图(6)中的Salesperson表进行范式化,消除更新异常(update anomalies)
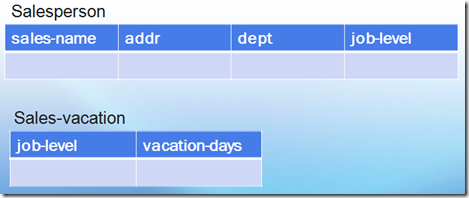
图(7) 阶段2(d)范式化
阶段3 物理设计
数据库物理设计包括选择索引,数据分区与分组等。
逻辑设计方法学通过减少需要分析的数据依赖,简化了大型关系数据库的设计,这也减轻了数据库物理设计阶段的压力。
1. 概念数据建模和多视图集成准确地反映了现实需求场景
2. 范式化在模型转化为SQL表的过程中保留了数据完整性
数据库物理设计的目标是尽可能优化性能。
物理设计阶段,全局表结构可能需要进行重构来满足性能上的需求,这被称为反范式化。
反范式化的步骤包括:
1. 辨别关键性流程,如频繁运行、大容量、高优先级的处理操作
2. 通过增加冗余来提高关键性流程的性能
3. 评估所造成的代价(对查询、修改、存储的影响)和可能损失的数据一致性
阶段4 数据库的实现维护
当设计完成之后,使用数据库管理系统(DBMS)中的数据定义语言(DDL)来创建数据结构。
数据库创建完成后,应用程序或用户可以使用数据操作语言(DML)来使用(查询、修改等)该数据库。
一旦数据库开始运行,就需要对其性能进行监视。当数据库性能无法满足要求或用户提出新的功能需求时,就需要对该数据库进行再设计与修改。这形成了一个循环:监视 –> 再设计 –> 修改 –> 监视…。

在进行数据库设计之前,我们先回顾一下关系数据库的相关基本概念。
这里只做一个提纲挈领的简介,大家可以根据相应的线索进行扩展。
表、行、列
关系数据库可以想象成表的集合,每个表包含行与列。(可以想象成一个Excel workbook,包含多个worksheet)。
表在关系代数中被称为关系,这也是关系数据库名称的起源(不要与表之间的外键关系混淆)。
列在关系代数中被称为属性(attribute)。列中允许存放的值的集合称为列的域(域与数据类型密切相关,但并不完全相同)。
行在关系代数中的学名是元组(tuple)。
关系数据库的理论基础来自于“关系代数”。但在关系代数中,一个集合的各个元组没有次序的概念,在关系数据库中为了方便使用,定义了行的次序。
键、索引
键是一种约束,目的是保证数据完整性
1. 复合键(Compound key):由多个数据列组成的键
2. 超键(Superkey):列的集合,其中任何两行都不会完全相同
3. 候选键(Candidate key):首先是一个超键,同时这个超键中的任何列的缺失都会破坏行的唯一性
4. 主键(Primary key):指定的某个候选键
索引是数据的物理组织形式,目的是提高查询的性能
约束
基本约束
not null constraint, domain constraint
检查约束(Check Constraints)
eg: Salary > 0
主键约束(Primary Key Constraints)
实体完整性(entity integrity),没有两条记录是完全相同的,组成主键的字段不能为null
唯一性约束(Unique Constraints)
外键约束(Foreign Key Constraints)
也被称为引用完整性约束,eg:
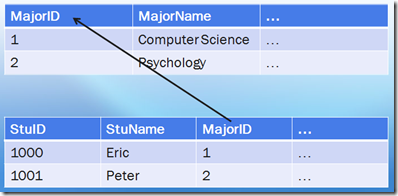
关系数据库操作
1.选择(Selection)
2.映射(Projection)
3.联合(Union)
4.交集(Intersection)
5.差集(Difference)
6.笛卡尔积(Cartesian Product)
7.连接(Join)
上述7种是最基本的关系数据库操作,对应于集合论中的关系运算。
有些书籍中还会加入改名(Rename),除(Divide)等关系操作。

主要内容回顾
1. 数据库生命周期的四个阶段:需求分析、逻辑设计、物理设计、实现维护。
2. 关系数据库的理论基础是关系代数。
Step by Step (3)
引言:数据库设计 Step by Step (2)在园子里发表之后,收到了一些邮件,还有朋友直接电话我询问为什么不包含数据库物理设计方面的内容。我在这里解释一下,数据库物理设计与数据库产品是密切相关的,本系列的专注点是较为通用的数据库设计理念与方法,这也是国内软件项目中容易被忽视的一块。今天我们将学习实体关系(ER)模型构件及其语义,这是数据库逻辑设计的基础。内容可能有些枯燥,但却非常重要和有用。由于内容比较多,我们将分两讲来学习实体关系模型构件。
今天我们先来学习基本实体关系模型。

实体关系(ER)模型的目标是捕获现实世界的数据需求,并以简单、易理解的方式表现出来。ER模型可用于项目组内部交流或用于与用户讨论系统数据需求。
ER模型中的基本元素
基本的ER模型包含三类元素:实体、关系、属性
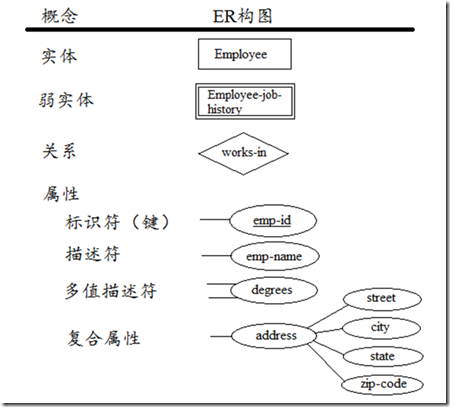
图1 实体、关系、属性的ER构图
实体(Entities):实体是首要的数据对象,常用于表示一个人、地方、某样事物或某个事件。一个特定的实体被称为实体实例(entity instance或entity occurrence)。实体用长方形框表示,实体的名称标识在框内。一般名称单词的首字母大写。
关系(Relationships):关系表示一个或多个实体之间的联系。关系依赖于实体,一般没有物理概念上的存在。关系最常用来表示实体之间,一对一,一对多,多对多的对应。关系的构图是一个菱形,关系的名称一般为动词。关系的端点联系着角色(role)。一般情况下角色名可以省略,因为实体名和关系名已经能清楚的反应角色的概念,但有些情况下我们需标出角色名来避免歧义。
属性(Attributes):属性为实体提供详细的描述信息。一个特定实体的某个属性被称为属性值。Employee实体的属性可能有:emp-id, emp-name, emp-address, phone-no……。属性一般以椭圆形表示,并与描述的实体连接。属性可被分为两类:标识符(identifiers),描述符(descriptors)。Identifiers可以唯一标识实体的一个实例(key),可以由多个属性组成。ER图中通过在属性名下加上下划线来标识。多值属性(multivalued
attributes)用两条线与实体连接,eg:hobbies属性(一个人可能有多个hobby,如reading,movies…)。复合属性(Complex attributes)本身还有其它属性。
辨别强实体与弱实体:强实体内部有唯一的标识符。弱实体(weak entities)的标识符来自于一个或多个其它强实体。弱实体用双线长方形框表示,依赖于强实体而存在。
深入理解关系
关系在ER模型中扮演了非常重要的角色。通过ER图可以描述实体间关系的度、连通数、存在性信息。
我们一一来解释这些概念。首先我们来看一下关系在ER图中的各种语义。
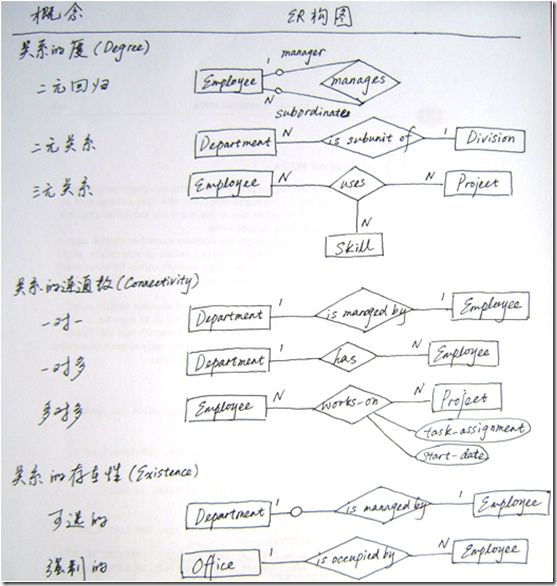
图2 关系的度、连通数、存在性
关系的度(Degree of a Relationship)
表示关系所关联的实体数量。二元关系与三元关系的度分别为2和3,以此可以类推至n元。二元关系是最常见的关系。
一个Employee与另一个Employee之间的领导关系称为二元回归关系。如图2中所示,Employee实体通过关系manages与自身连接。由于Employee在这一关系中扮演两个角色,故标出了角色名(manager和subordinate)。
三元关系联系三个实体。当二元关系无法准确描述关联的语义时,就需要使用三元关系。我们来看下面这个例子,下图(1)能反映出一个Employee在某个Project中使用了什么Skill。下图(2)只能看出Employee有什么Skill,参与了哪些Project,但无法知道在某个Project中使用的特定Skill。
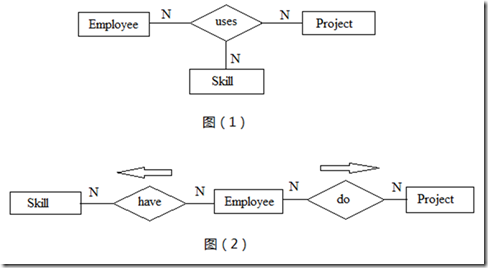
图3 三元关系蕴含的语义
需要注意的是有些情况下会错误的定义三元关系。这些三元关系可分解为2个或3个二元关系,来达到化简与语义的纯净。以后的博文中会进一步详细讨论三元关系。
一个实体可以参与到任意多个关系中。每个关系可以联系任意多个元(实体),而且两个实体之间也能有任意多个二元关系。
关系的连通数(Connectivity of a Relationship)
表示关系所关联的实例数量的约束。
连通数的值可以是“一”或“多”。“一”这一端,在ER图中通过在实体与关系间标记“1”表示。“多”一端标记“N”表示。如图2中关系连通数部分,“一”对“一”:Department is managed by Employee;“一”对“多”:Department has Employees;“多”对“多”:Employee may work on many
Projects and each Project may have many Employees。
有些情况下最大连通数是确定的,可以用数值代替N。如:田径队队员有12人。
关系的属性
关系也能有属性。如下图4所示,某员工参与某项目的起始日期,某员工在某项目中被分配的任务只有放在关系works-on上才有意义。
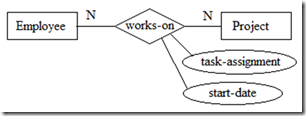
图4 关系的属性
需要注意的是关系的属性一般出现在“多”对“多”的二元关系或三元关系上。一般“一”对“一”或“一”对“多”关系上不会放属性(会引起歧义)。而且这些属性可以移至一端的实体中。如下图5所示,如果部门与员工(经理)之间是“一”对“一”关系,在建模中可能把start-date作为关系is managed by的属性(表示被接管的时间),这个属性可以移至Department或Employee实体中。
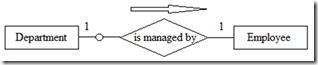
图5 部门与经理之间的一对一管理关系
大家可以思考一下如果部门和经理之间是“多”对“多”关系,即交叉管理,那又会怎样?
关系中实体的存在性(Existence of an Entity in a Relationship)
关系中实体的存在性可以是强制的或可选的。当关系中的某一边实体(无论是“一”或“多”端)必须总是存在,则该实体为强制的。反之,该实体为可选的。
在实体与关系之间的连接线上标识“0”来表示可选存在性。含义是最小连通数为0。
强制存在性表示最小连通数为1。在存在性不确定或不可知的情况下,默认最小连通数为1。
在ER图中最大连通数显式地标识在实体旁边。如图6所示,其蕴含的语义为一个Department有且只有一个Employee来当经理,一个Employee可能是一个Department的经理,也可能不是。
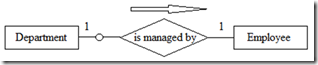
图6 关系中实体的存在性
其他概念数据模型标记法
前文中使用的ER构图方法是Peter Chen 1976年提出的。在现代数据库设计领域,还有其他多种ER模型标记法。
我们来看一下另一种使用较多的标记法,“crow’s-foot”(鱼尾纹)标记法,并与前面介绍的标记法进行一个简单对比。
学习每一种标记法没有意义。在你的组织中推广应用一种标记法,使其成为大家共通的“语言”。
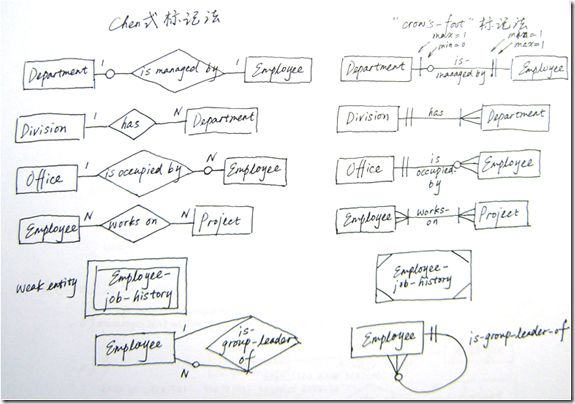
图7 Chen式标记法与crow’s-foot标记法对照

主要内容回顾
1. 组成ER模型的基本元素包括:实体、关系、属性
2. 深入理解关系中包含的语义:关系的度、关系的连通数、关系的存在性
3. 了解ER模型的不同标记法,掌握其中一种标记法,并在你的项目中推广使用
Step by Step (4)
引言:数据库设计 Step by Step (3)中我们讨论了基本实体关系模型构件及其语义。这些概念非常重要,是今天这一讲的基础,在开始本文内容之前建议大家可以再回顾一下上一篇的内容。今天我们将讨论高级实体关系模型构件,与上一篇一起涵盖了ER模型构图的大部分内容。三元关系是今天这一讲的难点,大家可以重点关注。
泛化(Generalization):超类型与子类型
原始的ER模型已经能描述基本的数据和关系,但泛化(Generalization)概念的引入能方便多个概念数据模型的集成。
泛化关系是指抽取多个实体的共同属性作为超类实体。泛化层次关系中的低层次实体——子类型,对超类实体中的属性进行继承与添加,子类型特殊化了超类型。
ER模型中的泛化与面向对象编程中的继承概念相似,但其标记法(构图方式)有些差异。
下图表示员工与经理、工程师、技术员、秘书之间的泛化关系。Employee为超类实体,并包含共同属性,Manager、Engineer、Technician、Secretary都是Employee的子类实体,它们能包含自身特有的属性。
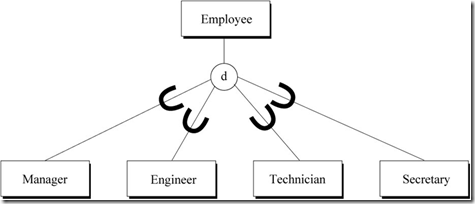
图1 Employee与Manager、Engineer、Technician、Secretary之间的泛化关系
泛化可以表达子类型的两种重要约束,重叠性约束(disjointness)与完备性约束(completeness)。
重叠性约束表示各个子类型之间是否是排他的。若为排他的则用字母“d”标识,否则用“o”标识(o -> overlap)。图1中各子类实体概念上是排他的。
对员工、客户实体进行泛化,抽象出超类实体个人,得到如下关系图。由于部分Employee也可能是Customer,故子类实体Employee与Customer之间概念是重叠的。
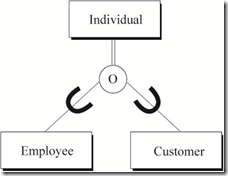
图2 Individual与Employee、Customer之间的泛化关系
完备性约束表示所有子类型在当前系统中是否能完全覆盖超类型。若能完全覆盖则在超类型与圆圈之间用双线标识(可以把双线理解为等号)。在图2中子类实体Employee与Customer能完全覆盖超类Individual实体。
聚合(Aggregation)
聚合是与泛化抽象不同的另一种超类型与子类型间的抽象。
泛化表示“is-a”语义,聚合表示“part-of”语义。聚合中子类型与超类型间没有继承关系。
聚合关系的标记法是在圆圈中标识字母“A”来表示。
下图表示软件产品由程序与用户手册组成。
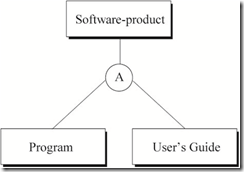
图3 Software-product与Program、User’s Guide之间的聚合关系
三元关系(Ternary Relationships)
当通过二元关系无法准确描述三个实体间的联系时,我们需要使用三元关系。
三元关系中“连通数”的确定方法:
a) 以三元关系中的一个实体作为中心,假设另两个实体都只有一个实例
b) 若中心实体只有一个实例能与另两个实体的一个实例进行关联,则中心实体的连通数为“一”
c) 若中心实体有多于一个实例能与另两个实体实例进行关联,则中心实体的连通数为“多”
注:什么时候需要使用三元关系的实例请参看:数据库设计 Step by Step (3)中的“关系的度(Degree of a Relationship)”小节。关系的“连通数”概念请参看:数据库设计 Step by Step (3)中的“关系的连通数(Connectivity of a Relationship)”小节。
我们来看几个三元关系的实例,注意各个图中关系的度,并理解其中的语义。
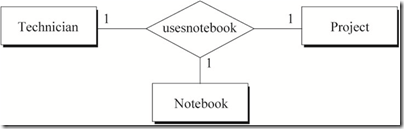
4 技术员在项目中使用手册的关系
图4中蕴含的语义为:
a) 一名技术员对于每一个项目使用一本手册
b) 每一本手册对于每一个项目属于一名技术员
c) 一名技术员可能在做多个项目,对于不同的项目维护不同的手册
用数学中的函数依赖表示图4的关系:
a) emp-id, project-name -> notebook-no
b) emp-id, notebook-no -> project-name
c) project-name, notebook-no -> emp-id
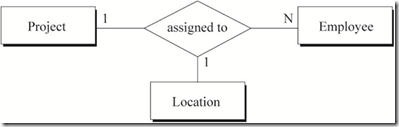
图5 员工被分配不同地点的项目之间的关系
图5中蕴含的语义为:
a) 每一个员工在一个地点只能被分配一个项目,但可以在不同地点做不同的项目
b) 在一个特定的地点,一个员工只能做一个项目
c) 在一个特定的地点,一个项目可以由多个员工来做
用数学中的函数依赖表示图5的关系:
a) emp-id, loc-name -> project-name
b) emp-id, project-name -> loc-name
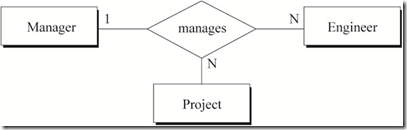
图6 经理管理项目与工程师的关系
图6中蕴含的语义为:
a) 一名经理手下的一名工程师可能参与多个项目
b) 一名经理管理的一个项目可能会有多名工程师
c) 做某一个项目的一名工程师只会有一名经理
用数学中的函数依赖表示图6的关系:
a) project-name, emp-id -> mgr-id
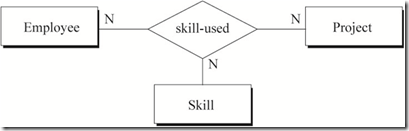
图7 员工在项目中使用技能的关系
图7中蕴含的语义为:
a) 一名员工在一个项目中可以使用多种技能
b) 一名员工的一种技能可以在多个项目中使用
c) 一种技能在一个项目中可以被多名员工使用
图7各实体之间没有函数依赖
上述4种形式的三元关系,连通数为“一”的实体数量与该三元关系反映的函数依赖语义的数目一致。
三元关系也能有属性。属性值由三个实体的键的组合唯一确定。
n元关系(General n-ary Relationships)
三元关系可以扩展到n元关系,描述n个实体之间的关系。
一般而言,n元关系中每一个连通数为“一”的实体的键都会出现在一个函数依赖表达式的右侧。
对于n元关系,使用语言来表达其中的约束相对较为困难。建议使用数学形式即函数依赖(FD)来表现。
n元关系的函数依赖条目数量与关系图中“一”端实体的数量相同(0~n条)。
n元关系的函数依赖表达式包含n个元素,n-1个元素出现在表达式左侧,1个元素出现在右侧。
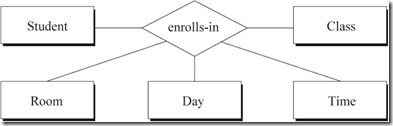
图8 n元关系图例
排他性约束(Exclusion Constraint)
一般(默认)情况下,多种关系之间是兼容的“或”关系,即允许任意或所有实体参与这些关系。
在某些情况下,多种关系之间是非兼容性“或”关系,即参与关系的实体只能选择其中一种关系,不能同时选择多种关系。
下图表示的语义为:一项工作任务要么被归为外部项目中,要么被归为内部项目中,不可能同时属于外部项目和内部项目。
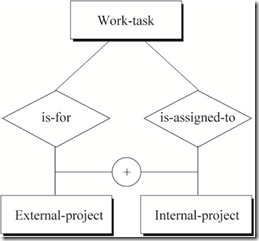

相关文章推荐
- 数据库设计 Step by Step (6) —— 提取业务规则
- 数据库设计 Step by Step (5)——理解用户需求
- 数据库设计 Step by Step (6) —— 提取业务规则
- 数据库设计 Step by Step (2)——数据库生命周期
- 数据库设计 Step by Step (3)——基本ER模型构件
- 【推荐】数据库设计Step by Step
- 数据库设计 Step by Step (4)——高级ER模型构件
- 数据库设计 Step by Step (3)——基本ER模型构件
- 数据库设计 Step by Step (5)——理解用户需求
- 数据库设计 Step by Step (5)——理解用户需求
- 数据库设计 Step by Step (3)
- 数据库设计 Step by Step
- 数据库设计 Step by Step (6) —— 提取业务规则
- 数据库设计 Step by Step (1)
- [转]数据库设计 Step by Step (5)
- 数据库设计 Step by Step (1)
- 数据库设计 Step by Step (2)
- 数据库设计 Step by Step (3)——基本ER模型构件
- 数据库设计 Step by Step (1)