大数据图数据库之MapReduce用于图计算
2014-09-23 19:00
225 查看
/* 版权声明:可以任意转载,转载时请务必标明文章原始出处和作者信息 .*/
CopyMiddle: 张俊林
节选自《大数据日知录:架构与算法》十四章,书籍目录在此
1.使用Mapreduce进行图计算
使用MapReduce框架来针对大规模图数据进行计算的研究工作相对较少,这主要归结于两方面原因:一方面,将传统的图计算映射为MapReduce任务相对其他类型的很多任务而言不太直观;另一方面,从某种角度讲,使用该分布计算框架解决图计算任务也并非最适宜的解决方案。
尽管有上述缺点,但很多图算法还是可以转换为Mapreduce框架下的计算任务。下面以PageRank计算为例讲述如何在该框架下进行图计算。PageRank的计算原理在前面已有介绍,本节重点分析如何在Mapreduce框架下对算法进行改造,使得可以用多机分布方式对大规模图进行运算。
Mapreduce框架下的输入往往是key-value数据对,其中,value可以是简单类型,比如数值或字符串,也可以是复杂的数据结构,比如数组或者记录等。对于图数据来说,其内部表示方式以邻接表为宜,这样,输入数据的key为图节点ID,对应的value为复杂记录,其中记载了邻接表数据、key节点的PageRank值等。
对很多图算法来说,Mapreduce内部计算过程中的Shuffle和Sort操作起到类似于通过图中节点出边进行消息传播的效果。从图14-7的PageRank伪码中可见此技巧的运用。

在该例的Map操作中,输入数据的key是图节点ID,value是图节点数据结构N,其中包括邻接表AdjacencyList信息以及节点对应的当前PageRank值。第3行代码计算当前节点传播到邻接节点的PageRank分值,第5、6行代码将这些分值转换为新的key1-value1,以邻接节点ID作为新的key,而从当前节点传播给邻接节点的分值作为新的value1。除此之外,还需要将当前节点的节点信息继续保留,以便进行后续的迭代过程,所以第4行代码将输入记录本身再次原封不动地传播出去。
通过MapReduce内部的Shuffle和Sort操作,可以将相同key1对应的系列value1集中到一起,即将ID为key1的图节点从其他节点传入的PageRank部分分值聚合到一起,这起到了类似于消息传播的作用。图14-7示例里的Reduce操作中,其对应的输入数据包括图节点ID以及对应的PageRank部分分值列表,伪码第4行到第8行累积这部分分值形成新的PageRank值,同时判断某个value1是否是节点信息(第5行代码)。第9行代码则更新节点信息内的PageRank值,而第10行代码输出更新后的节点信息。这样就完成了一轮PageRank迭代过程,而本次Reduce阶段的输出结果可以作为下一轮迭代Map阶段的输入数据。如此循环往复,直到满足终止条件,即可输出最终的计算结果。

Mapreduce计算框架在Map操作后会通过网络通信将具有相同key值的中间结果记录映射到同一台机器上,以满足后续Reduce阶段操作的要求。一般情况下,这种网络传输数据量非常大,往往会严重影响计算效率,而Combine操作即为减少网络传输以优化效率而提出。Combine操作在本地机器Map操作后,首先将具有相同key值的Map结果数据value部分进行本地聚合,这样本来应该分别传输的项目即被合并,大大减少了网络传输量,加快了计算速度。对于图计算,同样可以采用这种优化手段改善效率,图14-8展示了相应的Combine操作,其运行流程与Reduce操作大体相似,第4行到第8行代码累加相同key的本地value数据,第9行代码将这种累加数据传播出去,key保持不变,value成为聚合数据s,这样就大量减少了网络传输量。
上面介绍了如何在Mapreduce框架下进行PageRank计算,很多其他图算法也可用近似的思路处理,其关键点仍然是通过上述的Shuffle和Sort操作,将同一节点的入边聚合到一起,而Reduce操作可以类似例中的部分数值求和,也可能是取边中的Max/Min等其他类型的操作,这依据应用各异,但基本思想无较大的区别。
2.MapReduce在图计算中存在的问题
MapReduce尽管已经成为主流的分布式计算模型,但有其适用范围,对于大量的机器学习数据挖掘类科学计算和图挖掘算法来说,使用Mapreduce模型尽管经过变换也可以得到解决,但往往并非解决此类问题的最佳技术方案。根本原因在于:很多科学计算或者图算法内在机制上需要进行多轮反复迭代,而如果采用Mapreduce模型,每一次迭代过程中产生的中间结果都需要反复在Map阶段写入本地磁盘,在Reduce阶段写入GFS/HDFS文件系统中,下一轮迭代一般是在上一轮迭代的计算结果的基础上继续进行,这样需要再次将其加载入内存,计算得出新的中间结果后仍然写入本地文件系统以及GFS/HDFS文件系统中。如此反复,且不必要的磁盘输入/输出严重影响计算效率。除此之外,每次迭代都需要对任务重新进行初始化等任务管理开销也非常影响效率。
下面以Mapreduce模型计算图的单源最短路径的具体应用实例来说明此问题的严重性。所谓“单源最短路径”,就是对于图结构G<N,E>(N为图节点集合,E为图中边集合且边具有权值,这个权值代表两个节点间的距离),如果给定初始节点V,需要计算图中该节点到其他任意节点的最短距离是多少。这个例子的图结构如图14-9所示,图的内部表示采用邻接表方案。假设从源节点A出发,求其他节点到节点A的最短距离,在初始化阶段,设置源节点A的最短距离为0,其他节点的最短距离为INF(足够大的数值)。
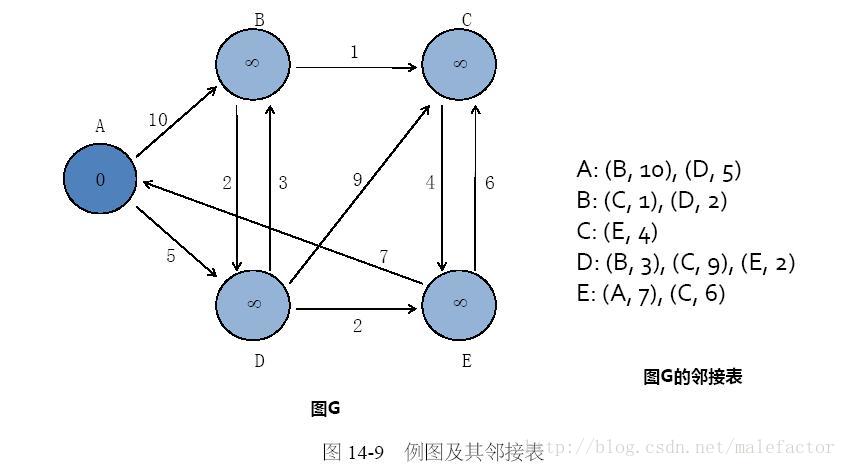
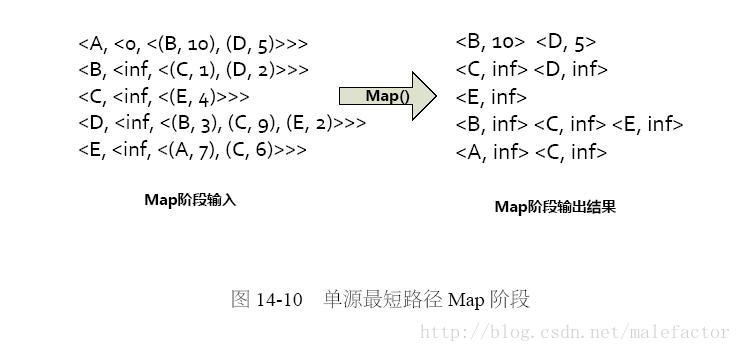
对Mapreduce模型来说,计算分为两个阶段,即Map阶段和Reduce阶段。针对上述问题,Map阶段的最初输入即为稍加改造的图G的邻接表,除了节点的邻接表信息外,还需要额外记载节点当前获得的最小距离数值。以常见的key-value方式表示为:key=节点ID,value=<节点到源节点A的当前最小距离Dist,邻接表>。以源节点A为例,其Map阶段的输入为:<A, <0, <(B, 10),(D, 5)>>>,其他节点输入数据形式与此类似。
Map阶段对输入数据的转换逻辑为:计算key节点的邻接表中节点到源节点A的当前最短距离。即将key-value转换为key1-value1序列,这里key1是key节点的邻接表中节点ID,value1为key1节点到源节点A的当前最短距离。以源节点A为例,其输入为<A, <0, <(B, 10), (D, 5)>>>,经过Map转换后,得到输出<B,10>和<D,5>,<B,10>的含义是:B节点到A节点的当前最短距离是10(由A节点到源节点A距离0加上B节点到A节点距离10获得),<D,5>的含义与之类似。通过此步可以完成Map阶段计算,图14-10展示了原始输入转换为Map阶段输出结果对应的KV数值。
在Map阶段产生结果后,系统会将临时结果写入本地磁盘文件中,以作为Reduce阶段的输入数据。Reduce阶段的逻辑为:对某个节点来说,从众多本节点到源节点A的距离中选择最短的距离作为当前值。以节点B为例,从图14-10中Map阶段的输出可以看出,以B为key有两项:<B,10>和<B,inf>,取其最小值得到新的最短距离为10,则可输出结果<B,<10,<(C,1),(D,2)>>>。图14-11展示了Reduce阶段的输出。
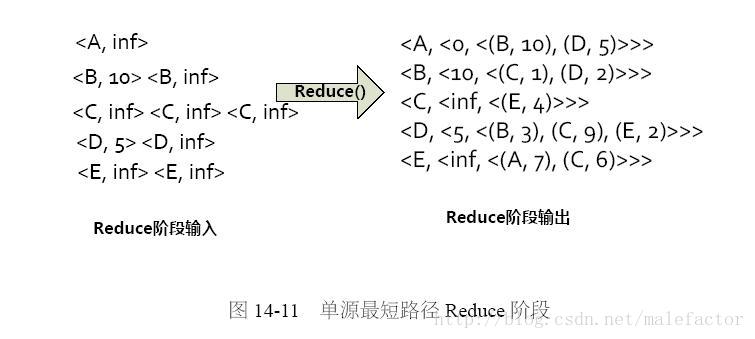
在Reduce阶段结束后,系统将结果写入GFS/HDFS文件系统中,这样完成了单源最短路径的一轮计算。使得图节点B和图节点D的当前最短路径获得了更新。而为了能够获得最终的结果,还需要按照上述方式反复迭代,以本轮Reduce输出作为下一轮Map阶段的输入。由此可见,如果完成计算,则需要多次将中间结果往文件系统输出,这会严重影响系统效率。这是为何Mapreduce框架不适宜做图应用的主要原因。
CopyMiddle: 张俊林
节选自《大数据日知录:架构与算法》十四章,书籍目录在此
1.使用Mapreduce进行图计算
使用MapReduce框架来针对大规模图数据进行计算的研究工作相对较少,这主要归结于两方面原因:一方面,将传统的图计算映射为MapReduce任务相对其他类型的很多任务而言不太直观;另一方面,从某种角度讲,使用该分布计算框架解决图计算任务也并非最适宜的解决方案。
尽管有上述缺点,但很多图算法还是可以转换为Mapreduce框架下的计算任务。下面以PageRank计算为例讲述如何在该框架下进行图计算。PageRank的计算原理在前面已有介绍,本节重点分析如何在Mapreduce框架下对算法进行改造,使得可以用多机分布方式对大规模图进行运算。
Mapreduce框架下的输入往往是key-value数据对,其中,value可以是简单类型,比如数值或字符串,也可以是复杂的数据结构,比如数组或者记录等。对于图数据来说,其内部表示方式以邻接表为宜,这样,输入数据的key为图节点ID,对应的value为复杂记录,其中记载了邻接表数据、key节点的PageRank值等。
对很多图算法来说,Mapreduce内部计算过程中的Shuffle和Sort操作起到类似于通过图中节点出边进行消息传播的效果。从图14-7的PageRank伪码中可见此技巧的运用。
在该例的Map操作中,输入数据的key是图节点ID,value是图节点数据结构N,其中包括邻接表AdjacencyList信息以及节点对应的当前PageRank值。第3行代码计算当前节点传播到邻接节点的PageRank分值,第5、6行代码将这些分值转换为新的key1-value1,以邻接节点ID作为新的key,而从当前节点传播给邻接节点的分值作为新的value1。除此之外,还需要将当前节点的节点信息继续保留,以便进行后续的迭代过程,所以第4行代码将输入记录本身再次原封不动地传播出去。
通过MapReduce内部的Shuffle和Sort操作,可以将相同key1对应的系列value1集中到一起,即将ID为key1的图节点从其他节点传入的PageRank部分分值聚合到一起,这起到了类似于消息传播的作用。图14-7示例里的Reduce操作中,其对应的输入数据包括图节点ID以及对应的PageRank部分分值列表,伪码第4行到第8行累积这部分分值形成新的PageRank值,同时判断某个value1是否是节点信息(第5行代码)。第9行代码则更新节点信息内的PageRank值,而第10行代码输出更新后的节点信息。这样就完成了一轮PageRank迭代过程,而本次Reduce阶段的输出结果可以作为下一轮迭代Map阶段的输入数据。如此循环往复,直到满足终止条件,即可输出最终的计算结果。
Mapreduce计算框架在Map操作后会通过网络通信将具有相同key值的中间结果记录映射到同一台机器上,以满足后续Reduce阶段操作的要求。一般情况下,这种网络传输数据量非常大,往往会严重影响计算效率,而Combine操作即为减少网络传输以优化效率而提出。Combine操作在本地机器Map操作后,首先将具有相同key值的Map结果数据value部分进行本地聚合,这样本来应该分别传输的项目即被合并,大大减少了网络传输量,加快了计算速度。对于图计算,同样可以采用这种优化手段改善效率,图14-8展示了相应的Combine操作,其运行流程与Reduce操作大体相似,第4行到第8行代码累加相同key的本地value数据,第9行代码将这种累加数据传播出去,key保持不变,value成为聚合数据s,这样就大量减少了网络传输量。
上面介绍了如何在Mapreduce框架下进行PageRank计算,很多其他图算法也可用近似的思路处理,其关键点仍然是通过上述的Shuffle和Sort操作,将同一节点的入边聚合到一起,而Reduce操作可以类似例中的部分数值求和,也可能是取边中的Max/Min等其他类型的操作,这依据应用各异,但基本思想无较大的区别。
2.MapReduce在图计算中存在的问题
MapReduce尽管已经成为主流的分布式计算模型,但有其适用范围,对于大量的机器学习数据挖掘类科学计算和图挖掘算法来说,使用Mapreduce模型尽管经过变换也可以得到解决,但往往并非解决此类问题的最佳技术方案。根本原因在于:很多科学计算或者图算法内在机制上需要进行多轮反复迭代,而如果采用Mapreduce模型,每一次迭代过程中产生的中间结果都需要反复在Map阶段写入本地磁盘,在Reduce阶段写入GFS/HDFS文件系统中,下一轮迭代一般是在上一轮迭代的计算结果的基础上继续进行,这样需要再次将其加载入内存,计算得出新的中间结果后仍然写入本地文件系统以及GFS/HDFS文件系统中。如此反复,且不必要的磁盘输入/输出严重影响计算效率。除此之外,每次迭代都需要对任务重新进行初始化等任务管理开销也非常影响效率。
下面以Mapreduce模型计算图的单源最短路径的具体应用实例来说明此问题的严重性。所谓“单源最短路径”,就是对于图结构G<N,E>(N为图节点集合,E为图中边集合且边具有权值,这个权值代表两个节点间的距离),如果给定初始节点V,需要计算图中该节点到其他任意节点的最短距离是多少。这个例子的图结构如图14-9所示,图的内部表示采用邻接表方案。假设从源节点A出发,求其他节点到节点A的最短距离,在初始化阶段,设置源节点A的最短距离为0,其他节点的最短距离为INF(足够大的数值)。
对Mapreduce模型来说,计算分为两个阶段,即Map阶段和Reduce阶段。针对上述问题,Map阶段的最初输入即为稍加改造的图G的邻接表,除了节点的邻接表信息外,还需要额外记载节点当前获得的最小距离数值。以常见的key-value方式表示为:key=节点ID,value=<节点到源节点A的当前最小距离Dist,邻接表>。以源节点A为例,其Map阶段的输入为:<A, <0, <(B, 10),(D, 5)>>>,其他节点输入数据形式与此类似。
Map阶段对输入数据的转换逻辑为:计算key节点的邻接表中节点到源节点A的当前最短距离。即将key-value转换为key1-value1序列,这里key1是key节点的邻接表中节点ID,value1为key1节点到源节点A的当前最短距离。以源节点A为例,其输入为<A, <0, <(B, 10), (D, 5)>>>,经过Map转换后,得到输出<B,10>和<D,5>,<B,10>的含义是:B节点到A节点的当前最短距离是10(由A节点到源节点A距离0加上B节点到A节点距离10获得),<D,5>的含义与之类似。通过此步可以完成Map阶段计算,图14-10展示了原始输入转换为Map阶段输出结果对应的KV数值。
在Map阶段产生结果后,系统会将临时结果写入本地磁盘文件中,以作为Reduce阶段的输入数据。Reduce阶段的逻辑为:对某个节点来说,从众多本节点到源节点A的距离中选择最短的距离作为当前值。以节点B为例,从图14-10中Map阶段的输出可以看出,以B为key有两项:<B,10>和<B,inf>,取其最小值得到新的最短距离为10,则可输出结果<B,<10,<(C,1),(D,2)>>>。图14-11展示了Reduce阶段的输出。
在Reduce阶段结束后,系统将结果写入GFS/HDFS文件系统中,这样完成了单源最短路径的一轮计算。使得图节点B和图节点D的当前最短路径获得了更新。而为了能够获得最终的结果,还需要按照上述方式反复迭代,以本轮Reduce输出作为下一轮Map阶段的输入。由此可见,如果完成计算,则需要多次将中间结果往文件系统输出,这会严重影响系统效率。这是为何Mapreduce框架不适宜做图应用的主要原因。

相关文章推荐
- 大数据图数据库之MapReduce用于图计算
- CUDA——用于大量数据的超级计算:第二部分 (Rob Farber专栏)
- 添加修改后在datagridview里刷新数据,不是从数据库。用标识,跳转。(用于百万数据集)
- 【sjj】[论文笔记]适用于云计算的面向查询数据库数据分布策略
- 得到java时间戳 用于数据库中按时间戳查询数据
- 数据云计算回复网友提问:云计算,大数据,数据库,数据仓库之间是什么关系
- Sqoop源码分析(四) Sqoop中通过hadoop mapreduce从关系型数据库import数据分析
- 异构数据复制(主要用于数据库的升级)
- 基于winform的二进制图片数据的存取(用于数据库照片的读写处理)
- SQL Server Reporting Service 报错:报表服务器无法解密用于访问报表服务器数据库中的敏感数据或加密数据的对称密钥,必须还原备份密钥或删除所有加密的内容。
- 报表服务器无法解密用于访问报表服务器数据库中的敏感数据或加密数据的对称密钥。
- CUDA——用于大量数据的超级计算:第三部分 (Rob Farber专栏)
- 显示数据(从数据库中得到)中的html标签 用于解决数据在前台显示,样式被数据破坏的问题!!css
- Swing编程中用于显示数据库查询结果的数据模型
- Beyond MapReduce:谈数据流计算系统 | TID
- CUDA——用于大量数据的超级计算:第一部分 (Rob Farber专栏)
- "报表服务器无法解密用于访问报表服务器数据库中的敏感数据或加密数据的对称密钥"错误的解决
- 计算数据库中数据总和的存储过程
- 将数据库中的数据生成插入语句(用于数据的导出与导入)
- 基于winform的二进制图片数据的存取(用于数据库照片的读写处理)