keepalived+nginx+nginx web script实现双主模型 推荐
2014-05-25 19:52
295 查看
思路: 1. 配置双机互信(非必须) 2. 添加主机名解析 3. 设置时间同步 4. 实现主机的高可用 5. 实现web服务器的高可用 6. 测试 架构: Master1: 172.16.16.16 node2.ja.com 软件: keepalived+nginx 网卡Vmnet2 Master2: 172.16.16.17 node3.ja.com 软件: keepalived+nginx 网卡Vmnet2 宿主机:仅作为测试使用的客户端一、准备工作
1)编辑/etc/hosts文件,分别为node3,node4添加主机名称解析,添加内容如下:
172.16.16.16 node2.ja.com 172.16.16.17 node3.ja.com2)配置双机互信,实现免密钥、免密码登录(方便以后的管理,如软件安装,文件分发)
node2: ssh-keygen -t rsa -P '' ssh-copy-id -i .ssh/id_rsa.pub node4.ja.com node3: ssh-keygen -t rsa -P '' ssh-copy-id -i .ssh/id_rsa.pub node3.ja.com3)时间同步
命令行同步,立即生效:
ssh node2.ja.com 'ntpdate 172.16.0.1';ntpdate 172.16.0.1设置定时任务,永久有效:
echo '*/5 * * * * /usr/sbin/ntpdate 172.16.0.1 &>/dev/null;/sbin/hwclock -w' >>/var/spool/cron/root4)分别为node2,node3安装keepalived和nginx
yum -y install keepalived nginx ipvsadm
二、编写外部脚本
1)主机维护脚本(这个配置在keepalived.conf中)
vrrp_script chk_mantaince { # chk_mantaince定义脚本的名称,可随意取
script "[[ -f /etc/keepalived/down ]] && exit 1 || exit 0"
#命令(其实这里可以是自己定义好的脚本路径也可以是判断命令)#这里的意思是如果在这个文件下有down这个文件就表示期望这 个节点为备用状态。
interval 1 #每隔1秒钟执行一次
weight -2 #一旦命令执行失败,权重降低2个
}2)keepalived状态转换通知脚本(这个放在/etc/keepalived/命目录下)这个脚本2个节点都要有[root@node2 keepalived]# cat notify.sh
#!/bin/bash
# Author: liuyuan <www.ja.com>
# description: An example of notify script
#
vip=172.16.16.10
contact='root@localhost'
notify() {
mailsubject="`hostname` to be $1: $vip floating"
mailbody="`date '+%F %H:%M:%S'`: vrrp transition, `hostname` changed to be $1"
echo $mailbody | mail -s "$mailsubject" $contact
}
case "$1" in
master)
notify master
/etc/rc.d/init.d/nginx start
exit 0
;;
backup)
notify backup
/etc/rc.d/init.d/nginx stop
exit 0
;;
fault)
notify fault
/etc/rc.d/init.d/nginx stop
exit 0
;;
*)
echo 'Usage: `basename $0` {master|backup|fault}'
exit 1
;;
esac添加可执行权限chmod +x notify.sh |
这个脚本2个节点都要有[root@node2 keepalived]# cat monitor_nginx.sh #!/bin/bash #Author: liuyuan Contact='root@localhost' Subject="Web server is bad" Mailbody="Date: `date +"%F %T"` Event: 'nginx is down' Host: `uname -n`" while true;do nginx_status=`killall -0 nginx &>/dev/null` if [ `echo $?` -ne 0 ];then echo $Mailbody|mail -s $Subject $Contact /etc/init.d/nginx start &> /dev/null fi sleep 5 done添加可执行权限 chmod +x monitor_nginx.sh |
node2上keepalived的完整配置如下:
[root@node2 keepalived]# cat keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
root@localhost
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id LVS_DEVEL
}
vrrp_script chk_maintaince {
script "[[ -e /etc/keepalived/down ]] && exit 1 || exit 0"
interval 1
weight -2
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 2222
}
virtual_ipaddress {
172.16.16.10
}
track_script {
chk_maintaince
}
notify_master "/etc/keepalived/notify.sh master"
notify_backup "/etc/keepalived/notify.sh backup"
notify_fault "/etc/keepalived/notify.sh fault"
}
vrrp_instance VI_2 {
state BACKUP
interface eth0
virtual_router_id 52
priority 99
advert_int 1
authentication {
auth_type PASS
auth_pass 3333
}
virtual_ipaddress {
172.16.16.11
}
track_script {
chk_maintaince
}
notify_master "/etc/keepalived/notify.sh master"
notify_backup "/etc/keepalived/notify.sh backup"
notify_fault "/etc/keepalived/notify.sh fault"
}
real_server 172.16.16.16 80 {
weight 1
HTTP_GET {
url {
path /
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
real_server 172.16.16.17 80 {
weight 1
HTTP_GET {
url {
path /
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
} |
vrrp_instance VI_1中 state BACKUP priority 99 vrrp_instance VI_1中 state MASTER priority 100注: 相同实例通信时的密码要相同;每个实例都要有一个独立的VIP地址
定义完检测脚本还需在实例中调用检测跟踪机制,这样检测脚本才会生效;
主、备节点的priority大小和 weight的大小一定要合适,不然vip会转移失败的;
将nginx web服务的守护进程调入后台运行
[root@node2 keepalived]# nohup sh monitor_nginx.sh & [1] 32071 [root@node3 keepalived]# nohup sh monitor_nginx.sh & [1] 30106
查看正在后台运行的nginx web服务的守护进程
[root@node2 keepalived]# ps -elf|grep "sh monitor_nginx.sh"|grep -v grep 0 S root 32071 30943 0 80 0 - 26523 wait 13:29 pts/4 00:00:00 sh monitor_nginx.sh [root@node3 keepalived]# ps -elf|grep "sh monitor_nginx.sh"|grep -v grep 0 S root 30106 27606 0 80 0 - 26523 wait 02:13 pts/0 00:00:00 sh monitor_nginx.sh
查看nginx的80端口是否启用
[root@node2 keepalived]# lsof -i:80 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME nginx 31880 root 6u IPv4 160257 0t0 TCP *:http (LISTEN) nginx 31882 nginx 6u IPv4 160257 0t0 TCP *:http (LISTEN) [root@node3 keepalived]# lsof -i:80 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME nginx 29815 root 6u IPv4 310255 0t0 TCP *:http (LISTEN) nginx 29817 nginx 6u IPv4 310255 0t0 TCP *:http (LISTEN)
四、主机和服务高可用测试
测试双主高可用前的测试:确保2个web服务器均可正常提供服务
分别在浏览器输入2个VIP的地址看是否可以看到各自对应的web页面
主节点1 VIP:http://172.16.16.10/ 参考截图:双主-node2
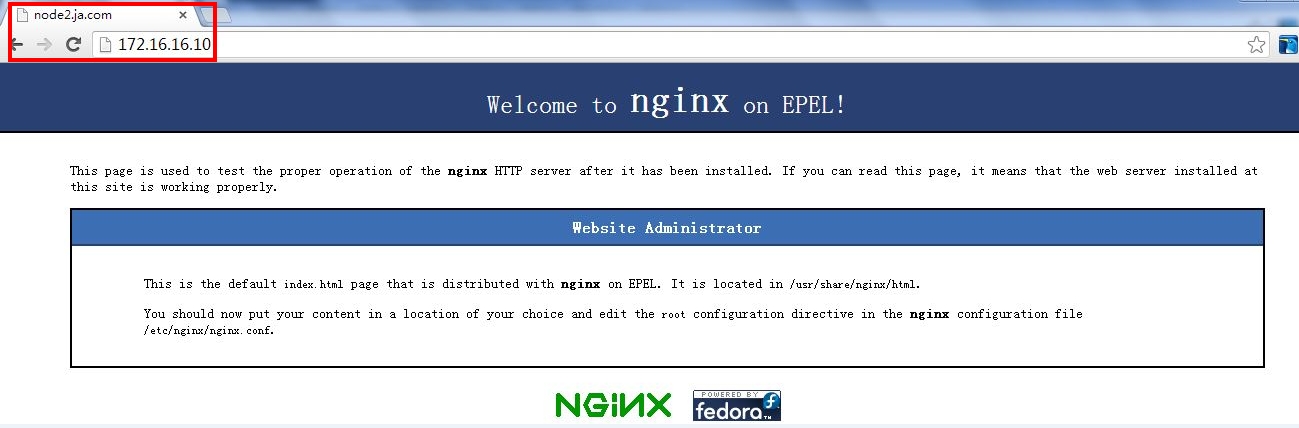
主节点2 VIP: http://172.16.16.11/ 参考截图:双主-node3
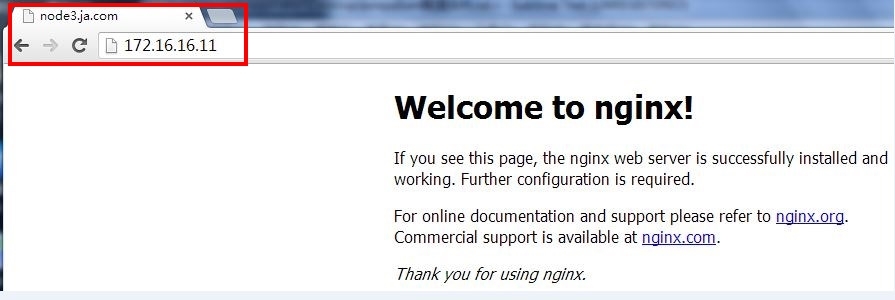
测试主机(node2,node3)的高可用
思路:
(1)停止node2的keepalived服务或者直接将node2的虚拟机挂起,模拟keepalived应用程序或服务器故障
验证node2上的VIP地址是否已经成功转移到node3
(2)在浏览器分别使用http://172.16.16.10/和http://172.16.16.11/访问web资源,验证是否可以看到node3上提供的web服务
参考截图10,11
截图10:
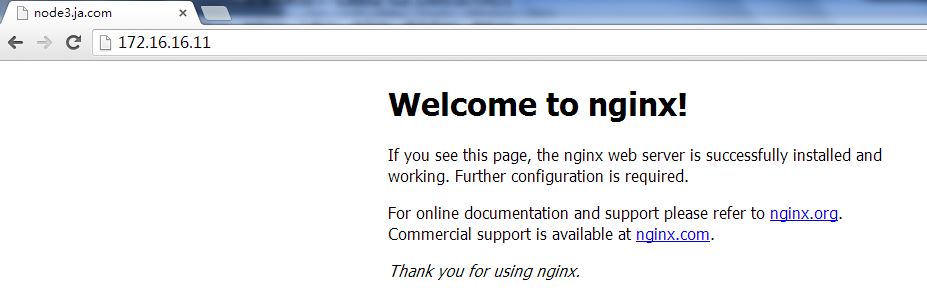
截图11:
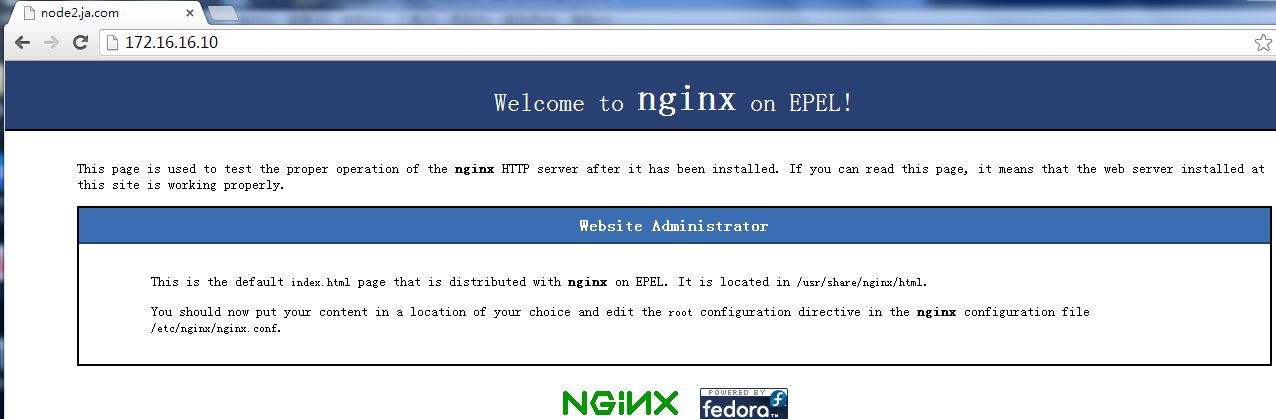
(3)当node2的keepalived再次启动后,又会把原有的VIP资源抢夺回来,web页面也会是自己提供的
停掉node2上的keepalived服务
[root@node2 keepalived]# service keepalived stop查看node2上的VIP是否成功转移
[root@node2 keepalived]# ip addr show|grep 'eth0' 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 inet 172.16.16.16/16 brd 172.16.255.255 scope global eth0
查看node3是否成功接收了从node2转移来的VIP
[root@node3 keepalived]# ip addr show|grep 'eth0' 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 inet 172.16.16.17/16 brd 172.16.255.255 scope global eth0 inet 172.16.16.11/32 scope global eth0 inet 172.16.16.10/32 scope global eth0如上,可以证明VIP资源已成功转移.
当node2的keepalived再次启动后,又会把原有的VIP资源抢夺回来,web页面也会是自己提供的
[root@node2 keepalived]# service keepalived start
[root@node2 keepalived]# ip addr show|grep 'eth0' 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 inet 172.16.16.16/16 brd 172.16.255.255 scope global eth0
inet 172.16.16.10/32 scope global eth0
访问http://172.16.16.10,看页面是否是node2自己提供的
参考截图12
在node3上执行如上的操作,那么node3上的VIP将会转移到node2,另外在访问web时,会看到node2提供的页面,这个操作就交给你了
至此,模拟keepalived应用程序故障后,实现主机的高可用已成功实现
下面我们将模拟nginx 提供的web的高可用
思路:
由于我在前面写的是一个守护进程形式的脚本,所以当服务器上nginx web服务,停掉的时候,守护进程脚本就会尝试去启动nginx,
这可以应对nginx服务意外终止的情况;除非,监控nginx的守护进程脚本被停止了
[root@node2 ~]# jobs -l [1]+ 32071 Running nohup sh monitor_nginx.sh & [root@node3 ~]# jobs -l [1]+ 30106 Running nohup sh monitor_nginx.sh &
停掉node2上的nginx服务
[root@node2 ~]# service nginx stop Stopping nginx: [ OK ] [root@node2 ~]# service nginx stop [root@node2 ~]# lsof -i:80 [root@node2 ~]# lsof -i:80 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME nginx 7598 root 6u IPv4 173882 0t0 TCP *:http (LISTEN) nginx 7600 nginx 6u IPv4 173882 0t0 TCP *:http (LISTEN)为了看到守护进程尝试启动nginx web服务的瞬间,我们在停掉nginx后,要立即执行端口反查命令,看nginx的web服务是否在线
至此,nginx web服务的高可用和主机的高可用已成功实现。
###################################################################################################

相关文章推荐
- keepalived+nginx+nginx web script实现双主模型
- keepalived+nginx+nginx web script实现双主模型
- keepalived + haproxy 实现web 双主模型的高可用负载均衡 推荐
- keepalived+nginx 双主模型实现高可用服务
- keepalived架设简单高可用的nginx的web服务器 ----那些你不知道的秘密 推荐
- Web 负载均衡解决方案——HAproxy+keepalived实现高可用负载均衡 推荐
- 基于lvs的DR模型搭建高可用的web服务,并部署wordpress,(附有脚本实现健康状态检测的代码) 推荐
- 基于keepalived实现Director、ipvs、Nginx的高可用以及Nginx的双主模型 推荐
- 基于keepalived主从模型实现Nginx的高可用
- keepalived + haproxy 实现web 双主模型的高可用负载均衡--转
- nginx+keepalived实现nginx双主高可用的负载均衡 推荐
- keepalived + haproxy 实现web 双主模型的高可用负载均衡--转
- keepalived + web高可用集群实现主从模型、双主模型配置
- HAProxy基于KeepAlived实现Web高可用及动静分离 推荐
- NginX+keepalived实现高可用 推荐
- keepAlived+nginx实现高可用双主模型LVS
- keepalived实现LVS的高可用以及实现web服务的高可用(主从模型、双主模型)
- keepalived+nginx(反向代理)实现web高可用
- 基于keepalived实现LVS高可用以及Web服务高可用 推荐
- 手把手让你实现开源企业级web高并发解决方案(lvs+heartbeat+varnish+nginx+eAccelerator+memcached)续 推荐