Accelerated C++学习笔记6<使用顺序容器并分析字符串>
2014-05-21 01:42
281 查看
第5章 使用顺序容器并分析字符串
本章主要讲解如何使用库容器。1、按类别来区分学生
1)首先,我们要求不仅希望算出学生的成绩,同时还想知道哪些学生不能通过这门课程。
<span style="font-family:KaiTi_GB2312;">vector<Student_info> extract_fails(vector<Student_info>& students)
{
vector<Student_info> pass, fail;
#ifdef _MSC_VER
for(std::vector<Student_info>::size_type i = 0;
#else
for(vector<Student_info>::size_type i = 0;
#endif
i != students.size(); ++i)
if(fgrade(students[i]))
fail.push_back(students[i]);
else
pass.push_back(students[i]);
students = pass;
return fail; //这个函数创建了两个向量,分别保存了成绩及格和成绩不及格的学生的数据
}</span>程序说明:
一个一个检查所有学生的记录,之后在两个向量pass,fail中选择一个来存放它,这两个向量中的一个是用来存储成绩及格的学生记录的,另一个则是为成绩不及格的学生记录而设的。该程序能完成我们的任务,但是它不足的地方在于需要足够的内存来保存每一个学生记录的两个副本,而且不断增加pass和fail的长度,原先的记录依然存在。
2)就地删除元素
<span style="font-family:KaiTi_GB2312;">//功能改进:就地删除元素
#include <vector>
#include "Student_info.h"
#include "grade.h"
using std::vector;
//第二次尝试,函数正确,不过可能很慢
vector<Student_info> extract_fails(vector<Student_info>& students)
{
vector<Student_info> fail;
#ifdef _MSC_VER
std::vector<Student_info>::size_type i = 0;
#else
vector<Student_info>::size_type i = 0;
#endif
//不变式:students的索引在[0,i)中原数所代表的成绩是及格的
while(i != students.size())
{
if(fgrade(students[i]))
{
fail.push_back(students[i]);
students.erase(students.begin() + i); //就是把第i个元素删除掉,这样会把索引指示向量中的下一个元素
}
else
++i;
}
return fail;
}</span>程序说明:
1)我们创建一个名叫fail的局部向量来保存我们想要返回的值,如果成绩及格,则我们不用去管这个记录,如果不及格,那我们就把它的一个副本添加给fail并从students中删除它;
2)student.begin()的返回值指示了向量的第一个元素,也就是索引为0的那个;students.erase(students.begin() + i);表示对erase的调用会把students中的第i个元素删除掉。
2、迭代器
一个迭代器是一个值,它能够:识别一个容器以及容器中的一个元素;让我们检查存储在这个元素中的值;提供操作来移动在容器中的元素;采用对应于容器所能够有效处理的方式来对可用的操作进行约束。
<span style="font-family:KaiTi_GB2312;">#include <vector>
#include "Student_info.h"
#include "grade.h"
using std::vector;
//用迭代器来代替索引
vector<Student_info> extract_fails(vector<Student_info>& students)
{
vector<Student_info> fail;
#ifdef _MSC_VER
std::vector<Student_info>::iterator iter = students..begin();
#else
vector<Student_info>::iterator iter = students.begin();
#endif
while(iter != students.end()) //这里要注意是students.end()而不是end_iter
{
if(fgrade(*iter))
{
fail.push_back(*iter); //间接引用迭代器来获取元素
iter = students.erase(iter); //会使iter指向被删除元素后面的那个元素
}
else
++iter;
}
return fail;
}</span>程序说明:这里需要注意不能写成while(iter != end_iter)
3、list类型
vector(向量)是为了快速随机访问而被优化的,同样地优化list类型之后,我们就可以在容器中的任何位置快速地插入和删除元素了,如果只是顺序地访问容器的话,list的速度就会比vector慢,如果容器只是从尾部增长和缩小的话,那么vector的性能就会比list好。vector支持而list不支持的一个非常重要的操作就是索引。
<span style="font-family:KaiTi_GB2312;">#include <list>
#include "Student_info.h"
#include "grade.h"
using std::list;
//版本4:用list代替vector list类型是为了高效地在容器中任何位置插入和删除元素而被优化
list<Student_info> extract_fails(list<Student_info>& students)
{
list<Student_info> fail;
#ifdef _MSC_VER
std::list<Student_info>::iterator iter = students.begin();
#else
list<Student_info>::iterator iter = students.begin();
#endif
while(iter != students.end())
{
if(fgrade(*iter))
{
fail.push_back(*iter);
iter = students.erase(iter);
}
else
++iter;
}
return fail;
}</span>程序分析:
1)与那些对vector的操作相比,对list的操作在某些方面会有所不同,而最大的差别在于对迭代器进行得某些操作所产生的影响是彼此不同的——如果我们从vector中删除一个元素,那所有指向被删除的元素或随后的元素的迭代器都会失效,使用push_back来给vector添加一个元素会使所有指向这个vector的迭代器失效;但是对于list来说,erase和push_back操作并不会使指向其他元素的迭代器失效,只有指向已经删除的元素的迭代器才会失效。
2)list类的迭代器并不支持完全随机的访问,所以我们不能使用标准库的sort函数来为存储在list中的值排序,list类提供了自己的sort成员函数,这个函数使用了一个优化的算法来为存储在list中的数值排序。
4、分割字符串
到目前为止,我们只是对字符串做了一些工作,创建、读、把它们连接起来、输出它们以及查看它们长度,所有这些我们都是把它当做单独的实体来处理,我们想忽略字符串的详细内容,把字符串看成一种特殊的容器,它仅仅包含字符,而且它支持了某些容器的操作。索引就是它支持的操作之一。
任务:我们现在希望把一个输出分割成单词,并且单词间用空白分隔开(空格、制表键、或行结尾),我们有时候实际应用中会希望一次过读一整行输入并检查在这一行中的每一个单词。
<span style="font-family:KaiTi_GB2312;">//分割字符串
#include <cctype> //这个头文件定义了isspace
#include <string>
#include <vector>
#include "split.h"
using std::vector;
using std::string;
#ifndef _MSC_VER
using std::isspace;
#endif
vector<string> split(const string& s)
{
vector<string> ret;
typedef string::size_type string_size;
string_size i = 0;
//不变式:我们已经处理了索引域(先前的i , j)中的字符
while(i != s.size())
{
//忽略前端的空白
//不变式:索引域[先前的i, 当前的i)中的所有字符都是空格
while(i != s.size() && isspace(s[i])) //如果我们还未达到字符串的尾部,并且s[i]是一个空白字符的话开始加一操作直到不是空白为止
++i;
//找到下一个单词的终结点
string_size j = i;
//不变式:索引域[先前的j, 当前的j)中的任一个字符都不是空格
while(j != s.size() && !isspace(s[j])) //如果我们还未达到字符串的尾部,并且s[J]不是一个空白字符的话开始加一操作直到是空白为止
++j;
//如果找到了一些非空白字符
if (i != j) //如果我们耗尽了输入,那么ij都会等于s.size()
{
//从i开始复制s的j-1个字符
ret.push_back(s.substr(i, j-i));
i = j;
}
}
return ret;
}</span>程序说明:push_back参数是一个索引和一个长度,它的作用是创建一个新的字符串,而这个新字符串包含了来自原始字符串的一个副本。substr从第一个参数给定的索引开始复制字符,复制字符个数由第二个参数指定。
5、测试split函数
<span style="font-family:KaiTi_GB2312;">// test_split.cpp : 定义控制台应用程序的入口点。
//功能:测试split函数
//时间:2014.5.20
#include "stdafx.h"
#include <cctype>
#include <iostream>
#include <string>
#include <vector>
//#include "split.h"
using namespace std;
#ifndef _MSC_VER
using std::isspace;
#endif
vector<string> split(const string& s)
{
vector<string> ret;
typedef string::size_type string_size;
string_size i = 0;
//不变式:我们已经处理了索引域(先前的i , j)中的字符
while(i != s.size())
{
//忽略前端的空白
//不变式:索引域[先前的i, 当前的i)中的所有字符都是空格
while(i != s.size() && isspace(s[i])) //如果我们还未达到字符串的尾部,并且s[i]是一个空白字符的话开始加一操作直到不是空白为止
++i;
//找到下一个单词的终结点
string_size j = i;
//不变式:索引域[先前的j, 当前的j)中的任一个字符都不是空格
while(j != s.size() && !isspace(s[j])) //如果我们还未达到字符串的尾部,并且s[J]不是一个空白字符的话开始加一操作直到是空白为止
++j;
//如果找到了一些非空白字符
if (i != j) //如果我们耗尽了输入,那么ij都会等于s.size()
{
//从i开始复制s的j-1个字符
ret.push_back(s.substr(i, j-i));
i = j;
}
}
return ret;
}
int _tmain(int argc, _TCHAR* argv[])
{
string s;
//读并分割每一行输入
while(getline(cin, s))
{
vector<string> v = split(s);
//输出v中的每一个单词
#ifdef _MSC_VER
for(std::vector<string>::size_type i = 0; i != v.size(); ++i)
#else
for(vector<string>::size_type i = 0; i != v.size(); ++i)
#endif
cout << v[i] << endl;
}
return 0;
}
</span>运行结果:
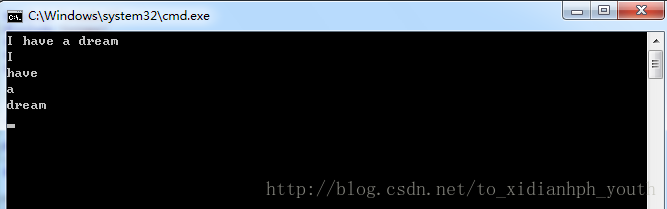
程序说明:使用函数getline来读输入直到行尾。
6、连接字符串
我们前几章编写了一个程序输出了位于一星号图中央的姓名,但是我们没有真正创建过一个字符串来保存我们程序的输出,相反我们要分别输出图形各部分,而且是一次输出一部分,之后我们还要用输出文件把这些片段组合成一幅图案。
1)为图案装框
<span style="font-family:KaiTi_GB2312;">//为图像装框
string::size_type width(const vector<string>& v) //找出向量中最长的字符串的长度,maxlen将保存了v的最长的字符串的长度
{
string::size_type maxlen = 0;
#ifdef _MSC_VER
for(std::vector<string>::size_type i = 0; i != v.size(); ++i)
#else
for(vector<string>::size_type i = 0; i != v.size(); ++i)
#endif
maxlen = max(maxlen, v[i].size());
return maxlen;
}
vector<string> frame(const vector<string>& v) //让函数创建一个新图案而不是修改原来的图案
{
vector<string> ret;
string::size_type maxlen = width(v);
string border(maxlen + 4,'*');
//输出顶部的边框
ret.push_back(border);
//输出内部的行,每一行都用一个星号和一个空格来框起
#ifdef _MSC_VER
for(std::vector<string>::size_type i = 0; i != v.size(); ++i)
{
#else
for(vector<string>::size_type i = 0; i != v.size(); ++i)
{
#endif
ret.push_back("* " + v[i] + string(maxlen - v[i].size(), ' ') + " *");
}
//输出底部的边框
ret.push_back(broder);
return ret;
}</span>2)纵向连接
<span style="font-family:KaiTi_GB2312;">/纵向连接
vector<string> vcat(const vector<string>& top,
const vector<string>& bottom) //定义ret来作为top的一个复制,把bottom的每一个元素都添加给ret
{
//复制顶部图案
vector<string> ret = top;
//复制整个顶部图案
#ifdef _MSC_VER
for(std::vector<string>::const_iterator it = bottom.begin();
#else
for(vector<string>::const_iterator it = bottom.begin();
#endif
it != bottom.end(); ++ it);
ret.push_back(*it);
return ret;
}</span>程序说明:1)定义一个ret来作为top的一个复制,把bottom的每一个元素都添加给ret,之后返回ret以作为函数的结果。
2)这种把一个容器的元素的复制插入到另一个容器中,很常见,实际上就是在添加元素,也可以把这个动作看成是在容器末尾插入它们。
所以可用下面语气代替
<span style="font-family:KaiTi_GB2312;">ret.insert(ret.end(), bottom.begin(), bottom.end());</span>
3)横向连接
这个需要考虑尺寸问题,如果左侧图案的行数比右侧的少,我们必须要填充输出的左侧以占据这些空行,如果是左侧图案较长,那就只需要把它的字符串复制到新的图案中,并没有必要填充右侧。
<span style="font-family:KaiTi_GB2312;">//横向连接
vector<string> hcat(const vector<string>& left, const vector<string>& right)
{
vector<string> ret;
//对width(left)加1,在两幅图案之间留一个空格
string::size_type width1 = width(left) + 1;
//用来遍历left和right的索引
#ifdef _MSC_VER
std::vector<string>::size_type i = 0, j = 0;
#else
vector<string>::size_type i = 0, j = 0;
#endif
//循环操作直到我们查看完了两幅图案的所有行
while(i != left.size() || j != right.size())
{
//构造新字符串来保存字符,这些字符来自两幅输入图案
string s;
//如果右侧图案还有待复制的行,那就复制一行
if(i != left.size())
s = left[i++];
//填充至适当的长度
s += string(width1 - s.size(), ' ');
//如果左侧图案还有待复制的行,那就复制一行
if(j != right.size())
s += right[j++]
//把s添加到我们正在创建的图案中
ret.push_back(s);
}
return ret;
}</span>7、设计和实现一个程序来产生一个置换索引
<span style="font-family:KaiTi_GB2312;">// lesson5_2.cpp : 定义控制台应用程序的入口点。
//功能:设计和实现一个程序来产生一个置换索引
//时间:2014.5.15
#include "stdafx.h"
#include <algorithm>
#include <iomanip>
#include <iostream>
#include <string>
#include <vector>
//#include "split.h"
using namespace std;
vector<string> split(const string& s)
{
vector<string> ret;
typedef string::size_type string_size;
string_size i = 0;
//不变式:我们已经处理了索引域(先前的i , j)中的字符
while(i != s.size())
{
//忽略前端的空白
//不变式:索引域[先前的i, 当前的i)中的所有字符都是空格
while(i != s.size() && isspace(s[i])) //如果我们还未达到字符串的尾部,并且s[i]是一个空白字符的话开始加一操作直到不是空白为止
++i;
//找到下一个单词的终结点
string_size j = i;
//不变式:索引域[先前的j, 当前的j)中的任一个字符都不是空格
while(j != s.size() && !isspace(s[j])) //如果我们还未达到字符串的尾部,并且s[J]不是一个空白字符的话开始加一操作直到是空白为止
++j;
//如果找到了一些非空白字符
if (i != j) //如果我们耗尽了输入,那么ij都会等于s.size()
{
//从i开始复制s的j-1个字符
ret.push_back(s.substr(i, j-i));
i = j;
}
}
return ret;
}
//第一个过程:读入输入的每一行并对每一行输入产生一个轮转的集合,每一个轮转都可以把输入的下一个单词防止第一个位置上,并且把原先的第一个单词旋转到短语的末尾。
struct Rotation
{
vector<string>::size_type first;
vector<string> words;
};
vector<string> read_lines()
{
vector<string> lines;
string line;
while (getline(cin,line)) //getline来读输入直至行尾,把读入的参数放进line这个字符串里面
lines.push_back(line);
return lines;
}
vector<Rotation> rotate_line(string line)
{
vector<Rotation> rotations;
vector<string> words = split(line); //读并分割每一行的输入
for(vector<string>::size_type i = 0;i < words.size(); ++i)
{
Rotation rot = {words.size() - i, words};
rotations.push_back(rot);
rotate(words.begin(),words.begin() + 1, words.end());
}
return rotations;
}
vector<Rotation> rotate_lines(vector<string> lines)
{
vector<Rotation> rotations;
for(vector<string>::size_type i = 0;i < lines.size(); ++i)
{
vector<Rotation> new_rotations = rotate_line(lines[i]);
rotations.insert(rotations.end(), new_rotations.begin(), new_rotations.end());
}
return rotations;
}
//第二步:对这些轮转集合排序
bool compare(const Rotation& x, const Rotation& y)
{
return x.words < y.words;
}
//第三步:反向轮转并输出置换索引,其中包含了查找分隔符号、把短语重新连接到一起以及以正确的格式输出短语等操作
void print_rotations(vector<Rotation> rotations)
{
vector<string> first_halves;
vector<string> second_halves;
string::size_type max_first_half_width = 0;
for(vector<Rotation>::size_type i = 0;i < rotations.size(); ++i)
{
Rotation rot = rotations[i];
string first_half, second_half;
for(vector<string>::size_type j = rot.first; j < rot.words.size(); ++j)
first_half += rot.words[j] + " ";
first_halves.push_back(first_half);
if(first_half.size() > max_first_half_width)
max_first_half_width = first_half.size();
for(vector<string>::size_type j = 0; j < rot.first; ++j)
second_half += rot.words[j] + " ";
second_halves.push_back(second_half);
}
for(vector<string>::size_type i = 0; i < first_halves.size(); ++i)
{
cout << setw(max_first_half_width);
cout << first_halves[i];
cout << "\t";
cout << second_halves[i];
cout << endl;
}
}
int _tmain(int argc, _TCHAR* argv[])
{
vector<string> lines = read_lines();
vector<Rotation> rotations = rotate_lines(lines);
sort(rotations.begin(), rotations.end(), compare);
print_rotations(rotations);
return 0;
}
</span>运行结果:
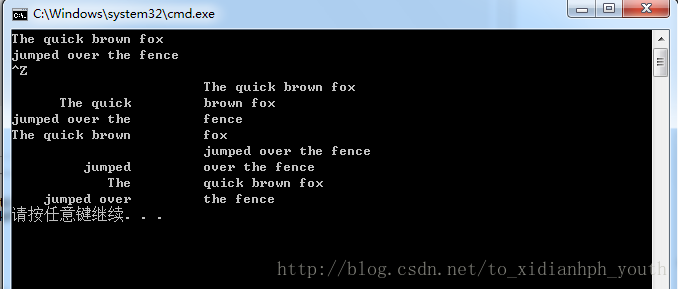
8、编写一个新的程序来计算学生的成绩,要求使用向量来抽取不及格学生的记录,之后再编写这个程序的另外一个版本,要求使用list.
1)使用vector
<span style="font-family:KaiTi_GB2312;">// lesson5_3_vector.cpp : 定义控制台应用程序的入口点。
//功能:编写一个新的程序来计算学生的成绩,要求使用向量来抽取不及格学生的记录
//时间:2014.5.21
#include "stdafx.h"
#include <algorithm>
#include <vector>
#include <iostream>
#include <string>
#include <ctime>
#include "Student_info.h"
#include "grade.h"
using namespace std;
using std::max;
vector<Student_info>extract_fails(vector<Student_info>& students)
{
vector<Student_info> fail;
vector<Student_info>::iterator iter = students.begin();
while(iter != students.end())
{
if(fgrade(*iter))
{
fail.push_back(*iter);
iter = students.erase(iter);
}
else
++iter;
}
return fail;
}
int _tmain(int argc, _TCHAR* argv[])
{
vector<Student_info> vs;
Student_info s;
string::size_type maxlen = 0;
while(read(cin,s))
{
maxlen = max(maxlen, s.name.size());
vs.push_back(s);
}
sort(vs.begin(), vs.end(), compare);
clock_t start = clock();
vector<Student_info> fails = extract_fails(vs);
clock_t elapsed = clock() - start;
cout << "Elapsed: " << elapsed << endl;
return 0;
}
</span>2)使用list
<span style="font-family:KaiTi_GB2312;">// lesson5_3_list.cpp : 定义控制台应用程序的入口点。
//功能:编写一个新的程序list来计算学生的成绩,要求使用向量来抽取不及格学生的记录
//时间:2014.5.21
#include "stdafx.h"
#include <algorithm>
#include <list>
#include <iostream>
#include <string>
#include <ctime>
#include "Student_info.h"
#include "grade.h"
using namespace std;
using std::max;
list<Student_info>extract_fails(list<Student_info>& students)
{
list<Student_info> fail;
list<Student_info>::iterator iter = students.begin();
while(iter != students.end())
{
if(fgrade(*iter))
{
fail.push_back(*iter);
iter = students.erase(iter);
}
else
++iter;
}
return fail;
}
int _tmain(int argc, _TCHAR* argv[])
{
list<Student_info> vs;
Student_info s;
string::size_type maxlen = 0;
while(read(cin,s))
{
maxlen = max(maxlen, s.name.size());
vs.push_back(s);
}
//sort(vs.begin(), vs.end(), compare);
vs.sort(compare);
clock_t start = clock();
list<Student_info> fails = extract_fails(vs);
clock_t elapsed = clock() - start;
cout << "Elapsed: " << elapsed << endl;
return 0;
}
</span>9、使用一个typedef,我们就能编写出上面的程序的一个既可以基于向量解决方案又可以基于list解决方案的版本
<span style="font-family:KaiTi_GB2312;">// lesson5_4.cpp : 定义控制台应用程序的入口点。
//功能:使用一个typedef,我们就能编写出上面的程序的一个既可以基于向量解决方案又可以基于list解决方案的版本
//时间:2014.5.21
#include "stdafx.h"
#include <algorithm>
#include <list>
#include <vector>
#include <iostream>
#include <string>
#include <ctime>
#include "Student_info.h"
#include "grade.h"
using namespace std;
typedef list<Student_info> Student_infos;
//typedef vector<Student_info> Student_infos;
Student_infos extract_fails(Student_infos& students)
{
Student_infos fail;
Student_infos::iterator iter = students.begin();
while(iter != students.end())
{
if(fgrade(*iter))
{
fail.push_back(*iter);
iter = students.erase(iter);
}
else
++iter;
}
return fail;
}
int _tmain(int argc, _TCHAR* argv[])
{
Student_infos vs;
Student_info s;
string::size_type maxlen = 0;
while(read(cin, s))
{
maxlen = max(maxlen, s.name.size());
vs.push_back(s);
}
//vs.sort(compare);
Student_infos fails = extract_fails(vs);
for(Student_infos::const_iterator i = fails.begin(); i != fails.begin(); i != fails.end(); ++i)
cout << i->name << " " << grade(*i) << endl;
return 0;
}
</span>10、编写一个程序来输出在输入中的单词,输出的格式是:先输出全部的小写单词,之后再输出大写单词
<span style="font-family:KaiTi_GB2312;">// lesson5_6.cpp : 定义控制台应用程序的入口点。
//功能:编写一个程序来输出在输入中的单词,输出的格式是:先输出全部的小写单词,之后再输出大写单词
//时间:2014.5.22
#include "stdafx.h"
#include <iostream>
#include <string>
#include <vector>
using namespace std;
//判断是否有大写字母
bool has_uppercase(const string& word)
{
for(string::size_type i = 0; i != word.size(); ++i)
if(isupper(word[i]))
return true;
return false;
}
//输出输入的字符串
void print_string_vector(const vector<string>& v)
{
for(vector<string>::const_iterator i = v.begin(); i != v.end(); ++i)
cout << *i <<endl;
}
int _tmain(int argc, _TCHAR* argv[])
{
string s;
vector<string> no_uppercase;
vector<string> uppercase;
while(cin >> s)
if(has_uppercase(s))
uppercase.push_back(s);
else
no_uppercase.push_back(s);
cout << "\nNo uppercase letters:" << endl;
print_string_vector(no_uppercase);
cout << "Has uppercase letters:" << endl;
print_string_vector(uppercase);
return 0;
}
</span>运行结果:
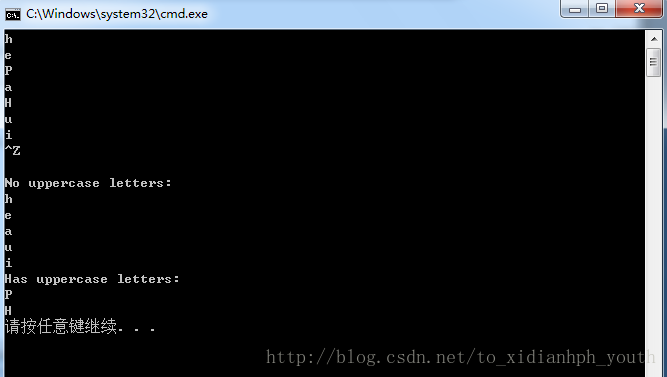
程序说明:利用了issupper 功能:判断字符是否为大写英文字母。
注意:为了与后面两个程序进行对比,我把这个情况设为一个比较,二种情况输出。
11、编写一个程序,让它找出一个单词集中的所有的回文并且找出最长的回文(回文是指一种顺读和倒读都一样的单词)
<span style="font-family:KaiTi_GB2312;">// lesson5_7.cpp : 定义控制台应用程序的入口点。
//功能:编写一个程序,让它找出一个单词集中的所有的回文并且找出最长的回文(回文是指一种顺读和倒读都一样的单词)
#include "stdafx.h"
#include <algorithm>
#include <iostream>
#include <string>
#include <vector>
using namespace std;
//判断是否问回文
bool is_palindrome(const string& word)
{
string reversed;
reverse_copy(word.begin(), word.end(), back_inserter(reversed));
return(word == reversed);
}
int _tmain(int argc, _TCHAR* argv[])
{
vector<string> palindromes;
string longest_palindrome;
string s;
while(cin >> s)
if(is_palindrome(s))
{
palindromes.push_back(s);
if(s.length() > longest_palindrome.length())
longest_palindrome = s;
}
cout << "\nPalindromes:" << endl;
for(vector<string>::const_iterator it = palindromes.begin(); it != palindromes.end(); ++it)
cout << *it << endl;
cout << "Longest:" << longest_palindrome << endl;
return 0;
}
</span>运行结果:

程序说明:reverse_copy (beg, end, dest) ;
操作前:[beg,end)标示输入序列.[dset,end)标示输出序列.
操作后:输入序列的所有的元素被翻转复制到输出序列中.
返回值:返回指向输出序列中最后一个被赋值的元素的下一个位置的迭代器.
备注:必须保证输出序列的大小不小于输入序列的大小.
back_inserter 是iterator适配器,它使得元素被插入到作为实参的某种容器的尾部,如vector等
注意:这里归结为一个输入比较,一个成立时输出最长。注意if的括号。
11、功能:编写一个程序来判断在一个单词中是否包含有上行字母或者下行字母
<span style="font-family:KaiTi_GB2312;">// lesson5_8.cpp : 定义控制台应用程序的入口点。
//功能:编写一个程序来判断在一个单词中是否包含有上行字母或者下行字母
//时间:2014.5.22
#include "stdafx.h"
#include <iostream>
#include <string>
#include <vector>
using namespace std;
const string upside_words = "bdfhklt";
const string downside_words = "gjpqy";
bool has_words(const string& word, const string& word1)
{
for(string::size_type i = 0; i != word.size(); ++i)
for(string::size_type j = 0; j != word1.size(); ++j)
if(word[i] == word1[j])
return true;
return false;
}
int _tmain(int argc, _TCHAR* argv[])
{
vector<string> has;
string longest_without_words;
string s;
while(cin >> s)
if(has_words(s,upside_words) || has_words(s,downside_words))
has.push_back(s);
else if (s.length() > longest_without_words.length())
longest_without_words = s;
cout << "\nHas words: " << endl;
for(vector<string>::const_iterator it = has.begin(); it != has.end(); ++it)
cout << *it << endl;
cout << "Longest without words: " << longest_without_words << endl;
return 0;
}
</span>运行结果:

注意:这里归结为与已知双比较,且一个不成立时输出最长这里注意区分上面那个代码用else if
12、小结:本章主要掌握所有库容器的使用方法,并要懂得分析字符串。这里就涉及到很多容器和迭代器。
补充下迭代器操作:
1)*it 间接引用迭代器it来获取储存在容器中位于it所指示的位置的值(*it).x表示迭代器it所指示的对象的一个成员。
2)It->x等价于(*it).x
——To_捭阖_youth

相关文章推荐
- 第5章 使用顺序容器并分析字符串
- 使用 Split 方法分析字符串
- 如何:使用 Split 方法分析字符串(C# 编程指南)
- 小白学数据分析----->数据指标 累计用户数的使用
- 使用javap分析你的程序性能(以字符串拼接为例)
- Django ====> (转)Django如何使用request和response对象 Django结构及处理流程分析
- 使用hibernate心得——字符串超长的解决办法(setCharacterStream出现顺序问题)
- 标准模板库使用入门之顺序容器小记
- STL学习笔记之使用“交换技巧”来修整顺序容器的过剩容量
- 如何:使用 Split 方法分析字符串(C# 编程指南)
- 顺序容器插入元素时----避免使用存储的end迭代器
- 小结顺序容器的使用
- 在字符串中使用特殊字符<>"'&空格
- 使用 <map> 库创建关联容器
- PB中使用顺序容器list出现Data Abort
- java.util——使用StringTokenizer类分析字符串
- 使用值类型LazyString分析字符串
- 小结顺序容器的使用
- 小白学数据分析----->数据指标 累计用户数的使用
- 【整理】删除顺序容器(如:vector)中的重复字符串