概率图模型(PGM)学习笔记(四)-贝叶斯网络-伯努利贝叶斯-多项式贝叶斯
2014-05-18 23:14
435 查看
之前忘记强调了一个重要区别:条件概率链式法则和贝叶斯网络链式法则的区别
条件概率链式法则
%20=%20P%5Cleft(%20D%20%5Cright)P%5Cleft(%20%7BI%5Cleft%7C%20D%20%5Cright.%7D%5Cright)P%5Cleft(%20%7BG%5Cleft%7C%20%7BD,I%7D%20%5Cright.%7D%20%5Cright)P%5Cleft(%20%7BS%5Cleft%7C%20%7BD,I,G%7D%20%5Cright.%7D%5Cright)P%5Cleft(%20%7BL%5Cleft%7C%20%7BD,I,G,S%7D%20%5Cright.%7D%20%5Cright))
贝叶斯网络链式法则,如图1
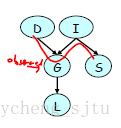
图1
%20=%20P%5Cleft(%20D%20%5Cright)P%5Cleft(%20I%20%5Cright)P%5Cleft(%20%7BG%5Cleft%7C%20%7BD,I%7D%5Cright.%7D%20%5Cright)P%5Cleft(%20%7BS%5Cleft%7C%20I%20%5Cright.%7D%20%5Cright)P%5Cleft(%20%7BL%5Cleft%7C%20G%20%5Cright.%7D%5Cright))
乍一看很容易觉得贝叶斯网络链式法则不就是大家以前学的链式法则么,其实不然,后面详述。
上一讲谈到了概率分布的因式分解
%20=%20P%5Cleft(%20%7BX%5Cleft%7C%20Z%20%5Cright.%7D%20%5Cright)P%5Cleft(%7BY%5Cleft%7C%20Z%20%5Cright.%7D%20%5Cright)%5C%5CP%5Cleft(%7BX%5Cleft%7C%20%7BY,Z%7D%20%5Cright.%7D%20%5Cright)%20=%20P%5Cleft(%20%7BX%5Cleft%7C%20Z%20%5Cright.%7D%20%5Cright)%5C%5CP%5Cleft(%7BY%5Cleft%7C%20%7BX,Z%7D%20%5Cright.%7D%20%5Cright)%20=%20P%5Cleft(%20%7BY%5Cleft%7C%20Z%20%5Cright.%7D%20%5Cright)%5C%5CP%5Cleft(%7BX,Y,Z%7D%20%5Cright)%20%5Cpropto%20%7B%5Cphi%20_1%7D%5Cleft(%20%7BX,Z%7D%20%5Cright)%5Cphi%20%5Cleft(%20%7BY,Z%7D%20%5Cright)%5Cend%7Barray%7D)
可以看到条件概率的独立性可以直接从概率分布表达式看出来。
我们已经用概率图模型把概率关系用图形化G表示了,独立性能从图上直接看出来吗?
当然,上一讲已经详细解释过了概率图中概率的流动关系.
当G已知时,S和D之间的概率才能相互影响。下面定义一个依赖隔离的概念。
依赖隔离(D-separation)
在Z已知的情况下,X与Y之间没有通路。则称之为X与Y依赖隔离。记作
)
介绍个定理:“图不通就独立定理”(当然是为了好理解)
这个定理是说,若概率图满足依赖隔离
则有X与Y条件独立
)
来证明一下,现在用的是贝叶斯网络链式法则,如图2

图2
利用的还是之前那个把求和拆分的Trick,这里要注意一开始求和的脚标是G、I、L
现在分给了3部分L和G部分求和后当然就等于了1,但是I部分则不然,被求和的部分是S,而求和脚标是I,这样就没法继续合并了。不过我们回想之前的独立等价条件最后一条是说:
%20%5Cpropto%20%7B%5Cphi%20_1%7D%5Cleft(%20%7BX,Z%7D%20%5Cright)%5Cphi%20%5Cleft(%20%7BY,Z%7D%20%5Cright))
这样就搞定了,发现D与S还是独立的。这样就证明了“图不通就独立定理”。
那么不禁要问,图什么情况下不通呢?
先说结论:在已知父节点时,该节点与后代节点以外的节点不通。
姑且叫做“不通原则”
说的好啰嗦,直接看图,如图3

图3
我们以Letter节点作为例子,他的父节点时Grade,他的子孙是Job和Happy,所以他和剩下来的SAT、Intelligence、Difficulty、Coherence不通了。粗略分析下,这个环上面走不通是因为Grade已知了;下面走不通是因为Job不知道。分析原理上一讲已经详述了。
定义一个Imap
既然图不通就独立,如果这个不通的图G对应的概率分布是P,我们就称G是P的I-map(independencymap)。
如果独立的概率分布P可以按照某个图G分解,那么G就是P的Imap。
反过来,如果G是概率分布P的Imap,那么P可以按照G来进行分解。
因此概率图的就有了2种等价的观点
1.概率图G是用来表示概率分布P的。
2.P是用来表达概率图G所展示的独立关系的。
证明一下概率图和概率分布为啥是一回事
先写出图1中的条件,如图4所示,用条件概率的链式法则写出P,由G中连接关系可以化简成为贝叶斯网络的链式法则。

图4
尤其注意为什么有
%20=%20P%5Cleft(%20%7BL%5Cleft%7C%20G%20%5Cright.%7D%20%5Cright))
这里要用到之前说明的“不通原则”,L在已知D、G、I、S的前提下,他的非后代节点(他也没有后代节点)是D、I、S,所以直接去掉。
这就说明了概率独立关系与概率图的连接关系其实是一回事。
下面介绍朴素贝叶斯模型
这个朴素贝叶斯叫做(Naïve Bayes)又叫(IdiotBayes…)
基本的朴素贝叶斯模型如图5。

图5
所有的X都是条件独立的,即
,%5Cforall%20X)
由贝叶斯网络的链式法则容易得到
%20=%20P%5Cleft(%20C%20%5Cright)%5Cprod%5Climits_%7Bi%20=%201%7D%5En%20%7BP%5Cleft(%20%7B%7BX_i%7D%5Cleft%7C%20C%5Cright.%7D%20%5Cright)%7D)
有2类常用的朴素贝叶斯模型
举个例子说明两种贝叶斯模型分别是怎么起作用的。现在有一篇文档,由很多单词组成。现在有2个类别可供选择分别是“有关财务”和“有关宠物”。现在要把这篇文章归档。
其一:伯努利朴素贝叶斯(Bernoulli Naive Bayes)
伯努利朴素贝叶斯如图6。
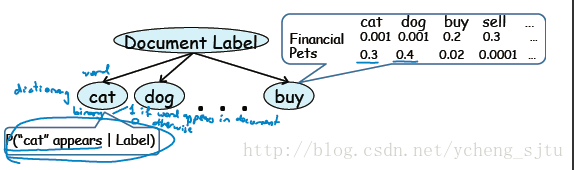
图6
这种方式实质上是“查字典”,它把cat、dog、buy这些当做字典里的词目。
之所以伯努利是因为,这种方式只管分析文章里面有没有出现词典里的词目,而不管出现了多少次。词典的条目都是只有0-1的二项分布随机变量。
文档属于这两类的概率分别为
%7D%7D%7B%7BP%5Cleft(%20%7BC%20=%20%7Bc%5E2%7D%5Cleft%7C%20%7B%7Bx_1%7D,%20%5Cldots%20,%7Bx_n%7D%7D%20%5Cright.%7D%20%5Cright)%7D%7D%20=%20%5Cfrac%7B%7BP%5Cleft(%20%7BC%20=%20%7Bc%5E1%7D%7D%20%5Cright)%7D%7D%7B%7BP%5Cleft(%20%7BC%20=%20%7Bc%5E2%7D%7D%20%5Cright)%7D%7D%5Cprod%5Climits_%7Bi%20=%201%7D%5En%20%7B%5Cfrac%7B%7BP%5Cleft(%20%7B%7Bx_i%7D%5Cleft%7C%20%7BC%20=%20%7Bc%5E1%7D%7D%20%5Cright.%7D%20%5Cright)%7D%7D%7B%7BP%5Cleft(%20%7B%7Bx_i%7D%5Cleft%7C%20%7BC%20=%20%7Bc%5E2%7D%7D%20%5Cright.%7D%20%5Cright)%7D%7D%7D)
每一个小乘积项代表了“如果这是一篇财务文档,能出现cat字眼的概率是0.001”这样的意义。
为啥这个朴素了,因为它假设了每个词的条目出现是相互不影响的。
其二:多项式朴素贝叶斯(Multinomial Naïve Bayes)
这种方式与伯努利有本质不同,如图7

图7
W这些单元再也不是词典的条目了,而是待分类文章中的真实单词。
假如这篇文章写了1991个词,那么就有1991个W
文档属于这两类的概率依然分别为
%7D%7D%7B%7BP%5Cleft(%20%7BC%20=%20%7Bc%5E2%7D%5Cleft%7C%20%7B%7Bx_1%7D,%5Cldots%20,%7Bx_n%7D%7D%20%5Cright.%7D%20%5Cright)%7D%7D%20=%20%5Cfrac%7B%7BP%5Cleft(%20%7BC%20=%20%7Bc%5E1%7D%7D%5Cright)%7D%7D%7B%7BP%5Cleft(%20%7BC%20=%20%7Bc%5E2%7D%7D%20%5Cright)%7D%7D%5Cprod%5Climits_%7Bi%20=%201%7D%5En%20%7B%5Cfrac%7B%7BP%5Cleft(%7B%7Bx_i%7D%5Cleft%7C%20%7BC%20=%20%7Bc%5E1%7D%7D%20%5Cright.%7D%20%5Cright)%7D%7D%7B%7BP%5Cleft(%20%7B%7Bx_i%7D%5Cleft%7C%20%7BC%20=%20%7Bc%5E2%7D%7D%5Cright.%7D%20%5Cright)%7D%7D%7D)
每一个小乘积项代表了“如果这是一篇财务文档,在文章里任意一个位置出现cat的概率是0.001”这样的意思。你看表还是那张表,但是现在完全不一样了!因为现在要求cat+dog+buy+sell这些概率加起来要等于1。而伯努利没这个限制,随意等于多少。这个区别很重要。
为什么这个贝叶斯也是朴素的呢?因为它假定了在文章所有位置出现cat的概率是满足同样的分布的,实际明显不可能好不好。就像“敬爱的”必然一般都会出现在开头,谁会在文章写到一半来句这个。。。
总之朴素贝叶斯确实朴素,它只能用于随机变量相关性较弱的情况,但很多情况实际确实挺弱的。。。所以朴素贝叶斯的效果Surprisingly effective
朴素贝叶斯被广泛使用于各种领域。这里就不展开了。优点还蛮多的。
欢迎参与讨论并关注本博客和微博以及知乎个人主页后续内容继续更新哦~
转载请您尊重作者的劳动,完整保留上述文字以及文章链接,谢谢您的支持!
条件概率链式法则
贝叶斯网络链式法则,如图1
图1
乍一看很容易觉得贝叶斯网络链式法则不就是大家以前学的链式法则么,其实不然,后面详述。
上一讲谈到了概率分布的因式分解
可以看到条件概率的独立性可以直接从概率分布表达式看出来。
我们已经用概率图模型把概率关系用图形化G表示了,独立性能从图上直接看出来吗?
当然,上一讲已经详细解释过了概率图中概率的流动关系.
当G已知时,S和D之间的概率才能相互影响。下面定义一个依赖隔离的概念。
依赖隔离(D-separation)
在Z已知的情况下,X与Y之间没有通路。则称之为X与Y依赖隔离。记作
介绍个定理:“图不通就独立定理”(当然是为了好理解)
这个定理是说,若概率图满足依赖隔离
则有X与Y条件独立
来证明一下,现在用的是贝叶斯网络链式法则,如图2
图2
利用的还是之前那个把求和拆分的Trick,这里要注意一开始求和的脚标是G、I、L
现在分给了3部分L和G部分求和后当然就等于了1,但是I部分则不然,被求和的部分是S,而求和脚标是I,这样就没法继续合并了。不过我们回想之前的独立等价条件最后一条是说:
这样就搞定了,发现D与S还是独立的。这样就证明了“图不通就独立定理”。
那么不禁要问,图什么情况下不通呢?
先说结论:在已知父节点时,该节点与后代节点以外的节点不通。
姑且叫做“不通原则”
说的好啰嗦,直接看图,如图3
图3
我们以Letter节点作为例子,他的父节点时Grade,他的子孙是Job和Happy,所以他和剩下来的SAT、Intelligence、Difficulty、Coherence不通了。粗略分析下,这个环上面走不通是因为Grade已知了;下面走不通是因为Job不知道。分析原理上一讲已经详述了。
定义一个Imap
既然图不通就独立,如果这个不通的图G对应的概率分布是P,我们就称G是P的I-map(independencymap)。
如果独立的概率分布P可以按照某个图G分解,那么G就是P的Imap。
反过来,如果G是概率分布P的Imap,那么P可以按照G来进行分解。
因此概率图的就有了2种等价的观点
1.概率图G是用来表示概率分布P的。
2.P是用来表达概率图G所展示的独立关系的。
证明一下概率图和概率分布为啥是一回事
先写出图1中的条件,如图4所示,用条件概率的链式法则写出P,由G中连接关系可以化简成为贝叶斯网络的链式法则。
图4
尤其注意为什么有
这里要用到之前说明的“不通原则”,L在已知D、G、I、S的前提下,他的非后代节点(他也没有后代节点)是D、I、S,所以直接去掉。
这就说明了概率独立关系与概率图的连接关系其实是一回事。
下面介绍朴素贝叶斯模型
这个朴素贝叶斯叫做(Naïve Bayes)又叫(IdiotBayes…)
基本的朴素贝叶斯模型如图5。
图5
所有的X都是条件独立的,即
由贝叶斯网络的链式法则容易得到
有2类常用的朴素贝叶斯模型
举个例子说明两种贝叶斯模型分别是怎么起作用的。现在有一篇文档,由很多单词组成。现在有2个类别可供选择分别是“有关财务”和“有关宠物”。现在要把这篇文章归档。
其一:伯努利朴素贝叶斯(Bernoulli Naive Bayes)
伯努利朴素贝叶斯如图6。
图6
这种方式实质上是“查字典”,它把cat、dog、buy这些当做字典里的词目。
之所以伯努利是因为,这种方式只管分析文章里面有没有出现词典里的词目,而不管出现了多少次。词典的条目都是只有0-1的二项分布随机变量。
文档属于这两类的概率分别为
每一个小乘积项代表了“如果这是一篇财务文档,能出现cat字眼的概率是0.001”这样的意义。
为啥这个朴素了,因为它假设了每个词的条目出现是相互不影响的。
其二:多项式朴素贝叶斯(Multinomial Naïve Bayes)
这种方式与伯努利有本质不同,如图7
图7
W这些单元再也不是词典的条目了,而是待分类文章中的真实单词。
假如这篇文章写了1991个词,那么就有1991个W
文档属于这两类的概率依然分别为
每一个小乘积项代表了“如果这是一篇财务文档,在文章里任意一个位置出现cat的概率是0.001”这样的意思。你看表还是那张表,但是现在完全不一样了!因为现在要求cat+dog+buy+sell这些概率加起来要等于1。而伯努利没这个限制,随意等于多少。这个区别很重要。
为什么这个贝叶斯也是朴素的呢?因为它假定了在文章所有位置出现cat的概率是满足同样的分布的,实际明显不可能好不好。就像“敬爱的”必然一般都会出现在开头,谁会在文章写到一半来句这个。。。
总之朴素贝叶斯确实朴素,它只能用于随机变量相关性较弱的情况,但很多情况实际确实挺弱的。。。所以朴素贝叶斯的效果Surprisingly effective
朴素贝叶斯被广泛使用于各种领域。这里就不展开了。优点还蛮多的。
欢迎参与讨论并关注本博客和微博以及知乎个人主页后续内容继续更新哦~
转载请您尊重作者的劳动,完整保留上述文字以及文章链接,谢谢您的支持!

相关文章推荐
- 概率图模型(PGM)学习笔记(四)-贝叶斯网络-伯努利贝叶斯-多项式贝叶斯
- 概率图模型(PGM)学习笔记(四)-贝叶斯网络-伯努利贝叶斯-多项式贝叶斯
- 概率图形模型(PGM)学习笔记(四)-贝叶斯网络-伯努利贝叶斯-贝叶斯多项式
- 概率图模型(PGM)学习笔记(二)贝叶斯网络-语义学与因子分解
- 概率图模型(PGM)学习笔记(二)贝叶斯网络-语义学与因子分解
- 概率图模型(PGM)学习笔记(二)贝叶斯网络-语义学与因子分解
- 概率图模型(PGM)学习笔记(二)贝叶斯网络-语义学与因子分解
- 概率图模型(PGM)学习笔记(一)动机与概述
- 概率图模型(PGM)学习笔记(三)模式推断与概率图流
- 概率图模型(PGM)学习笔记(三)模式判断与概率图流
- 概率图模型(PGM)学习笔记(五)——模板模型
- 概率图模型-原理与技术 第三章 贝叶斯网表示 学习笔记(二)
- 概率图模型-原理与技术 第三章 贝叶斯网表示 学习笔记(一)
- 概率图模型(PGM)学习笔记(一)动机与概述
- 概率图模型(PGM)学习笔记(三)模式推断与概率图流
- 概率图模型(PGM)学习笔记(五)——模板模型
- 概率图模型(PGM)学习笔记(三)模式判断与概率图流
- 【学习笔记】matlab算法实现贝叶斯判别classify函数
- 【机器学习-斯坦福】学习笔记6 - 朴素贝叶斯
- PGM学习之五 贝叶斯网络