redis源码解读之哈希接口————dict.h文件
2014-05-04 13:03
597 查看
这篇文章主要是介绍redis的哈希的函数的相关。
哈希算法是以空间换时间的一个做法,效率基本是等于O(1).所以,不管什么项目,哈希在项目中的作用是绝对的重要,我在上一个tx的游戏项目里就大量的使用了哈希算法。
1、redis的大致的数据结构以及关系。(转)
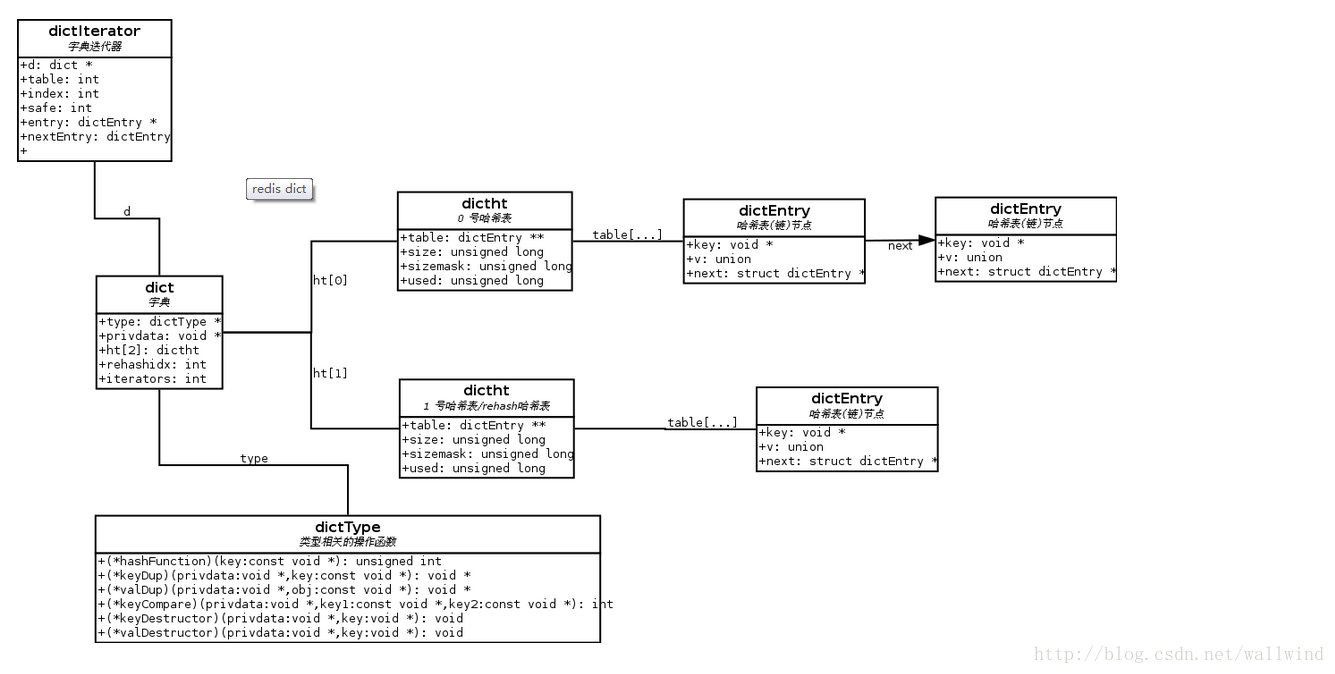
2、数据结构实现
2.1、hash算法回调函数
该数据结构,用来指定hash算法的一些回调函数,比如key 比较,复制等。
2.2 hash字典
该结构体,主要是hash的头部分吧。
hash表的结构体如下
table 属性组成了一个数组,数组里带有节点指针,用作链表。
size 、 sizemask 和 used 这三个属性初看上去让人有点头晕,实际上,它们分别代表的是:
size :桶的数量,也即是, table 数组的大小。
sizemask :这个值通过 size – 1 计算出来,给定 key 的哈希值计算出来之后,就会和这个数值进行 & 操作,决定元素被放到 table 数组的那一个位置上。
used :这个值代表目前哈希表中元素的数量,也即是哈希表总共保存了多少 dictEntry 结构。
hash表的迭代器
下面是围绕这些数据结构如何来使用的呢?
2.使用
2.1创建并初始化
如果我们想创建一个hash表,直接调用该接口使用,
使用案例:
调用流程为:
这样,我就创建好了一个hash表
2.2 添加扩容方案
使用hash,真正分配内存是在,
这里使用了比较特别的方案就是rehash方案。
我理解的思路就是动态扩展内存的方案,如果需要扩展,就调用,
方法,如果内存不够,也同样调用该方法,
当 Hash Table 使用率低于 10%,同样会执行 resize 操作以节省内存。
2.3hash函数
/* Thomas Wang's 32 bit Mix Function */
unsigned int dictIntHashFunction(unsigned int key)
{
key += ~(key << 15);
key ^= (key >> 10);
key += (key << 3);
key ^= (key >> 6);
key += ~(key << 11);
key ^= (key >> 16);
return key;
}
/* Identity hash function for integer keys */
unsigned int dictIdentityHashFunction(unsigned int key)
{
return key;
}
static uint32_t dict_hash_function_seed = 5381;
void dictSetHashFunctionSeed(uint32_t seed) {
dict_hash_function_seed = seed;
}
uint32_t dictGetHashFunctionSeed(void) {
return dict_hash_function_seed;
}
/* MurmurHash2, by Austin Appleby
* Note - This code makes a few assumptions about how your machine behaves -
* 1. We can read a 4-byte value from any address without crashing
* 2. sizeof(int) == 4
*
* And it has a few limitations -
*
* 1. It will not work incrementally.
* 2. It will not produce the same results on little-endian and big-endian
* machines.
*/
unsigned int dictGenHashFunction(const void *key, int len) {
/* 'm' and 'r' are mixing constants generated offline.
They're not really 'magic', they just happen to work well. */
uint32_t seed = dict_hash_function_seed;
const uint32_t m = 0x5bd1e995;
const int r = 24;
/* Initialize the hash to a 'random' value */
uint32_t h = seed ^ len;
/* Mix 4 bytes at a time into the hash */
const unsigned char *data = (const unsigned char *)key;
while(len >= 4) {
uint32_t k = *(uint32_t*)data;
k *= m;
k ^= k >> r;
k *= m;
h *= m;
h ^= k;
data += 4;
len -= 4;
}
/* Handle the last few bytes of the input array */
switch(len) {
case 3: h ^= data[2] << 16;
case 2: h ^= data[1] << 8;
case 1: h ^= data[0]; h *= m;
};
/* Do a few final mixes of the hash to ensure the last few
* bytes are well-incorporated. */
h ^= h >> 13;
h *= m;
h ^= h >> 15;
return (unsigned int)h;
}
/* And a case insensitive hash function (based on djb hash) */
unsigned int dictGenCaseHashFunction(const unsigned char *buf, int len) {
unsigned int hash = (unsigned int)dict_hash_function_seed;
while (len--)
hash = ((hash << 5) + hash) + (tolower(*buf++)); /* hash * 33 + c */
return hash;
}
不同数据类型,使用的hash函数不同。我之前比较常用的就是对cha* 进行hash。
哈希算法是以空间换时间的一个做法,效率基本是等于O(1).所以,不管什么项目,哈希在项目中的作用是绝对的重要,我在上一个tx的游戏项目里就大量的使用了哈希算法。
1、redis的大致的数据结构以及关系。(转)
2、数据结构实现
2.1、hash算法回调函数
typedef struct dictType {
unsigned int (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;该数据结构,用来指定hash算法的一些回调函数,比如key 比较,复制等。
2.2 hash字典
该结构体,主要是hash的头部分吧。
typedef struct dict {
dictType *type;//上边的type,为不同数据类型hash使用的回调函数,
void *privdata;
dictht ht[2]; //使用的两个hash表,主要是用来旧的到新的转换
int rehashidx; /* rehashing not in progress if rehashidx == -1 */是否在使用
int iterators; /* number of iterators currently running */数量
} dict;hash表的结构体如下
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;table 属性组成了一个数组,数组里带有节点指针,用作链表。
size 、 sizemask 和 used 这三个属性初看上去让人有点头晕,实际上,它们分别代表的是:
size :桶的数量,也即是, table 数组的大小。
sizemask :这个值通过 size – 1 计算出来,给定 key 的哈希值计算出来之后,就会和这个数值进行 & 操作,决定元素被放到 table 数组的那一个位置上。
used :这个值代表目前哈希表中元素的数量,也即是哈希表总共保存了多少 dictEntry 结构。
hash表的迭代器
/* If safe is set to 1 this is a safe iterator, that means, you can call
* dictAdd, dictFind, and other functions against the dictionary even while
* iterating. Otherwise it is a non safe iterator, and only dictNext()
* should be called while iterating. */
typedef struct dictIterator {
dict *d;
int table, index, safe;
dictEntry *entry, *nextEntry;
long long fingerprint; /* unsafe iterator fingerprint for misuse detection */
} dictIterator;下面是围绕这些数据结构如何来使用的呢?
2.使用
2.1创建并初始化
/* Create a new hash table */
dict *dictCreate(dictType *type,
void *privDataPtr)
{
dict *d = zmalloc(sizeof(*d));
_dictInit(d,type,privDataPtr);
return d;
}如果我们想创建一个hash表,直接调用该接口使用,
使用案例:
server.commands = dictCreate(&commandTableDictType,NULL); server.orig_commands = dictCreate(&commandTableDictType,NULL);
调用流程为:
dict *dictCreate(dictType *type,void *privDataPtr) int _dictInit(dict *d, dictType *type,void *privDataPtr) static void _dictReset(dict *ht)
这样,我就创建好了一个hash表
2.2 添加扩容方案
使用hash,真正分配内存是在,
/* Low level add. This function adds the entry but instead of setting
* a value returns the dictEntry structure to the user, that will make
* sure to fill the value field as he wishes.
*
* This function is also directly exposed to user API to be called
* mainly in order to store non-pointers inside the hash value, example:
*
* entry = dictAddRaw(dict,mykey);
* if (entry != NULL) dictSetSignedIntegerVal(entry,1000);
*
* Return values:
*
* If key already exists NULL is returned.
* If key was added, the hash entry is returned to be manipulated by the caller.
*/
dictEntry *dictAddRaw(dict *d, void *key)
{
int index;
dictEntry *entry;
dictht *ht;
if (dictIsRehashing(d)) _dictRehashStep(d);
/* Get the index of the new element, or -1 if
* the element already exists. */
if ((index = _dictKeyIndex(d, key)) == -1)
return NULL;
/* Allocate the memory and store the new entry */
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
entry = zmalloc(sizeof(*entry));
entry->next = ht->table[index];
ht->table[index] = entry;
ht->used++;
/* Set the hash entry fields. */
dictSetKey(d, entry, key);
return entry;
}这里使用了比较特别的方案就是rehash方案。
我理解的思路就是动态扩展内存的方案,如果需要扩展,就调用,
/* Expand or create the hashtable */
static int dictExpand(dict *ht, unsigned long size) {
dict n; /* the new hashtable */
unsigned long realsize = _dictNextPower(size), i;
/* the size is invalid if it is smaller than the number of
* elements already inside the hashtable */
if (ht->used > size)
return DICT_ERR;
_dictInit(&n, ht->type, ht->privdata);
n.size = realsize;
n.sizemask = realsize-1;
n.table = calloc(realsize,sizeof(dictEntry*));
/* Copy all the elements from the old to the new table:
* note that if the old hash table is empty ht->size is zero,
* so dictExpand just creates an hash table. */
n.used = ht->used;
for (i = 0; i < ht->size && ht->used > 0; i++) {
dictEntry *he, *nextHe;
if (ht->table[i] == NULL) continue;
/* For each hash entry on this slot... */
he = ht->table[i];
while(he) {
unsigned int h;
nextHe = he->next;
/* Get the new element index */
h = dictHashKey(ht, he->key) & n.sizemask;
he->next = n.table[h];
n.table[h] = he;
ht->used--;
/* Pass to the next element */
he = nextHe;
}
}
assert(ht->used == 0);
free(ht->table);
/* Remap the new hashtable in the old */
*ht = n;
return DICT_OK;
}方法,如果内存不够,也同样调用该方法,
当 Hash Table 使用率低于 10%,同样会执行 resize 操作以节省内存。
2.3hash函数
/* Thomas Wang's 32 bit Mix Function */
unsigned int dictIntHashFunction(unsigned int key)
{
key += ~(key << 15);
key ^= (key >> 10);
key += (key << 3);
key ^= (key >> 6);
key += ~(key << 11);
key ^= (key >> 16);
return key;
}
/* Identity hash function for integer keys */
unsigned int dictIdentityHashFunction(unsigned int key)
{
return key;
}
static uint32_t dict_hash_function_seed = 5381;
void dictSetHashFunctionSeed(uint32_t seed) {
dict_hash_function_seed = seed;
}
uint32_t dictGetHashFunctionSeed(void) {
return dict_hash_function_seed;
}
/* MurmurHash2, by Austin Appleby
* Note - This code makes a few assumptions about how your machine behaves -
* 1. We can read a 4-byte value from any address without crashing
* 2. sizeof(int) == 4
*
* And it has a few limitations -
*
* 1. It will not work incrementally.
* 2. It will not produce the same results on little-endian and big-endian
* machines.
*/
unsigned int dictGenHashFunction(const void *key, int len) {
/* 'm' and 'r' are mixing constants generated offline.
They're not really 'magic', they just happen to work well. */
uint32_t seed = dict_hash_function_seed;
const uint32_t m = 0x5bd1e995;
const int r = 24;
/* Initialize the hash to a 'random' value */
uint32_t h = seed ^ len;
/* Mix 4 bytes at a time into the hash */
const unsigned char *data = (const unsigned char *)key;
while(len >= 4) {
uint32_t k = *(uint32_t*)data;
k *= m;
k ^= k >> r;
k *= m;
h *= m;
h ^= k;
data += 4;
len -= 4;
}
/* Handle the last few bytes of the input array */
switch(len) {
case 3: h ^= data[2] << 16;
case 2: h ^= data[1] << 8;
case 1: h ^= data[0]; h *= m;
};
/* Do a few final mixes of the hash to ensure the last few
* bytes are well-incorporated. */
h ^= h >> 13;
h *= m;
h ^= h >> 15;
return (unsigned int)h;
}
/* And a case insensitive hash function (based on djb hash) */
unsigned int dictGenCaseHashFunction(const unsigned char *buf, int len) {
unsigned int hash = (unsigned int)dict_hash_function_seed;
while (len--)
hash = ((hash << 5) + hash) + (tolower(*buf++)); /* hash * 33 + c */
return hash;
}
不同数据类型,使用的hash函数不同。我之前比较常用的就是对cha* 进行hash。

相关文章推荐
- redis源码解读之内存管理————zmalloc文件
- redis源码解读总结(redis一致性哈希实现)
- redis源码解读之双向链表————adlist.h文件
- 解读Redis dict核心数据结构
- jdk1.8.0_45源码解读——Set接口和AbstractSet抽象类的实现
- FastDFS的配置、部署与API使用解读(8)FastDFS多种文件上传接口详解
- crawler4j 源码解读之配置文件configurable
- Redis配置文件redis.conf参数解读
- Redis源码阅读笔记(3)-- 字典dict
- Redis配置文件解读
- Redis源码解读
- CI框架源码解读之利用Hook.php文件完成功能扩展的方法
- Redis的字典(dict)rehash过程源码解析
- Spring源码解析 - BeanFactory接口体系解读
- mysql源码解读之配置文件
- 【机器人学】机器人开源项目KDL源码学习:(7)examples中的CMakeList.txt文件解读
- spring-data-redis源码解读二
- redis aof 持久化 解读源码精品博文
- spring 源码解读与设计详解:8 Spring配置文件的读取与容器装配详析
- redis 源码 dict.c 实现