Sql性能优化之sql语句的写法
2014-04-28 22:33
776 查看
Sql性能优化之sql语句的写法
一、引言
系统优化中一个很重要的方面就是SQL语句的优化。对于海量数据,劣质SQL语句和优质SQL语句之间的速度差别可以达到上百倍,可见对于一个系统不是简单地能实现其功能就可,而是要写出高质量的SQL语句,提高系统的可用性。
所用的例子来自于RIS数据库。
二、优化点
1. 书写规范——采用统一的SQL语句的写法
对于以下四句SQL语句,程序员认为是相同的,数据库查询优化器认为是不同的。
例:
select *
from patientinfo;
select *
from dbo.patientinfo;
-- 带表所有者的前缀
SELECT *
FROM patientinfo;
-- 大写
select *
from patientinfo;
-- 中间多了空格
写法不同,查询分析器就认为是不同的SQL语句,必须进行四次解析,生成4个执行计划。所以作为程序员,应该保证相同的查询语句在任何地方都一致,多一个空格都不行。
同样,作为测试人员,我们也需要了解同一功能不同写法的SQL语句会对查询性能产生影响。故,应该要养成书写一致的习惯。
2. Select嵌套查询尽量不超过3层
SQL语句尽量简单,不要太复杂。我们一般,会将一个Select语句的结果作为子集,然后从该子集中再进行查询。但是超过3层嵌套,查询优化器就很容易给出错误的执行计划。
另外,执行计划是可以被重用的,越简单的SQL语句被重用的可能性越高。而复杂的SQL语句只要有一个字符发生变化就必须重新解析,然后再把这一大堆垃圾塞在内存里。可想而知,数据库的效率会何等低下。
3. 少用通配符*,需要几列,选择几列查询
在查询时,不要过多地使用通配符如 SELECT * FROM T1语句,要用到几列就选择几列如:SELECT COL1,COL2 FROM T1。例:
低效:
select *
from registerinfo wherecheckitem='常规CT';
查询显示:

高效:
select registerid,hisidfrom registerinfo
wherecheckitem='常规CT';
查询显示:

4.
减少结果集行数:SELECT TOP number..
在可能的情况下,可以尽量限制尽量结果集行数如:SELECT TOP 300 COL1,COL2,COL3FROM T1,因为某些情况下用户是不需要那么多的数据的。
例:
select top 500 registerid,hisid
fromregisterinfo where checkitem='常规CT';
查询显示:

可以看出比上面快了很多。
5. 避免在索引列上使用计算
WHERE子句中,如果索引列是函数的一部分。优化器将不使用索引而使用全表扫瞄。
例:
低效:
SELECT *
FROM DEPT WHERE SAL
* 12 > 25000;
高效:
SELECT *FROM DEPT
WHERESAL > 25000/12;
6. 用 >= 代替 >
实例如下:
低效:
select registerid,hisid,patientid
from registerinfo where age
>59;
查询显示:

高效:
selectregisterid,hisid,patientidfrom registerinfo
whereage >=60;
查询显示:

两者的区别在于:前者DBMS将直接跳到第一个age等于59的记录,而后者将首先定位到age=60的记录并且向前扫瞄到第一个age大于60的记录。
从查询结果可以看出,用>=的查询效率比用>的查询效率高。
7. 避免使用NULL值判断
应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描。
例:
select id from t
where num is
null;
可以在num上设置默认值,确保表中num列没有null值,然后这样查询:
select id from t
where num=0;
8. 避免使用!=或<>操作符
应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。优化器将无法通过索引来确定将要命中的行数,因此需要搜索该表的所有行。
9. 避免使用OR连接
应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描。
例:
select hisid,patientid
from registerinfo where registerid=1
orregisterid=2;
查询显示:
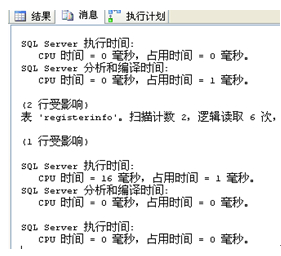
可以这样查询:
select hisid,patientid
from registerinfo where registerid=1
union all
selecthisid,patientid
fromregisterinfo where registerid
=2
查询显示:
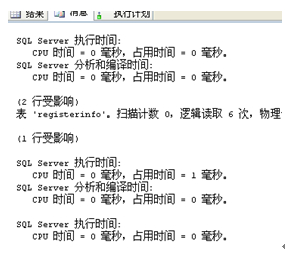
虽然两者的执行时间对比差距很小,但语句二可以看出有一定的优势。
10. 慎用IN和NOT IN
in 和 not in 也要慎用,因为IN会使系统无法使用索引,而只能直接搜索表中的数据。
例:
select id from t
where num in(1,2,3);
对于连续的数值,能用between 就不要用in 了:
select id from t
where num between 1
and 3;
11. 用EXISTS替代IN、用NOT
EXISTS替代NOT IN
在许多基于基础表的查询中,为了满足一个条件,往往需要对另一个表进行联接。在这种情况下,使用EXISTS(或NOT EXISTS)通常将提高查询的效率。在子查询中,NOT IN子句将执行一个内部的排序和合并。无论在哪种情况下,NOT IN都是最低效的 (因为它对子查询中的表执行了一个全表遍历).。为了避免使用NOT IN,我们可以把它改写成外连接(Outer Joins)或NOT
EXISTS。
例:
低效:
SELECT patientname
FROM patientinfo
WHERE hisid IN
(SELECT hisid
FROM registerinfo WHERE checktype
= 'CT');
查询显示:

高效:
SELECT patientname
FROM patientinfo
WHERE EXISTS
(SELECT 'X'
FROM registerinfo WHERE patientinfo.hisid= registerinfo.hisidAND checktype
= 'CT')
查询显示:

12. LIKE操作符
LIKE操作符可以应用通配符查询,里面的通配符组合可能达到几乎是任意的查询,但是如果用得不好则会产生性能上的问题。
如LIKE ‘%5400%’ 这种前导模糊查询不会引用索引,会进行全表扫描,而LIKE ‘X5400%’ 这种后导模糊查询,则会引用范围索引。在查找时,尽量使用后导模糊的like查询,必要时可以用or连接。
13. 用EXISTS替换DISTINCT
当提交一个包含一对多表信息(比如部门表和雇员表)的查询时,避免在SELECT子句中使用DISTINCT。一般可以考虑用EXISTS替换。EXISTS 使查询更为迅速,因为RDBMS核心模块将在子查询的条件一旦满足后,立刻返回结果。
例:
低效:
SELECT DISTINCT patientname
FROM patientinfo P,registerinfo R
WHERE P.hisid
= R.hisid;
查询显示:

高效:
SELECT patientname
FROM patientinfo WHERE
EXISTS(SELECT
'X' FROM registerinfo
WHERE patientinfo.hisid= registerinfo.hisid)
;
查询显示:

DISTINCT的SQL语句会启动SQL引擎执行耗费资源的排序(SORT)功能。DISTINCT需要一次排序操作。
类似的,带有UNION,MINUS,INTERSECT,ORDER BY的SQL语句也会启动SQL引擎执行耗费资源的排序功能,而且它们至少需要执行两次排序。通常,,带有UNION,MINUS
, INTERSECT的SQL语句都可以用其他方式重写.。如果数据库的SORT_AREA_SIZE调配得好,使用UNION
, MINUS, INTERSECT也是可以考虑的,毕竟它们的可读性很强。
14. 优化 GROUP BY
提高GROUPBY 语句的效率, 可以通过将不需要的记录在GROUP BY 之前过滤掉.
例子:统计CT和MR检查的人数
低效:
SELECT checktype,COUNT(hisid)
FROM registerinfo
GROUP BY checktype
HAVING checktype='CT'
OR checktype='MR';
查询显示:

高效:
SELECT checktype,COUNT(hisid)
FROM registerinfo
WHERE checktype='CT'OR checktype='MR'
GROUP BY checktype;
查询显示:

这两个查询返回相同结果,但是第二条语句速度快。
15.用WHERE替代ORDER BY
ORDER BY 子句只在两种严格的条件下使用索引:
(1) ORDER BY中所有的列必须包含在相同的索引中并保持在索引中的排列顺序;
(2) ORDER BY中所有的列必须定义为非空。
WHERE子句使用的索引和ORDER BY子句中所使用的索引不能并列。
例如:
表DEPT包含以下列:
DEPT_CODE PK NOT NULL
DEPT_DESC NOT NULL
DEPT_TYPE NULL
低效: (索引不被使用)
SELECT DEPT_CODE FROM DEPT
ORDER BY DEPT_TYPE;
高效: (使用索引)
SELECT DEPT_CODE
FROM DEPT WHERE DEPT_TYPE
> 0;
16. 用Where子句替换HAVING子句
避免使用HAVING子句, HAVING 只会在检索出所有记录之后才对结果集进行过滤。这个处理需要排序、总计等操作。如果能通过WHERE子句限制记录的数目,那就能减少这方面的开销。
在SQL Server中,on、where、having这三个都可以加条件的子句。on是最先执行,where次之,having最后。因为on是先把不符合条件的记录过滤后才进行统计,它就可以减少中间运算要处理的数据,按理说应该速度是最快的。where也应该比having快点,因为它过滤数据后才进行sum。
在两个表联接时才用on的,故在一个表的时候,就剩下where跟having比较了。在单表查询统计的情况下,如果要过滤的条件没有涉及到要计算字段,那它们的结果是一样的,只是where可以使用rushmore技术,而having就不能,在速度上后者要慢如果要涉及到计算的字段,就表示在没计算之前,这个字段的值是不确定的。where的作用时间是在计算之前就完成的,而having就是在计算后才起作用的,所以在这种情况下,两者的结果会不同。
在多表联接查询时,on比where更早起作用。系统首先根据各个表之间的联接条件,把多个表合成一个临时表 后,再由where进行过滤,然后再计算,计算完后再由having进行过滤。由此可见,要想过滤条件起到正确的作用,首先要明白这个条件应该在什么时候起作用,然后再决定放在那里。
17.使用表的别名(Alias)
当在SQL语句中连接多个表时, 可以使用表的别名并把别名前缀于每个Column上。这样一来,就可以减少解析的时间并减少那些由Column歧义引起的语法错误。
18. 表连接的注意点
(1) 连接字段尽量选择聚集索引所在的字段
(2) 仔细考虑where条件,尽量减小A、B表的结果集。根据需求选择内连接、外连接等方式。
充分利用连接条件,在某种情况下,两个表之间可能不只一个的连接条件,这时在 WHERE 子句中将连接条件完整的写上,有可能大大提高查询速度。
例:
低效:
SELECT SUM(A.AMOUNT)
FROM ACCOUNT A,CARD B
WHERE A.CARD_NO
= B.CARD_NO;
高效:
SELECTSUM(A.AMOUNT)
FROM ACCOUNT A,CARD B
WHERE A.CARD_NO
= B.CARD_NO AND A.ACCOUNT_NO=B.ACCOUNT_NO;
第二句将比第一句执行快得多。
19. 使用视图加速查询
把表的一个子集进行排序并创建视图,有时能加速查询。它有助于避免多重排序操作,而且在其他方面还能简化优化器的工作。
例:查询需要检查CT且年龄在60岁以上的病人名字和病历号
SELECT patientname,registerid
FROM patientinfo P,registerinfo R
WHERE P.hisid
= R.hisid AND R.age>60
AND R.checktype
= 'CT'
ORDER BY R.registerid;
查询显示:

如果这个查询要被执行多次而不止一次,可以把所有需要检查CT的病人找出来放在一个视图中:
CREATE VIEW V_PATIENT_REGISTER
AS
SELECTpatientname,registerid,age
FROMpatientinfo,registerinfo
WHEREpatientinfo.hisid
=registerinfo.hisid
ANDchecktype
= 'CT';
创建好视图后,然后以下面的方式在视图中查询:
SELECT *
FROM V_PATIENT_REGISTER
WHERE age>60;
查询显示:

视图中的行要比主表中的行少,而且物理顺序就是所要求的顺序,减少了磁盘I/O,所以查询工作量可以得到大幅减少。
三、后言
上面我们提到的是一些基本的提高查询速度的注意事项,但是在更多的情况下,往往需要反复试验比较不同的语句以得到最佳方案。最好的方法当然是测试,看实现相同功能的SQL语句哪个执行时间最少,但是数据库中如果数据量很少,是比较不出来的,这时可以用查看执行计划,即:把实现相同功能的多条SQL语句考到查询分析器,按CTRL+L看查所利用的索引,表扫描次数(这两个对性能影响最大),总体上看询成本百分比即可。
四、推荐文章
1. 数据库性能优化之SQL语句优化1
http://blog.csdn.net/dzl84394/article/details/8201166
2. 优化SQL查询:如何写出高性能SQL语句
http://www.2cto.com/database/201201/115929.html
3. 海量数据库的查询优化及分页算法方案
http://www.cnblogs.com/jiangyehu1110/archive/2013/06/12/3132705.html
一、引言
系统优化中一个很重要的方面就是SQL语句的优化。对于海量数据,劣质SQL语句和优质SQL语句之间的速度差别可以达到上百倍,可见对于一个系统不是简单地能实现其功能就可,而是要写出高质量的SQL语句,提高系统的可用性。
所用的例子来自于RIS数据库。
二、优化点
1. 书写规范——采用统一的SQL语句的写法
对于以下四句SQL语句,程序员认为是相同的,数据库查询优化器认为是不同的。
例:
select *
from patientinfo;
select *
from dbo.patientinfo;
-- 带表所有者的前缀
SELECT *
FROM patientinfo;
-- 大写
select *
from patientinfo;
-- 中间多了空格
写法不同,查询分析器就认为是不同的SQL语句,必须进行四次解析,生成4个执行计划。所以作为程序员,应该保证相同的查询语句在任何地方都一致,多一个空格都不行。
同样,作为测试人员,我们也需要了解同一功能不同写法的SQL语句会对查询性能产生影响。故,应该要养成书写一致的习惯。
2. Select嵌套查询尽量不超过3层
SQL语句尽量简单,不要太复杂。我们一般,会将一个Select语句的结果作为子集,然后从该子集中再进行查询。但是超过3层嵌套,查询优化器就很容易给出错误的执行计划。
另外,执行计划是可以被重用的,越简单的SQL语句被重用的可能性越高。而复杂的SQL语句只要有一个字符发生变化就必须重新解析,然后再把这一大堆垃圾塞在内存里。可想而知,数据库的效率会何等低下。
3. 少用通配符*,需要几列,选择几列查询
在查询时,不要过多地使用通配符如 SELECT * FROM T1语句,要用到几列就选择几列如:SELECT COL1,COL2 FROM T1。例:
低效:
select *
from registerinfo wherecheckitem='常规CT';
查询显示:
高效:
select registerid,hisidfrom registerinfo
wherecheckitem='常规CT';
查询显示:
4.
减少结果集行数:SELECT TOP number..
在可能的情况下,可以尽量限制尽量结果集行数如:SELECT TOP 300 COL1,COL2,COL3FROM T1,因为某些情况下用户是不需要那么多的数据的。
例:
select top 500 registerid,hisid
fromregisterinfo where checkitem='常规CT';
查询显示:
可以看出比上面快了很多。
5. 避免在索引列上使用计算
WHERE子句中,如果索引列是函数的一部分。优化器将不使用索引而使用全表扫瞄。
例:
低效:
SELECT *
FROM DEPT WHERE SAL
* 12 > 25000;
高效:
SELECT *FROM DEPT
WHERESAL > 25000/12;
6. 用 >= 代替 >
实例如下:
低效:
select registerid,hisid,patientid
from registerinfo where age
>59;
查询显示:
高效:
selectregisterid,hisid,patientidfrom registerinfo
whereage >=60;
查询显示:
两者的区别在于:前者DBMS将直接跳到第一个age等于59的记录,而后者将首先定位到age=60的记录并且向前扫瞄到第一个age大于60的记录。
从查询结果可以看出,用>=的查询效率比用>的查询效率高。
7. 避免使用NULL值判断
应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描。
例:
select id from t
where num is
null;
可以在num上设置默认值,确保表中num列没有null值,然后这样查询:
select id from t
where num=0;
8. 避免使用!=或<>操作符
应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。优化器将无法通过索引来确定将要命中的行数,因此需要搜索该表的所有行。
9. 避免使用OR连接
应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描。
例:
select hisid,patientid
from registerinfo where registerid=1
orregisterid=2;
查询显示:
可以这样查询:
select hisid,patientid
from registerinfo where registerid=1
union all
selecthisid,patientid
fromregisterinfo where registerid
=2
查询显示:
虽然两者的执行时间对比差距很小,但语句二可以看出有一定的优势。
10. 慎用IN和NOT IN
in 和 not in 也要慎用,因为IN会使系统无法使用索引,而只能直接搜索表中的数据。
例:
select id from t
where num in(1,2,3);
对于连续的数值,能用between 就不要用in 了:
select id from t
where num between 1
and 3;
11. 用EXISTS替代IN、用NOT
EXISTS替代NOT IN
在许多基于基础表的查询中,为了满足一个条件,往往需要对另一个表进行联接。在这种情况下,使用EXISTS(或NOT EXISTS)通常将提高查询的效率。在子查询中,NOT IN子句将执行一个内部的排序和合并。无论在哪种情况下,NOT IN都是最低效的 (因为它对子查询中的表执行了一个全表遍历).。为了避免使用NOT IN,我们可以把它改写成外连接(Outer Joins)或NOT
EXISTS。
例:
低效:
SELECT patientname
FROM patientinfo
WHERE hisid IN
(SELECT hisid
FROM registerinfo WHERE checktype
= 'CT');
查询显示:
高效:
SELECT patientname
FROM patientinfo
WHERE EXISTS
(SELECT 'X'
FROM registerinfo WHERE patientinfo.hisid= registerinfo.hisidAND checktype
= 'CT')
查询显示:
12. LIKE操作符
LIKE操作符可以应用通配符查询,里面的通配符组合可能达到几乎是任意的查询,但是如果用得不好则会产生性能上的问题。
如LIKE ‘%5400%’ 这种前导模糊查询不会引用索引,会进行全表扫描,而LIKE ‘X5400%’ 这种后导模糊查询,则会引用范围索引。在查找时,尽量使用后导模糊的like查询,必要时可以用or连接。
13. 用EXISTS替换DISTINCT
当提交一个包含一对多表信息(比如部门表和雇员表)的查询时,避免在SELECT子句中使用DISTINCT。一般可以考虑用EXISTS替换。EXISTS 使查询更为迅速,因为RDBMS核心模块将在子查询的条件一旦满足后,立刻返回结果。
例:
低效:
SELECT DISTINCT patientname
FROM patientinfo P,registerinfo R
WHERE P.hisid
= R.hisid;
查询显示:
高效:
SELECT patientname
FROM patientinfo WHERE
EXISTS(SELECT
'X' FROM registerinfo
WHERE patientinfo.hisid= registerinfo.hisid)
;
查询显示:
DISTINCT的SQL语句会启动SQL引擎执行耗费资源的排序(SORT)功能。DISTINCT需要一次排序操作。
类似的,带有UNION,MINUS,INTERSECT,ORDER BY的SQL语句也会启动SQL引擎执行耗费资源的排序功能,而且它们至少需要执行两次排序。通常,,带有UNION,MINUS
, INTERSECT的SQL语句都可以用其他方式重写.。如果数据库的SORT_AREA_SIZE调配得好,使用UNION
, MINUS, INTERSECT也是可以考虑的,毕竟它们的可读性很强。
14. 优化 GROUP BY
提高GROUPBY 语句的效率, 可以通过将不需要的记录在GROUP BY 之前过滤掉.
例子:统计CT和MR检查的人数
低效:
SELECT checktype,COUNT(hisid)
FROM registerinfo
GROUP BY checktype
HAVING checktype='CT'
OR checktype='MR';
查询显示:
高效:
SELECT checktype,COUNT(hisid)
FROM registerinfo
WHERE checktype='CT'OR checktype='MR'
GROUP BY checktype;
查询显示:
这两个查询返回相同结果,但是第二条语句速度快。
15.用WHERE替代ORDER BY
ORDER BY 子句只在两种严格的条件下使用索引:
(1) ORDER BY中所有的列必须包含在相同的索引中并保持在索引中的排列顺序;
(2) ORDER BY中所有的列必须定义为非空。
WHERE子句使用的索引和ORDER BY子句中所使用的索引不能并列。
例如:
表DEPT包含以下列:
DEPT_CODE PK NOT NULL
DEPT_DESC NOT NULL
DEPT_TYPE NULL
低效: (索引不被使用)
SELECT DEPT_CODE FROM DEPT
ORDER BY DEPT_TYPE;
高效: (使用索引)
SELECT DEPT_CODE
FROM DEPT WHERE DEPT_TYPE
> 0;
16. 用Where子句替换HAVING子句
避免使用HAVING子句, HAVING 只会在检索出所有记录之后才对结果集进行过滤。这个处理需要排序、总计等操作。如果能通过WHERE子句限制记录的数目,那就能减少这方面的开销。
在SQL Server中,on、where、having这三个都可以加条件的子句。on是最先执行,where次之,having最后。因为on是先把不符合条件的记录过滤后才进行统计,它就可以减少中间运算要处理的数据,按理说应该速度是最快的。where也应该比having快点,因为它过滤数据后才进行sum。
在两个表联接时才用on的,故在一个表的时候,就剩下where跟having比较了。在单表查询统计的情况下,如果要过滤的条件没有涉及到要计算字段,那它们的结果是一样的,只是where可以使用rushmore技术,而having就不能,在速度上后者要慢如果要涉及到计算的字段,就表示在没计算之前,这个字段的值是不确定的。where的作用时间是在计算之前就完成的,而having就是在计算后才起作用的,所以在这种情况下,两者的结果会不同。
在多表联接查询时,on比where更早起作用。系统首先根据各个表之间的联接条件,把多个表合成一个临时表 后,再由where进行过滤,然后再计算,计算完后再由having进行过滤。由此可见,要想过滤条件起到正确的作用,首先要明白这个条件应该在什么时候起作用,然后再决定放在那里。
17.使用表的别名(Alias)
当在SQL语句中连接多个表时, 可以使用表的别名并把别名前缀于每个Column上。这样一来,就可以减少解析的时间并减少那些由Column歧义引起的语法错误。
18. 表连接的注意点
(1) 连接字段尽量选择聚集索引所在的字段
(2) 仔细考虑where条件,尽量减小A、B表的结果集。根据需求选择内连接、外连接等方式。
充分利用连接条件,在某种情况下,两个表之间可能不只一个的连接条件,这时在 WHERE 子句中将连接条件完整的写上,有可能大大提高查询速度。
例:
低效:
SELECT SUM(A.AMOUNT)
FROM ACCOUNT A,CARD B
WHERE A.CARD_NO
= B.CARD_NO;
高效:
SELECTSUM(A.AMOUNT)
FROM ACCOUNT A,CARD B
WHERE A.CARD_NO
= B.CARD_NO AND A.ACCOUNT_NO=B.ACCOUNT_NO;
第二句将比第一句执行快得多。
19. 使用视图加速查询
把表的一个子集进行排序并创建视图,有时能加速查询。它有助于避免多重排序操作,而且在其他方面还能简化优化器的工作。
例:查询需要检查CT且年龄在60岁以上的病人名字和病历号
SELECT patientname,registerid
FROM patientinfo P,registerinfo R
WHERE P.hisid
= R.hisid AND R.age>60
AND R.checktype
= 'CT'
ORDER BY R.registerid;
查询显示:
如果这个查询要被执行多次而不止一次,可以把所有需要检查CT的病人找出来放在一个视图中:
CREATE VIEW V_PATIENT_REGISTER
AS
SELECTpatientname,registerid,age
FROMpatientinfo,registerinfo
WHEREpatientinfo.hisid
=registerinfo.hisid
ANDchecktype
= 'CT';
创建好视图后,然后以下面的方式在视图中查询:
SELECT *
FROM V_PATIENT_REGISTER
WHERE age>60;
查询显示:
视图中的行要比主表中的行少,而且物理顺序就是所要求的顺序,减少了磁盘I/O,所以查询工作量可以得到大幅减少。
三、后言
上面我们提到的是一些基本的提高查询速度的注意事项,但是在更多的情况下,往往需要反复试验比较不同的语句以得到最佳方案。最好的方法当然是测试,看实现相同功能的SQL语句哪个执行时间最少,但是数据库中如果数据量很少,是比较不出来的,这时可以用查看执行计划,即:把实现相同功能的多条SQL语句考到查询分析器,按CTRL+L看查所利用的索引,表扫描次数(这两个对性能影响最大),总体上看询成本百分比即可。
四、推荐文章
1. 数据库性能优化之SQL语句优化1
http://blog.csdn.net/dzl84394/article/details/8201166
2. 优化SQL查询:如何写出高性能SQL语句
http://www.2cto.com/database/201201/115929.html
3. 海量数据库的查询优化及分页算法方案
http://www.cnblogs.com/jiangyehu1110/archive/2013/06/12/3132705.html

相关文章推荐
- Oracle性能优化学习笔记之共享Sql语句
- 常用性能优化方面的SQL语句
- sql语句性能优化介绍
- 性能优化分析案例---解决SQL语句过度消耗CPU问题
- 优化临时表使用,SQL语句性能提升100倍
- 数据库性能优化之SQL语句优化(下)
- 数据库性能优化分析案例---解决SQL语句过度消耗CPU问题
- 秋色园QBlog技术原理解析:性能优化篇:打印页面SQL,全局的SQL语句优化(十三)
- SQL语句性能优化
- 性能优化:Sql语句中HINT不起作用
- SQL语句性能优化(续)
- 转:SQL Server数据库性能优化之SQL语句篇
- paip.程序功能时间性能优化及SQL语句优化
- 数据库性能优化之SQL语句优化
- SQL Server数据库性能优化之SQL语句篇
- 数据库性能优化之SQL语句优化
- 数据库性能优化之SQL语句优化(上)
- 【查询优化】怎样用SQL语句查看查询的性能指标
- SQL CASE WHEN语句性能优化
- 数据库性能优化之SQL语句优化