Manacher’s Algorithm( O(n)最长回文串)
2014-04-17 19:14
316 查看
An O(N) Solution (Manacher’s Algorithm):
First, we transform the input string, S, to another string T by inserting a special character ‘#’ in between letters. The reason for doing so will be immediately clear to you soon.
For example: S = “abaaba”, T = “#a#b#a#a#b#a#”.
To find the longest palindromic substring, we need to expand around each Ti such that Ti-d … Ti+d forms a palindrome. You should immediately see thatd is the length of the palindrome itself centered at Ti.
We store intermediate result in an array P, where P[ i ] equals to the length of the palindrome centers at Ti. The longest palindromic substring would then be the maximum element in P.
Using the above example, we populate P as below (from left to right):
Looking at P, we immediately see that the longest palindrome is “abaaba”, as indicated by P6 = 6.
Did you notice by inserting special characters (#) in between letters, both palindromes of odd and even lengths are handled graciously? (Please note: This is to demonstrate the idea more easily and is not necessarily needed to code the algorithm.)
Now, imagine that you draw an imaginary vertical line at the center of the palindrome “abaaba”. Did you notice the numbers in P are symmetric around this center? That’s not only it, try another palindrome “aba”, the numbers also reflect similar symmetric
property. Is this a coincidence? The answer is yes and no. This is only true subjected to a condition, but anyway, we have great progress, since we can eliminate recomputing part of P[ i ]‘s.
Let us move on to a slightly more sophisticated example with more some overlapping palindromes, where S = “babcbabcbaccba”.

Above image shows T transformed from S = “babcbabcbaccba”. Assumed that you reached a state where table P is partially completed. The solid vertical line indicates the center (C) of the palindrome “abcbabcba”. The two dotted vertical
line indicate its left (L) and right (R) edges respectively. You are at index i and its mirrored index around C is i’. How would you calculate P[ i ] efficiently?
Assume that we have arrived at index i = 13, and we need to calculate P[ 13 ] (indicated by the question mark ?). We first look at its mirrored index i’ around the palindrome’s center C, which is index i’ = 9.

The two green solid lines above indicate the covered region by the two palindromes centered at i and i’. We look at the mirrored index of i around C, which is index i’. P[ i' ] = P[ 9 ] = 1. It is clear that P[ i ] must also be
1, due to the symmetric property of a palindrome around its center.
As you can see above, it is very obvious that P[ i ] = P[ i' ] = 1, which must be true due to the symmetric property around a palindrome’s center. In fact, all three elements after C follow the symmetric property (that is, P[ 12 ] = P[ 10 ] = 0, P[ 13 ]
= P[ 9 ] = 1, P[ 14 ] = P[ 8 ] = 0).

Now we are at index i = 15, and its mirrored index around C is i’ = 7. Is P[ 15 ] = P[ 7 ] = 7?
Now we are at index i = 15. What’s the value of P[ i ]? If we follow the symmetric property, the value ofP[ i ] should be the same as P[ i' ] = 7. But this is wrong. If we expand around the center at T15, it forms the
palindrome “a#b#c#b#a”, which is actually shorter than what is indicated by its symmetric counterpart. Why?

Colored lines are overlaid around the center at index i and i’. Solid green lines show the region that must match for both sides due to symmetric property around C. Solid red lines show the region that might not match for both sides.
Dotted green lines show the region that crosses over the center.
It is clear that the two substrings in the region indicated by the two solid green lines must match exactly. Areas across the center (indicated by dotted green lines) must also be symmetric. Notice carefully that P[ i ' ] is 7 and it expands all the way
across the left edge (L) of the palindrome (indicated by the solid red lines), which does not fall under the symmetric property of the palindrome anymore. All we know isP[ i ] ≥ 5, and to find the real value of P[ i ] we have to do character matching
by expanding past the right edge (R). In this case, since P[ 21 ] ≠ P[ 1 ], we conclude that P[ i ] = 5.
Let’s summarize the key part of this algorithm as below:
if P[ i' ] ≤ R – i,
then P[ i ] ← P[ i' ]
else P[ i ] ≥ P[ i' ]. (Which we have to expand past the right edge (R) to find P[ i ].
See how elegant it is? If you are able to grasp the above summary fully, you already obtained the essence of this algorithm, which is also the hardest part.
The final part is to determine when should we move the position of C together with R to the right, which is easy:
If the palindrome centered at i does expand past R, we update C to i, (the center of this new palindrome), and extend R to the new palindrome’s right edge.
In each step, there are two possibilities. If P[ i ] ≤ R – i, we set P[ i ] to P[ i' ] which takes exactly one step. Otherwise we attempt to change the palindrome’s center to i by expanding it starting at the right edge, R. Extending R (the inner while loop)
takes at most a total of N steps, and positioning and testing each centers take a total of N steps too. Therefore, this algorithm guarantees to finish in at most 2*N steps, giving a linear time solution.
// Transform S into T. // For example, S = "abba", T = "^#a#b#b#a#$". // ^ and $ signs are sentinels appended to each end to avoid bounds checking string preProcess(string s) { int n = s.length(); if (n == 0) return "^$"; string ret = "^"; for (int i = 0; i < n; i++) ret += "#" + s.substr(i, 1); ret += "#$"; return ret; } string longestPalindrome(string s) { string T = preProcess(s); int n = T.length(); int *P = new int ; int C = 0, R = 0; for (int i = 1; i < n-1; i++) { int i_mirror = 2*C-i; // equals to i' = C - (i-C) P[i] = (R > i) ? min(R-i, P[i_mirror]) : 0; // Attempt to expand palindrome centered at i while (T[i + 1 + P[i]] == T[i - 1 - P[i]]) P[i]++; // If palindrome centered at i expand past R, // adjust center based on expanded palindrome. if (i + P[i] > R) { C = i; R = i + P[i]; } } // Find the maximum element in P. int maxLen = 0; int centerIndex = 0; for (int i = 1; i < n-1; i++) { if (P[i] > maxLen) { maxLen = P[i]; centerIndex = i; } } delete[] P; return s.substr((centerIndex - 1 - maxLen)/2, maxLen); }
Note:
This algorithm is definitely non-trivial and you won’t be expected to come up with such algorithm during an interview setting. However, I do hope that you enjoy reading this article and hopefully it helps you in understanding this interesting algorithm. You
deserve a pat if you have gone this far!

Further Thoughts:
In fact, there exists a sixth solution to this problem — Using suffix trees. However, it is not as efficient as this one (run time O(N log N) and more overhead for building suffix trees) and is more complicated to implement. If you are interested, read
Wikipedia’s article about
Longest Palindromic Substring.
What if you are required to find the longest palindromic subsequence? (Do you know the difference between substring and subsequence?)
首先用一个非常巧妙的方式,将所有可能的奇数/偶数长度的回文子串都转换成了奇数长度:在每个字符的两边都插入一个特殊的符号。比如 abba 变成 #a#b#b#a#, aba变成 #a#b#a#。 为了进一步减少编码的复杂度,可以在字符串的开始加入另一个特殊字符,这样就不用特殊处理越界问题,比如$#a#b#a#(注意,下面的代码是用C语言写就,由于C语言规范还要求字符串末尾有一个'\0'所以正好OK,但其他语言可能会导致越界)。
下面以字符串12212321为例,经过上一步,变成了 S[] = "$#1#2#2#1#2#3#2#1#";
然后用一个数组 P[i] 来记录以字符S[i]为中心的最长回文子串向左/右扩张的长度(包括S[i]),比如S和P的对应关系:
S # 1 # 2 # 2 # 1 # 2 # 3 # 2 # 1 #
P 1 2 1 2 5 2 1 4 1 2 1 6 1 2 1 2 1
(p.s. 可以看出,P[i]-1正好是原字符串中回文串的总长度)
那么怎么计算P[i]呢?该算法增加两个辅助变量(其实一个就够了,两个更清晰)id和mx,其中id表示最大回文子串中心的位置,mx则为id+P[id],也就是最大回文子串的边界。
然后可以得到一个非常神奇的结论,这个算法的关键点就在这里了:如果mx > i,那么P[i] >= MIN(P[2 * id - i], mx - i)。就是这个串卡了我非常久。实际上如果把它写得复杂一点,理解起来会简单很多:
当然光看代码还是不够清晰,还是借助图来理解比较容易。
当 mx - i > P[j] 的时候,以S[j]为中心的回文子串包含在以S[id]为中心的回文子串中,由于 i 和 j 对称,以S[i]为中心的回文子串必然包含在以S[id]为中心的回文子串中,所以必有 P[i] = P[j],见下图。
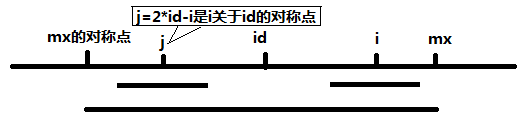
当 P[j] >= mx - i 的时候,以S[j]为中心的回文子串不一定完全包含于以S[id]为中心的回文子串中,但是基于对称性可知,下图中两个绿框所包围的部分是相同的,也就是说以S[i]为中心的回文子串,其向右至少会扩张到mx的位置,也就是说 P[i] >= mx - i。至于mx之后的部分是否对称,就只能老老实实去匹配了。
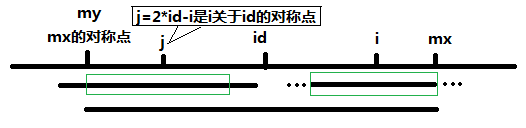
对于 mx <= i 的情况,无法对 P[i]做更多的假设,只能P[i] = 1,然后再去匹配了。
于是代码如下:
//输入,并处理得到字符串s
//找出p[i]中最大的
OVER.
#UPDATE@2013-08-21 14:27
@zhengyuee 同学指出,由于 P[id] = mx,所以 S[id-mx] != S[id+mx],那么当 P[j] > mx - i 的时候,可以肯定 P[i] = mx - i ,不需要再继续匹配了。不过在具体实现的时候即使不考虑这一点,也只是多一次匹配(必然会fail),但是却要多加一个分支,所以上面的代码就不改了。
First, we transform the input string, S, to another string T by inserting a special character ‘#’ in between letters. The reason for doing so will be immediately clear to you soon.
For example: S = “abaaba”, T = “#a#b#a#a#b#a#”.
To find the longest palindromic substring, we need to expand around each Ti such that Ti-d … Ti+d forms a palindrome. You should immediately see thatd is the length of the palindrome itself centered at Ti.
We store intermediate result in an array P, where P[ i ] equals to the length of the palindrome centers at Ti. The longest palindromic substring would then be the maximum element in P.
Using the above example, we populate P as below (from left to right):
T = # a # b # a # a # b # a # P = 0 1 0 3 0 1 6 1 0 3 0 1 0
Looking at P, we immediately see that the longest palindrome is “abaaba”, as indicated by P6 = 6.
Did you notice by inserting special characters (#) in between letters, both palindromes of odd and even lengths are handled graciously? (Please note: This is to demonstrate the idea more easily and is not necessarily needed to code the algorithm.)
Now, imagine that you draw an imaginary vertical line at the center of the palindrome “abaaba”. Did you notice the numbers in P are symmetric around this center? That’s not only it, try another palindrome “aba”, the numbers also reflect similar symmetric
property. Is this a coincidence? The answer is yes and no. This is only true subjected to a condition, but anyway, we have great progress, since we can eliminate recomputing part of P[ i ]‘s.
Let us move on to a slightly more sophisticated example with more some overlapping palindromes, where S = “babcbabcbaccba”.
Above image shows T transformed from S = “babcbabcbaccba”. Assumed that you reached a state where table P is partially completed. The solid vertical line indicates the center (C) of the palindrome “abcbabcba”. The two dotted vertical
line indicate its left (L) and right (R) edges respectively. You are at index i and its mirrored index around C is i’. How would you calculate P[ i ] efficiently?
Assume that we have arrived at index i = 13, and we need to calculate P[ 13 ] (indicated by the question mark ?). We first look at its mirrored index i’ around the palindrome’s center C, which is index i’ = 9.
The two green solid lines above indicate the covered region by the two palindromes centered at i and i’. We look at the mirrored index of i around C, which is index i’. P[ i' ] = P[ 9 ] = 1. It is clear that P[ i ] must also be
1, due to the symmetric property of a palindrome around its center.
As you can see above, it is very obvious that P[ i ] = P[ i' ] = 1, which must be true due to the symmetric property around a palindrome’s center. In fact, all three elements after C follow the symmetric property (that is, P[ 12 ] = P[ 10 ] = 0, P[ 13 ]
= P[ 9 ] = 1, P[ 14 ] = P[ 8 ] = 0).
Now we are at index i = 15, and its mirrored index around C is i’ = 7. Is P[ 15 ] = P[ 7 ] = 7?
Now we are at index i = 15. What’s the value of P[ i ]? If we follow the symmetric property, the value ofP[ i ] should be the same as P[ i' ] = 7. But this is wrong. If we expand around the center at T15, it forms the
palindrome “a#b#c#b#a”, which is actually shorter than what is indicated by its symmetric counterpart. Why?
Colored lines are overlaid around the center at index i and i’. Solid green lines show the region that must match for both sides due to symmetric property around C. Solid red lines show the region that might not match for both sides.
Dotted green lines show the region that crosses over the center.
It is clear that the two substrings in the region indicated by the two solid green lines must match exactly. Areas across the center (indicated by dotted green lines) must also be symmetric. Notice carefully that P[ i ' ] is 7 and it expands all the way
across the left edge (L) of the palindrome (indicated by the solid red lines), which does not fall under the symmetric property of the palindrome anymore. All we know isP[ i ] ≥ 5, and to find the real value of P[ i ] we have to do character matching
by expanding past the right edge (R). In this case, since P[ 21 ] ≠ P[ 1 ], we conclude that P[ i ] = 5.
Let’s summarize the key part of this algorithm as below:
if P[ i' ] ≤ R – i,
then P[ i ] ← P[ i' ]
else P[ i ] ≥ P[ i' ]. (Which we have to expand past the right edge (R) to find P[ i ].
See how elegant it is? If you are able to grasp the above summary fully, you already obtained the essence of this algorithm, which is also the hardest part.
The final part is to determine when should we move the position of C together with R to the right, which is easy:
If the palindrome centered at i does expand past R, we update C to i, (the center of this new palindrome), and extend R to the new palindrome’s right edge.
In each step, there are two possibilities. If P[ i ] ≤ R – i, we set P[ i ] to P[ i' ] which takes exactly one step. Otherwise we attempt to change the palindrome’s center to i by expanding it starting at the right edge, R. Extending R (the inner while loop)
takes at most a total of N steps, and positioning and testing each centers take a total of N steps too. Therefore, this algorithm guarantees to finish in at most 2*N steps, giving a linear time solution.
// Transform S into T.
// For example, S = "abba", T = "^#a#b#b#a#$".
// ^ and $ signs are sentinels appended to each end to avoid bounds checking
string preProcess(string s) {
int n = s.length();
if (n == 0) return "^$";
string ret = "^";
for (int i = 0; i < n; i++)
ret += "#" + s.substr(i, 1);
ret += "#$";
return ret;
}
string longestPalindrome(string s) {
string T = preProcess(s);
int n = T.length();
int *P = new int
;
int C = 0, R = 0;
for (int i = 1; i < n-1; i++) {
int i_mirror = 2*C-i; // equals to i' = C - (i-C)
P[i] = (R > i) ? min(R-i, P[i_mirror]) : 0;
// Attempt to expand palindrome centered at i
while (T[i + 1 + P[i]] == T[i - 1 - P[i]])
P[i]++;
// If palindrome centered at i expand past R,
// adjust center based on expanded palindrome.
if (i + P[i] > R) {
C = i;
R = i + P[i];
}
}
// Find the maximum element in P.
int maxLen = 0;
int centerIndex = 0;
for (int i = 1; i < n-1; i++) {
if (P[i] > maxLen) {
maxLen = P[i];
centerIndex = i;
}
}
delete[] P;
return s.substr((centerIndex - 1 - maxLen)/2, maxLen);
}// Transform S into T. // For example, S = "abba", T = "^#a#b#b#a#$". // ^ and $ signs are sentinels appended to each end to avoid bounds checking string preProcess(string s) { int n = s.length(); if (n == 0) return "^$"; string ret = "^"; for (int i = 0; i < n; i++) ret += "#" + s.substr(i, 1); ret += "#$"; return ret; } string longestPalindrome(string s) { string T = preProcess(s); int n = T.length(); int *P = new int ; int C = 0, R = 0; for (int i = 1; i < n-1; i++) { int i_mirror = 2*C-i; // equals to i' = C - (i-C) P[i] = (R > i) ? min(R-i, P[i_mirror]) : 0; // Attempt to expand palindrome centered at i while (T[i + 1 + P[i]] == T[i - 1 - P[i]]) P[i]++; // If palindrome centered at i expand past R, // adjust center based on expanded palindrome. if (i + P[i] > R) { C = i; R = i + P[i]; } } // Find the maximum element in P. int maxLen = 0; int centerIndex = 0; for (int i = 1; i < n-1; i++) { if (P[i] > maxLen) { maxLen = P[i]; centerIndex = i; } } delete[] P; return s.substr((centerIndex - 1 - maxLen)/2, maxLen); }
This algorithm is definitely non-trivial and you won’t be expected to come up with such algorithm during an interview setting. However, I do hope that you enjoy reading this article and hopefully it helps you in understanding this interesting algorithm. You
deserve a pat if you have gone this far!
Further Thoughts:
In fact, there exists a sixth solution to this problem — Using suffix trees. However, it is not as efficient as this one (run time O(N log N) and more overhead for building suffix trees) and is more complicated to implement. If you are interested, read
Wikipedia’s article about
Longest Palindromic Substring.
What if you are required to find the longest palindromic subsequence? (Do you know the difference between substring and subsequence?)
首先用一个非常巧妙的方式,将所有可能的奇数/偶数长度的回文子串都转换成了奇数长度:在每个字符的两边都插入一个特殊的符号。比如 abba 变成 #a#b#b#a#, aba变成 #a#b#a#。 为了进一步减少编码的复杂度,可以在字符串的开始加入另一个特殊字符,这样就不用特殊处理越界问题,比如$#a#b#a#(注意,下面的代码是用C语言写就,由于C语言规范还要求字符串末尾有一个'\0'所以正好OK,但其他语言可能会导致越界)。
下面以字符串12212321为例,经过上一步,变成了 S[] = "$#1#2#2#1#2#3#2#1#";
然后用一个数组 P[i] 来记录以字符S[i]为中心的最长回文子串向左/右扩张的长度(包括S[i]),比如S和P的对应关系:
S # 1 # 2 # 2 # 1 # 2 # 3 # 2 # 1 #
P 1 2 1 2 5 2 1 4 1 2 1 6 1 2 1 2 1
(p.s. 可以看出,P[i]-1正好是原字符串中回文串的总长度)
那么怎么计算P[i]呢?该算法增加两个辅助变量(其实一个就够了,两个更清晰)id和mx,其中id表示最大回文子串中心的位置,mx则为id+P[id],也就是最大回文子串的边界。
然后可以得到一个非常神奇的结论,这个算法的关键点就在这里了:如果mx > i,那么P[i] >= MIN(P[2 * id - i], mx - i)。就是这个串卡了我非常久。实际上如果把它写得复杂一点,理解起来会简单很多:
//记j = 2 * id - i,也就是说 j 是 i 关于 id 的对称点。 if (mx - i > P[j]) P[i] = P[j]; else /* P[j] >= mx - i */ P[i] = mx - i; // P[i] >= mx - i,取最小值,之后再匹配更新。
当然光看代码还是不够清晰,还是借助图来理解比较容易。
当 mx - i > P[j] 的时候,以S[j]为中心的回文子串包含在以S[id]为中心的回文子串中,由于 i 和 j 对称,以S[i]为中心的回文子串必然包含在以S[id]为中心的回文子串中,所以必有 P[i] = P[j],见下图。
当 P[j] >= mx - i 的时候,以S[j]为中心的回文子串不一定完全包含于以S[id]为中心的回文子串中,但是基于对称性可知,下图中两个绿框所包围的部分是相同的,也就是说以S[i]为中心的回文子串,其向右至少会扩张到mx的位置,也就是说 P[i] >= mx - i。至于mx之后的部分是否对称,就只能老老实实去匹配了。
对于 mx <= i 的情况,无法对 P[i]做更多的假设,只能P[i] = 1,然后再去匹配了。
于是代码如下:
//输入,并处理得到字符串s
int p[1000], mx = 0, id = 0;
memset(p, 0, sizeof(p));
for (i = 1; s[i] != '\0'; i++) {
p[i] = mx > i ? min(p[2*id-i], mx-i) : 1;
while (s[i + p[i]] == s[i - p[i]]) p[i]++;
if (i + p[i] > mx) {
mx = i + p[i];
id = i;
}
}//找出p[i]中最大的
OVER.
#UPDATE@2013-08-21 14:27
@zhengyuee 同学指出,由于 P[id] = mx,所以 S[id-mx] != S[id+mx],那么当 P[j] > mx - i 的时候,可以肯定 P[i] = mx - i ,不需要再继续匹配了。不过在具体实现的时候即使不考虑这一点,也只是多一次匹配(必然会fail),但是却要多加一个分支,所以上面的代码就不改了。

相关文章推荐
- BZOJ 2565: 最长双回文串 [Manacher]
- 计蒜之道 初赛 第三场 题解 Manacher o(n)求最长公共回文串 线段树
- HDOJ-3068 最长回文 (manacher求最长回文串)
- bzoj 2565: 最长双回文串 manacher
- 【单调队列DP+manacher】BZOJ2565-最长双回文串
- Manacher算法求最长回文串
- 找到最长回文字符串 - Manacher's Algorithm
- Manacher【p4555】 [国家集训队]最长双回文串
- bzoj 2565: 最长双回文串(manacher)
- 最长回文---hdu3068 (回文串 manacher 算法模板)
- HYSBZ - 2565 最长双回文串 Manacher
- 字符串的最长回文串:Manacher’s Algorithm
- leetcode 5 Longest Palindromic Substring(Manacher算法求最长回文串)
- bzoj 2565 最长双回文串 - Manacher
- manacher算法求最长回文串 和 hdu 3068 最长回文串
- manacher(最长回文串)
- hdu----(4513)吉哥系列故事——完美队形II(manacher(最长回文串算法))
- Manacher算法,最长回文串,时间复杂度O(n)
- bzoj2565 最长双回文串 manacher
- manacher 算法(最长回文串)