Vim命令小结-指定词统计和提取指定词(正则表达式)
2014-03-19 17:15
459 查看
最近在做基于Nutch网络爬虫爬取数据及一些数据处理的内容,涉及到在网络爬虫爬取到的HTML文件中提取一些用户名,之前想的一直是导入数据库再进行操作,从而忽略了强大的Vim。
问题来源:
根据网络爬虫爬取了一些淘宝BBS的一些数据,dump出一些HTML文件数据,一共120多万行,如下所示:
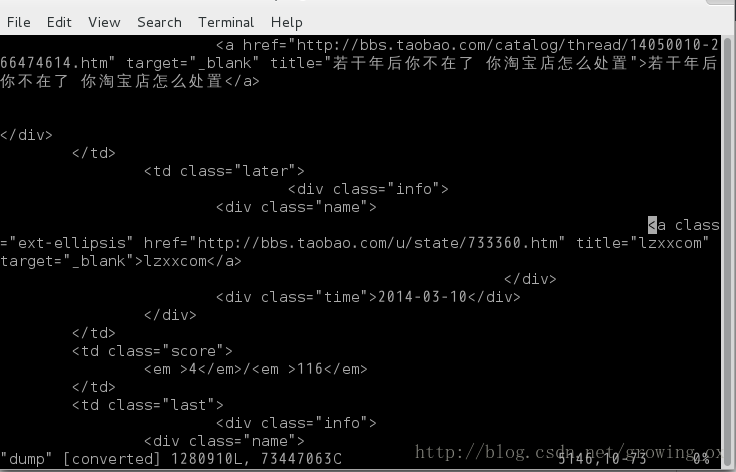
分析发现,含有用户名的具有统一的class=“ext-ellipasis”,想把如lzxxcom这样的用户全部提取出来。
实现思路:
1:先提取出ext-ellopsis所在的行。
2:根据正则表达式提取所需要的用户信息。
具体实现
1:vim查询pattern出现的个数
命令:--------:%s/pattern/&/g
解释:& 代表的意思就是用来表示前面比对的字串,所以做这个指令其实对档案本身并不会有什麽改变。但是由於做的是全域的取代置换, vim 会告诉你有从多少行中多少个字串被取代。轻轻松松很漂亮地用一行命令解决这个问题。
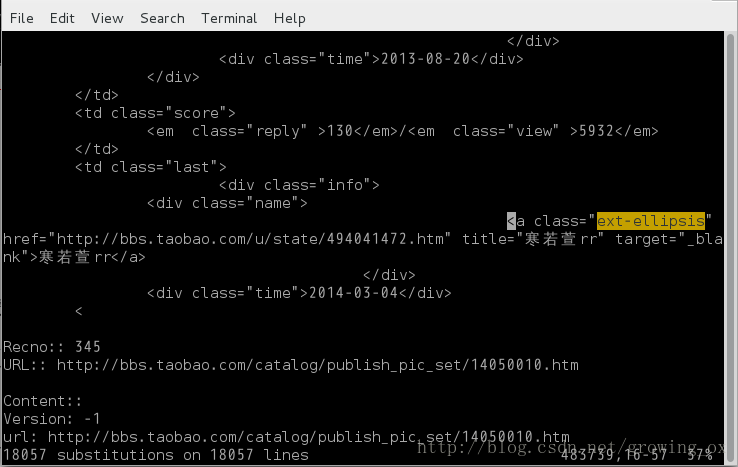
可以看出一共找到18057个ext-ellipsis.
2:先提取出ext-ellipsis所在的行
用g命令轻松搞定
:g/pattern/d 用于删除带有指定搜索内容的行。
:g!/pattern/d 用于删除不带指定搜索内容的行。:g! 命令也有一个别名是 :v。
使用:g!/ext-ellipsis/d 命令结果如下所示:
3:根据正则表达式提取所需要的用户信息
Vim打开文件后,使用如下正则表达式
:%s/.*="\(.*\)" .*/\1/g
得到如下结果
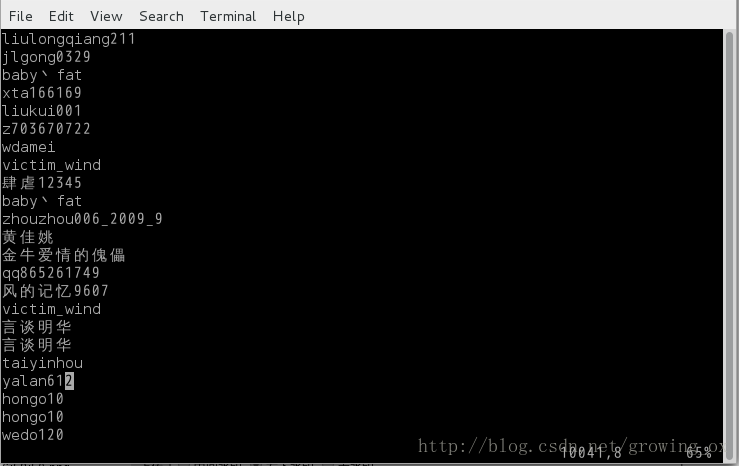
其中肯定有不少的重复的
进行以下操作
删除重复的用户名:
:g/^\(.*\)$\n\1$/d //去除重复行
:g/\%(^\1$\n\)\@<=\(.*\)$/d //功能同上,也是去除重复行
:g/\%(^\1\>.*$\n\)\@<=\(\k\+\).*$/d //功能同上,也是去除重复行
再进行排序:
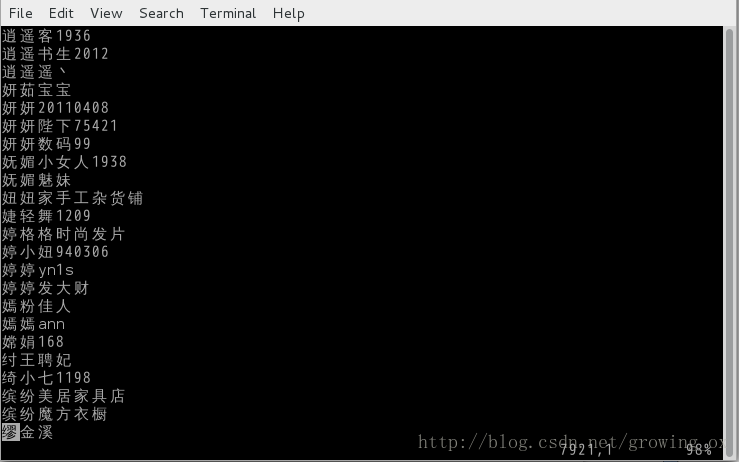
: sort //可以直接排序,这个太好用了
得到如下结果:
4:分行及E488:
Trailing characters
原因为此特殊符号在替换中有特殊意义
比如-----:%s///\r/g(根据/进行分行) 这样会出错,因为/有特殊含义。
必须改为-----:%s/\//\r/g 才可以
参考网站如下所示:
http://www.oschina.net/question/347219_124969-------提取文本指定内容 http://bbs.51cto.com/thread-964013-1.html----------删除重复行
http://edu.21cn.com/linux/g_188_793259-1.htm---------计算多少个搜寻关键词 http://www.cppblog.com/kefeng/archive/2010/10/20/130574.aspx?opt=admin-------正则表达式
问题来源:
根据网络爬虫爬取了一些淘宝BBS的一些数据,dump出一些HTML文件数据,一共120多万行,如下所示:
分析发现,含有用户名的具有统一的class=“ext-ellipasis”,想把如lzxxcom这样的用户全部提取出来。
实现思路:
1:先提取出ext-ellopsis所在的行。
2:根据正则表达式提取所需要的用户信息。
具体实现
1:vim查询pattern出现的个数
命令:--------:%s/pattern/&/g
解释:& 代表的意思就是用来表示前面比对的字串,所以做这个指令其实对档案本身并不会有什麽改变。但是由於做的是全域的取代置换, vim 会告诉你有从多少行中多少个字串被取代。轻轻松松很漂亮地用一行命令解决这个问题。
可以看出一共找到18057个ext-ellipsis.
2:先提取出ext-ellipsis所在的行
用g命令轻松搞定
:g/pattern/d 用于删除带有指定搜索内容的行。
:g!/pattern/d 用于删除不带指定搜索内容的行。:g! 命令也有一个别名是 :v。
使用:g!/ext-ellipsis/d 命令结果如下所示:
3:根据正则表达式提取所需要的用户信息
Vim打开文件后,使用如下正则表达式
:%s/.*="\(.*\)" .*/\1/g
得到如下结果
其中肯定有不少的重复的
进行以下操作
删除重复的用户名:
:g/^\(.*\)$\n\1$/d //去除重复行
:g/\%(^\1$\n\)\@<=\(.*\)$/d //功能同上,也是去除重复行
:g/\%(^\1\>.*$\n\)\@<=\(\k\+\).*$/d //功能同上,也是去除重复行
再进行排序:
: sort //可以直接排序,这个太好用了
得到如下结果:
4:分行及E488:
Trailing characters
原因为此特殊符号在替换中有特殊意义
比如-----:%s///\r/g(根据/进行分行) 这样会出错,因为/有特殊含义。
必须改为-----:%s/\//\r/g 才可以
参考网站如下所示:
http://www.oschina.net/question/347219_124969-------提取文本指定内容 http://bbs.51cto.com/thread-964013-1.html----------删除重复行
http://edu.21cn.com/linux/g_188_793259-1.htm---------计算多少个搜寻关键词 http://www.cppblog.com/kefeng/archive/2010/10/20/130574.aspx?opt=admin-------正则表达式

相关文章推荐
- python学习笔记-正则表达式提取指定关键字
- 正则表达式提取指定内容
- 正则表达式提取图片路径 并过滤掉指定字符的写法
- 正则表达式提取指定内容
- VIM中的正则表达式及替换命令
- javascript正则表达式提取指定的字符 分享如何随机播放采集的优酷视频地址
- 正则表达式小结,数据预处理中常用的shell命令
- VIM中的正则表达式及替换命令
- VIM中的正则表达式及替换命令
- python 根据正则表达式提取指定的内容实例详解
- VIM中的正则表达式及替换命令
- [python]根据正则表达式提取指定的内容
- python 根据正则表达式提取指定的内容实例详解
- VIM中的正则表达式及替换命令
- 在linux下如何用正则表达式执行ifconfig命令,只提取IP地址!
- 用正则表达式提取html中的一个指定div对
- sed及正则表达式随手记之一:用以提取stat命令结果的数字权限形式
- java正则表达式例程 提取网页中的email 统计代码的空行 有效代码行 注释行
- 正则表达式提取图片路径 并过滤掉指定字符的写法
- vim全局替换命令及正则表达式