Apache Spark - Cluster Mode Overview (Spark集群模式一览)
2014-03-08 12:27
453 查看
Apache Spark 集群模式一览
Components 组件
获得在集群中各节点的 executors (运行计算或存储数据的工作进程). 然后, 发送程序代码 (通过 JAR 或 Python 文件定义,发送到 SparkContext) 到 executors. 最后, SparkContext 为executors发送 tasks 用于执行.
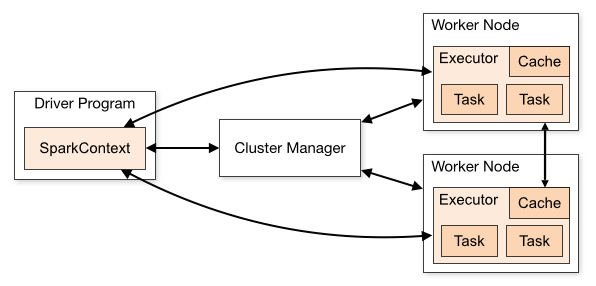
架构中有些有用的信息需要注意:
每个应用程序都有独立的 executor 进程, 他们的作用是维持应用程序和在多线程中运行 tasks . 好处在于在调度端 (每个计划tasks 的驱动) 和executor端 (不同JVM下的的各种tasks )都是封闭的. 但是, 这意味着数据在不同的Spark应用程序(SparkContext的实例)中无法共享,除非将这些数据写入外部存储系统.
Spark 对下层的 cluster manager来说是不可知的. 只要他能接受 executor 进程, 并且相互连接, 运行轻而易举。在其他 cluster manager中也是如此(例如 Mesos/YARN).
由于driver计划了cluster 中的tasks, 它可能会在worker node附近运行, 最好是在本地局域网. ,如果你想向cluster 发送远程请求,最好向driver打开RPC执行近端操作而不是在worker node上远程 运行driver.
Cluster Manager Types 集群管理者类型
Standalone – Spark 中包含的一个简单地 cluster manager 可以方便的建立一个cluster.
Apache Mesos – 一个通用的 cluster manager ,能够运行 Hadoop
MapReduce 和服务应用.
Hadoop YARN – Hadoop 2中的资源管理者.
此外, Spark的 EC2 launch scripts 可以在Amazon EC2上方便的建立一个单独集群.
Shipping Code to the Cluster 发送代码到集群
还可以通过
SparkContext.addJar和
addFile动态加入新文件到executors.
用于addJar / addFile的URIs
file:/URIs (由 HTTP 文件服务器提供), 每个 executor
从HTTP服务器中下载文件
hdfs:, http:, https:, ftp: - 通过 URI
下载文件和JARs
local: - 以 local:/ 开头的URIis 意味着每个工作节点都有本地文件. 也就是说不会进行网络IO操作, 同时大型的files/JARs会运行更好, 或者通过 NFS, GlusterFS等共享.
注意:
为了构建executor节点的SparkContext ,这些
JARs 和 files 被拷贝到每个工作目录. 这将会占用大量空间,请及时清理.
Monitoring 性能监控
http://<driver-node>:4040就能看到这个界面. monitoring
guide 会描述其他的监控选项.
Job Scheduling 任务调度
Glossary 术语表
| Term | Meaning |
|---|---|
| Application | 使用Spark构建的用户程序. 包括集群中的驱动程序(driver program)和执行器(executors). |
| Driver program | 用于运行main()和构建SparkContext的进程 |
| Cluster manager | 集群中获取资源的对外服务 (例如. Spark中的standalone manager, Mesos, YARN) |
| Worker node | 集群中可以运行程序的任意节点 |
| Executor | 在worker node上开始application的进程, 它运行tasks,在内存或硬盘中保持数据. 每个application都有自己的executors. |
| Task | 发送到 executor的工作单元 |
| Job | 由多tasks构成的并行计算,引起Spark的action (例如. save, collect); 你将会在driver的logs中看到这些术语. |
| Stage | 每个Job被分成多个被称之为Stage的任务集 ,他们相互依赖(类似于MapReduce中的 map 和reduce步骤); 你将会在driver的logs中看到这些术语. |

相关文章推荐
- spark官方文档翻译_Cluster Mode Overview
- spark第四篇:Cluster Mode Overview
- Spark Cluster Mode Overview
- spark源码学习(六):standalone模式的cluster集群源码解读
- 【甘道夫】Spark1.3.0 Cluster Mode Overview 官方文档精华摘要
- Apache Spark集群模式选择
- Apache Spark源码走读之19 -- standalone cluster模式下资源的申请与释放
- Spark官方文档——独立集群模式(Standalone Mode)
- Apache Spark 2.2.0 中文文档 - 集群模式概述 | ApacheCN
- spark-Cluster Mode Overview整理学习
- Apache Spark 2.2.0 中文文档 - 集群模式概述 | ApacheCN
- Spark on yarn client 和cluster模式运行序列图
- Apache Spark源码走读之15 -- Standalone部署模式下的容错性分析
- Spark Standalone模式集群 对TIDB/Mysql支持
- apache+inotify-tools+keepalived+lvs-DR模式配置高可用负载均衡集群
- Spark2.2.1 on yarn 模式集群安装
- Spark On Yarn的两种模式yarn-cluster和yarn-client深度剖析
- Spark on Yarn Client和Cluster模式详解
- Spark Streaming揭秘 Day30 集群模式下SparkStreaming日志分析
- Spark on YARN集群模式作业运行全过程分析