JAVA代码执行机制
2014-03-07 16:58
169 查看
1.java源码编译机制
jvm规范中定义了class文件的格式,但并未定义Java源码如何编译为class文件,在Sun JDK中就是javac编译器,可分为下面三个步骤:
1.分析和输入到符号表(Parse and Enter)
Parse 过程所做的是词法和语法分析
Enter 过程是将符号输入到符号表
2.注解处理(Annotation Processing)
该步骤主要用于处理用户自定义的annotation,可能带来的好处是基于annotation来生成附加的代码,如:
public class User{ private @Getter String username; }
编译时引入Lombok对User.java进行编译后,再通过javap查看class文件可看到自动生成了public String getUsername()方法
3.语义分析和生成class文件(Analyse and Generate)
class 文件中并不仅仅存放了字节码,还存放了很多辅助jvm来执行class文件的附加信息,一个class文件包含了以下信息:
结构信息:包括class文件格式版本号及各部分的数量与大小的信息
元数据:可以认为元数据就是java源码中“声明”与“常量”信息
方法信息:可以说就是java源码中“语句”和“表达式”对应的信息
class文件是个完整的自描述文件,字节码在其中只占了很小的部分,源码编译为class文件后,即可放入jvm中执行,执行时jvm首先要做的是装载class文件,这个就是类加载机制
2.类加载机制
jvm将类加载过程划分为三个步骤:
1.装载(Load) 装载过程负责找到二进制字节码并加载到jvm中,jvm通过类的全限定义名(com.bluedavy.HelloWord)及类加载器(ClassLoaderA 实例)完成类的加载,同样,也采用以上两个素来标识一个被加载了的类:类的全限定名+ClassLoader 实例ID,类名的命名方式如下:
对于接口式非数组型的类,其名称即为类名,此种类型的类由所在的ClassLoader负责加载:数组型类中的元素类型由所在的ClassLoader负责加载,但数组类则由JVM直接创建。
2.链接(Link) 链接过程负责对二进制字节码的格式进行校验、初始化装载类中的静态变量及解析类中调用的接口、类。
3.初始化(Initialize)初始化过程即即执行类中的静态初始化代码、构造器代码及静态属性的初始化,在下面的四种情况下初始化过程会被触发执行:
调用了new
反射调用了类中的方法
子类调用了初始化
JVM启动过程中指定的初始化类
JVM的类加载通过ClassLoader及其子类来完成,分为Bootstrap ClassLoader、Extensin ClassLoader、System ClassLoader(在Sun JDK中对应的类名为AppClassLoader)及 User-Defined ClassLoader,其关系如下图:
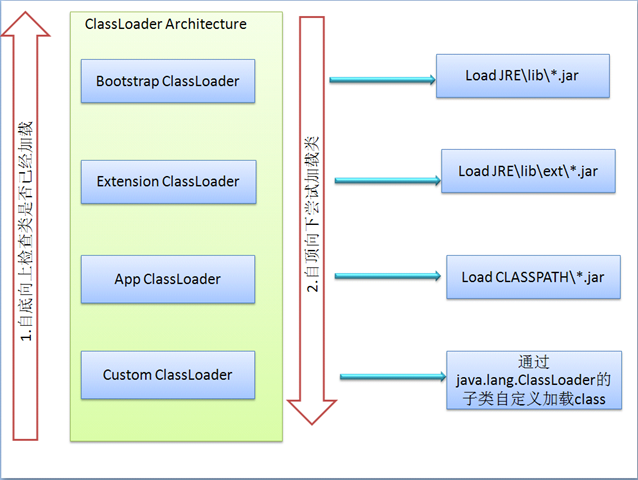
1.Bootstrap ClassLoader Sun JDK 采用C++实现了此类,此类并非ClassLoader的子类,在代码中没有办法拿到这个对象,Sun JDK 启动时会初始化此ClassLoader,并由ClassLoader完成$JAVA_HOME 中jre/lib/rt.jar里所有class文件的加载;
2.Extension ClassLoader JVM用此ClassLoader来加载扩展功能的一些jar包,例如JDK中dns工具jar包等,对应的类名为ExtClassLoader;
3.System ClassLoader JVM 用此ClassLoader来加载启动参数中指定的Classpath中的jar包及目录,在Sun JDK中ClassLoader对应的类名为AppClassLoader;
4.User-Defined ClassLoader 这是开发人员继承ClassLoader抽象类自行实现的ClassLoader,可以用加载非Classpath中的jar及目录、还可以在加载之前对class文件做一些动作,例如解密等;
JVM会保证同一个ClassLoader实例对象中只能加载一次同样名称的Class
Cloader抽象类提供了几个关键的方法
loadClass 此方法负责加载指定名字的类,ClassLoader的实现方法为先从已经加载的类中寻找,如没有,则继续从 parent ClassLoader中寻找;如果仍然没有找到,则从System ClassLoader中寻找,最后再调用findClass方法来寻找;如果最终没有找到就抛出ClassNotFoundException;
findLoaderClass 方法负责从当前ClassLoader实例对象的缓存中寻找已加载的类,调用的为native的方法;
findClass 此方法直接抛出ClassNotFoundException,因此要通过覆盖loadClass或此方法来以自定义的方式加载相应的类;
findSystemClass 此负责从System ClassLoader 中寻找,如未找到,则继续从Bootstrap ClassLoader 中寻找,如果仍然未找到,则返回null;
defineClass 此方法负责将二进制的字节码转换成Class对象,如果二进制的字节码的格式不符合JVM Class文件的格式,则抛出ClassFormatError;如果生成的类名和二进制字节码中的不同,则抛出NoClassDefFoundError;如果加载的class是受保护的、采用不同签名的或者类名是以java.开头的,则抛出SecurityException;如果加载的class在此ClassLoader中已加载,则抛出LinkageError;
resolveClass 此方法负责完成Class对象的链接,如果链接过,则会直接返回;
3.类的执行机制
在源码编译阶段源码编译为JVM字节码,JVM字节码是一种中间代码的方式,要由JVM在运行期对其进行解释并执行,这种方式称为字节码解释执行方式;
1.字节码解释执行
JVM采用了invokestatic,invokevirtual,invokeinterface和invokespecial四个指令来执行不同的方法调用。
invokestatic对应的是调用static方法,invokevirtual对应的是调用对象实例的方法,invokeinterface对应的是调用接口的方法,invokespecial对应的是调用private方法和编译源码后生成的<init>方法;
Sun JDK基于栈的体系结构来执行字节码,基于栈方式的好处为代码紧凑,体积小,线程在创建后,都会产生程序计数器(pc)(或称为PC registers)和栈(Stack);PC存放了下一条要执行的指令在方法内的偏移量;栈中存放了栈帧(StackFrame),每个方法每次调用都会产生栈帧。栈帧主要分为局部变量区和操作数栈两部分,局部变量区用于存放方法中的局部变量和参数,操作数栈中用于存放方法执行过程中产生的中间结果,栈帧中还会有一些杂用空间,例如指向方法已解析的常量池的引用、其他一些JVM内部实现需要的数据等;
2.编译执行
解释执行的效率较低,Sun JDK在执行过程中对执行频率高的代码进行编译,对执行不频繁的代码则继续采用解释的方式;在编译上Sun JDK提供了两种模式:client compiler(-client)和server compiler(-server)。
client compiler又称为C1,较为轻量级,只做少量性能开销比高的优化,它占用内存较少,适合于桌面交互式应用,其他方面的优化主要有:
方法内联 这种方法把调用到的方法的指令直接植入当前方法中,如下代码:
Java代码



public void bar(){
....
bar2();
....
}
private void bar2(){
//bar2;
}
[java] view
plaincopy
public void bar(){
....
bar2();
....
}
private void bar2(){
//bar2;
}
上面代码编译后就变成类似下面的结构:
Java代码
public void bar(){
....
//bar2
....
}
[java] view
plaincopy
public void bar(){
....
//bar2
....
}
去虚拟化 去虚拟化是指在装载class文件后,进行类层次的分析,如发现类中的方法只提供一个实现类,那么对于调用了此方法的代码,也可进行方法内联;
冗余削除 冗余削除是指在编译时,根据运行时状况进行代码折叠或削除,例如一段这样的代码:
Java代码
public void execute(){
if(isDebug){
log.debug("enter this method: execute");
}
//do something
}
[java] view
plaincopy
public void execute(){
if(isDebug){
log.debug("enter this method: execute");
}
//do something
}
如isDebug的值是false,在执行C1编译后,这段代码就变成类似下面的结构:
Java代码
public void execute(){
//do something
}
[java] view
plaincopy
public void execute(){
//do something
}
Server compiler又称C2,较为重量级,它采用大量的传统编译优化技巧来进行优化,占用内存相对会多一些,适合于服务器端的应用;逃逸分析是C2进行很多优化的基础,逃逸分析是指根据运行状况来判断方法中的变量是否会被外部读取,如不会则认为此变量是逃逸的,基于逃逸分析C2在编译时会标量替换,栈上分配和同步消除等优化;
标量替换 就是用标量替换聚合量,例如下面这段代码:
Java代码
Point point=new Point(1,2);
ystem.out.println("point.x="+point.x+";point.y"+point.y);
[java] view
plaincopy
Point point=new Point(1,2);
ystem.out.println("point.x="+point.x+";point.y"+point.y);
当point对象在后面的执行过程中未用到时,经过编译后,代码会变成类似下面的结构:
Java代码
int x=1;
int y=2;
System.out.println("point.x="+x+";point.y"+y);
[java] view
plaincopy
int x=1;
int y=2;
System.out.println("point.x="+x+";point.y"+y);
栈上分配 在上面的例子中,如果p没有逃逸,那么C2会选择在栈上直接创建Point对象实例,而不是在堆上;
同步削除 指如果发现同步的对象未逃逸,那也没有同步的必要了,在C2编译时会直接去掉同步,例如:
Java代码
Point point=new Point(1,2);
synchronized(point) {
//do something;
}
[java] view
plaincopy
Point point=new Point(1,2);
synchronized(point) {
//do something;
}
经过分析如果发现point未逃逸,在编译后,代码就会变成下面的结构:
Java代码
Point point = new Point(1,2);
//do something
[java] view
plaincopy
Point point = new Point(1,2);
//do something
Sun JDK之所以未选择在启动时即编译成机器码,有下面几个原因:
静态编译并不能根据程序的运行状况来优化执行的代码
解释执行比编译执行更节省内存
启动解释执行的启动速度比编译再启动更快
jvm规范中定义了class文件的格式,但并未定义Java源码如何编译为class文件,在Sun JDK中就是javac编译器,可分为下面三个步骤:
1.分析和输入到符号表(Parse and Enter)
Parse 过程所做的是词法和语法分析
Enter 过程是将符号输入到符号表
2.注解处理(Annotation Processing)
该步骤主要用于处理用户自定义的annotation,可能带来的好处是基于annotation来生成附加的代码,如:
public class User{ private @Getter String username; }
编译时引入Lombok对User.java进行编译后,再通过javap查看class文件可看到自动生成了public String getUsername()方法
3.语义分析和生成class文件(Analyse and Generate)
class 文件中并不仅仅存放了字节码,还存放了很多辅助jvm来执行class文件的附加信息,一个class文件包含了以下信息:
结构信息:包括class文件格式版本号及各部分的数量与大小的信息
元数据:可以认为元数据就是java源码中“声明”与“常量”信息
方法信息:可以说就是java源码中“语句”和“表达式”对应的信息
class文件是个完整的自描述文件,字节码在其中只占了很小的部分,源码编译为class文件后,即可放入jvm中执行,执行时jvm首先要做的是装载class文件,这个就是类加载机制
2.类加载机制
jvm将类加载过程划分为三个步骤:
1.装载(Load) 装载过程负责找到二进制字节码并加载到jvm中,jvm通过类的全限定义名(com.bluedavy.HelloWord)及类加载器(ClassLoaderA 实例)完成类的加载,同样,也采用以上两个素来标识一个被加载了的类:类的全限定名+ClassLoader 实例ID,类名的命名方式如下:
对于接口式非数组型的类,其名称即为类名,此种类型的类由所在的ClassLoader负责加载:数组型类中的元素类型由所在的ClassLoader负责加载,但数组类则由JVM直接创建。
2.链接(Link) 链接过程负责对二进制字节码的格式进行校验、初始化装载类中的静态变量及解析类中调用的接口、类。
3.初始化(Initialize)初始化过程即即执行类中的静态初始化代码、构造器代码及静态属性的初始化,在下面的四种情况下初始化过程会被触发执行:
调用了new
反射调用了类中的方法
子类调用了初始化
JVM启动过程中指定的初始化类
JVM的类加载通过ClassLoader及其子类来完成,分为Bootstrap ClassLoader、Extensin ClassLoader、System ClassLoader(在Sun JDK中对应的类名为AppClassLoader)及 User-Defined ClassLoader,其关系如下图:
1.Bootstrap ClassLoader Sun JDK 采用C++实现了此类,此类并非ClassLoader的子类,在代码中没有办法拿到这个对象,Sun JDK 启动时会初始化此ClassLoader,并由ClassLoader完成$JAVA_HOME 中jre/lib/rt.jar里所有class文件的加载;
2.Extension ClassLoader JVM用此ClassLoader来加载扩展功能的一些jar包,例如JDK中dns工具jar包等,对应的类名为ExtClassLoader;
3.System ClassLoader JVM 用此ClassLoader来加载启动参数中指定的Classpath中的jar包及目录,在Sun JDK中ClassLoader对应的类名为AppClassLoader;
4.User-Defined ClassLoader 这是开发人员继承ClassLoader抽象类自行实现的ClassLoader,可以用加载非Classpath中的jar及目录、还可以在加载之前对class文件做一些动作,例如解密等;
JVM会保证同一个ClassLoader实例对象中只能加载一次同样名称的Class
Cloader抽象类提供了几个关键的方法
loadClass 此方法负责加载指定名字的类,ClassLoader的实现方法为先从已经加载的类中寻找,如没有,则继续从 parent ClassLoader中寻找;如果仍然没有找到,则从System ClassLoader中寻找,最后再调用findClass方法来寻找;如果最终没有找到就抛出ClassNotFoundException;
findLoaderClass 方法负责从当前ClassLoader实例对象的缓存中寻找已加载的类,调用的为native的方法;
findClass 此方法直接抛出ClassNotFoundException,因此要通过覆盖loadClass或此方法来以自定义的方式加载相应的类;
findSystemClass 此负责从System ClassLoader 中寻找,如未找到,则继续从Bootstrap ClassLoader 中寻找,如果仍然未找到,则返回null;
defineClass 此方法负责将二进制的字节码转换成Class对象,如果二进制的字节码的格式不符合JVM Class文件的格式,则抛出ClassFormatError;如果生成的类名和二进制字节码中的不同,则抛出NoClassDefFoundError;如果加载的class是受保护的、采用不同签名的或者类名是以java.开头的,则抛出SecurityException;如果加载的class在此ClassLoader中已加载,则抛出LinkageError;
resolveClass 此方法负责完成Class对象的链接,如果链接过,则会直接返回;
3.类的执行机制
在源码编译阶段源码编译为JVM字节码,JVM字节码是一种中间代码的方式,要由JVM在运行期对其进行解释并执行,这种方式称为字节码解释执行方式;
1.字节码解释执行
JVM采用了invokestatic,invokevirtual,invokeinterface和invokespecial四个指令来执行不同的方法调用。
invokestatic对应的是调用static方法,invokevirtual对应的是调用对象实例的方法,invokeinterface对应的是调用接口的方法,invokespecial对应的是调用private方法和编译源码后生成的<init>方法;
Sun JDK基于栈的体系结构来执行字节码,基于栈方式的好处为代码紧凑,体积小,线程在创建后,都会产生程序计数器(pc)(或称为PC registers)和栈(Stack);PC存放了下一条要执行的指令在方法内的偏移量;栈中存放了栈帧(StackFrame),每个方法每次调用都会产生栈帧。栈帧主要分为局部变量区和操作数栈两部分,局部变量区用于存放方法中的局部变量和参数,操作数栈中用于存放方法执行过程中产生的中间结果,栈帧中还会有一些杂用空间,例如指向方法已解析的常量池的引用、其他一些JVM内部实现需要的数据等;
2.编译执行
解释执行的效率较低,Sun JDK在执行过程中对执行频率高的代码进行编译,对执行不频繁的代码则继续采用解释的方式;在编译上Sun JDK提供了两种模式:client compiler(-client)和server compiler(-server)。
client compiler又称为C1,较为轻量级,只做少量性能开销比高的优化,它占用内存较少,适合于桌面交互式应用,其他方面的优化主要有:
方法内联 这种方法把调用到的方法的指令直接植入当前方法中,如下代码:
Java代码
public void bar(){
....
bar2();
....
}
private void bar2(){
//bar2;
}
[java] view
plaincopy
public void bar(){
....
bar2();
....
}
private void bar2(){
//bar2;
}
上面代码编译后就变成类似下面的结构:
Java代码
public void bar(){
....
//bar2
....
}
[java] view
plaincopy
public void bar(){
....
//bar2
....
}
去虚拟化 去虚拟化是指在装载class文件后,进行类层次的分析,如发现类中的方法只提供一个实现类,那么对于调用了此方法的代码,也可进行方法内联;
冗余削除 冗余削除是指在编译时,根据运行时状况进行代码折叠或削除,例如一段这样的代码:
Java代码
public void execute(){
if(isDebug){
log.debug("enter this method: execute");
}
//do something
}
[java] view
plaincopy
public void execute(){
if(isDebug){
log.debug("enter this method: execute");
}
//do something
}
如isDebug的值是false,在执行C1编译后,这段代码就变成类似下面的结构:
Java代码
public void execute(){
//do something
}
[java] view
plaincopy
public void execute(){
//do something
}
Server compiler又称C2,较为重量级,它采用大量的传统编译优化技巧来进行优化,占用内存相对会多一些,适合于服务器端的应用;逃逸分析是C2进行很多优化的基础,逃逸分析是指根据运行状况来判断方法中的变量是否会被外部读取,如不会则认为此变量是逃逸的,基于逃逸分析C2在编译时会标量替换,栈上分配和同步消除等优化;
标量替换 就是用标量替换聚合量,例如下面这段代码:
Java代码
Point point=new Point(1,2);
ystem.out.println("point.x="+point.x+";point.y"+point.y);
[java] view
plaincopy
Point point=new Point(1,2);
ystem.out.println("point.x="+point.x+";point.y"+point.y);
当point对象在后面的执行过程中未用到时,经过编译后,代码会变成类似下面的结构:
Java代码
int x=1;
int y=2;
System.out.println("point.x="+x+";point.y"+y);
[java] view
plaincopy
int x=1;
int y=2;
System.out.println("point.x="+x+";point.y"+y);
栈上分配 在上面的例子中,如果p没有逃逸,那么C2会选择在栈上直接创建Point对象实例,而不是在堆上;
同步削除 指如果发现同步的对象未逃逸,那也没有同步的必要了,在C2编译时会直接去掉同步,例如:
Java代码
Point point=new Point(1,2);
synchronized(point) {
//do something;
}
[java] view
plaincopy
Point point=new Point(1,2);
synchronized(point) {
//do something;
}
经过分析如果发现point未逃逸,在编译后,代码就会变成下面的结构:
Java代码
Point point = new Point(1,2);
//do something
[java] view
plaincopy
Point point = new Point(1,2);
//do something
Sun JDK之所以未选择在启动时即编译成机器码,有下面几个原因:
静态编译并不能根据程序的运行状况来优化执行的代码
解释执行比编译执行更节省内存
启动解释执行的启动速度比编译再启动更快

相关文章推荐
- 深入理解JVM(二)------Java代码执行机制
- java代码的执行机制(分布式java应用笔记)
- 【java】之java代码的执行机制
- Java代码执行机制
- JVM原理(Java代码编译和执行的整个过程+JVM内存管理及垃圾回收机制)
- JAVA代码执行机制
- java代码的执行机制+JVM+GC
- 深入理解JVM(二)------Java代码执行机制
- [Java代码] JAVA 虚拟机类加载机制和字节码执行引擎
- Java代码执行机制
- 深入理解JVM(二)------Java代码执行机制
- JVM原理(Java代码编译和执行的整个过程+JVM内存管理及垃圾回收机制)
- java代码的执行机制+JVM+GC
- 两段交换代码轻松理解Java参数传递机制
- jexl2 执行字符串Java代码
- 执行纯字符串中的java代码,无需热编译,巧用javascirpt
- Java代码调用操作系统可执行文件打开相应文件一行代码实现
- java中计算一段代码执行的时间
- Java实现等待所有子线程结束后再执行一段代码的方法
- JSP中在JS函数中嵌套Java代码的执行问题