深入分析中文乱码原因
2014-02-10 16:33
260 查看
本文接着上一遍 解决上传文件时中文文件名乱码问题 中描述的场景深入分析哈乱码的原因。
假设上传文件为"美女.jpg",不做任何处理时,服务端获取的文件名为:

下面来还原汉字变乱码的过程,代码片段:
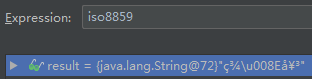
跟第一张乱码图中的乱码完全一样。猜测是tomcat或spring mvc处理上传请求时,使用了默认的 ISO-8859-1 来解码请求参数,导致我们获取的文件名为乱码。假设容器或mvc框架在处理请求中的字符串参数时使用该参数原本的编码对其进行编码,再使用ISO-8859-1来解码以获取字符串值,那么发现乱码时就可以通过逆向运算得到原本的字符串值,即先使用ISO-8859-1对乱码字符串进行编码,再使用该字符串原本的字符编码进行解码。上述代码还演示了误用其他字符编码(例如GBK)进行解码,得到乱码后,再通过逆运算还原回来。完整输出结果:
特别说明:由于我将windows的默认字符编码修改为UTF-8了,所以调用getBytes()进行编码时使用的就是UTF-8。
本文参考了一篇很赞的博文:深入分析Java中的中文编码问题,但是该文中对误用ISO-8859-1进行解码,乱码后通过再次编码、解码还原回来的解释无法让我信服:
这种情况是这样的,ISO-8859-1 字符集的编码范围是 0000-00FF,正好和一个字节的编码范围相对应。这种特性保证了使用 ISO-8859-1 进行编码和解码可以保持编码数值“不变”。虽然中文字符在经过网络传输时,被错误地“拆”成了两个欧洲字符,但由于输出时也是用 ISO-8859-1,结果被“拆”开的中文字的两半又被合并在一起,从而又刚好组成了一个正确的汉字。虽然最终能取得正确的汉字,但是还是不建议用这种不正常的方式取得参数值,因为这中间增加了一次额外的编码与解码,这种情况出现乱码时因为 Tomcat
的配置文件中 useBodyEncodingForURI 配置项没有设置为”true”,从而造成第一次解析式用 ISO-8859-1 来解析才造成乱码的。
上面的演示代码中我们误用GBK进行解码也能还原回来。所以我觉得能还原回来的原因很简单,就是逆向处理,就想数学中的逆运算一样,而非作者解释的那样。
到目前为止说深入有点汗颜呐,还有好多很基础的东西没搞清楚,先抛出来有空再深究吧。
http请求中的header、字符串参数及其他文本内容在发送给服务端时,是否需要先根据页面指定的字符编码转换为字节数组,才能在网络上传输?整个请求都需要转换为字节数组才能在网络上传输吗?
web容器为什么不知道正确的字符编码?
web容器或servlet如何解析并获取到参数值以及http header中各字段的内容(对上传来说就是Content-Disposition中的filename)?如果真如前面猜测的那样,容器在处理字符串参数或http header时,如何决定使用哪种字符编码进行编码、解码操作?
unicode汉字编码查询、unicode汉字编码查询2
假设上传文件为"美女.jpg",不做任何处理时,服务端获取的文件名为:
下面来还原汉字变乱码的过程,代码片段:
String beauty = "美女";
System.out.println("\"美女\" toCharArray:" + Arrays.toString(beauty.toCha
bace
rArray()));
System.out.println("\"美女\"的十六进制unicode码:" + Arrays.toString(Hex.encodeHexStr(beauty.toCharArray())));
System.out.println("OS Default Charset:" + Charset.defaultCharset().name());
System.out.println();
System.out.println("使用不同的字符编码方案对其进行编码:");
System.out.println("---------------------------------------------------------");
System.out.println("Default: " + Hex.encodeAndBeautifyHex(beauty.getBytes()));
System.out.println("UTF-8: " + Hex.encodeAndBeautifyHex(beauty.getBytes("UTF-8")));
System.out.println("ISO-8859-1:" + Hex.encodeAndBeautifyHex(beauty.getBytes("ISO-8859-1")));
System.out.println("GBK: " + Hex.encodeAndBeautifyHex(beauty.getBytes("GBK")));
System.out.println();
System.out.println("重现web页面文件上传时中文名乱码及还原过程:");
System.out.println("---------------------------------------------------------");
System.out.println("场景一、第一次获取字符串时误用ISO-8859-1进行解码:");
String iso8859 = new String(beauty.getBytes("UTF-8"), "ISO-8859-1");
System.out.println("bytes got by encoding with ISO-8859-1:" + Hex.encodeAndBeautifyHex(iso8859.getBytes("ISO-8859-1")));
System.out.println("1.先使用系统默认字符编码(UTF-8)对其进行编码,再使用ISO-8859-1对编码得到的字节数组进行解码:" + iso8859);
String originalStr = new String(iso8859.getBytes("ISO-8859-1"), "UTF-8");
System.out.println("2.先使用ISO-8859-1对第一步得到的乱码字符串进行编码,再使用UTF-8对编码得到的字节数组进行解码:" + originalStr);
System.out.println();
System.out.println("场景二、第一次获取字符串时误用GBK进行解码:");
String gbk = new String(beauty.getBytes("UTF-8"), "GBK");
System.out.println("bytes got by encoding with GBK:" + Hex.encodeAndBeautifyHex(gbk.getBytes("GBK")));
System.out.println("1.先使用UTF-8对其进行编码,再使用GBK对编码得到的字节数组进行解码:" + gbk);
originalStr = new String(gbk.getBytes("GBK"), "UTF-8");
System.out.println("2.先使用GBK对第一步得到的乱码字符串进行编码,再使用UTF-8对编码得到的字节数组进行解码:" + originalStr);
System.out.println();
System.out.println("各种乱码情况演示:");
System.out.println("---------------------------------------------------------");
String tao = "淘!我喜欢!";
// 中文变成了看不懂的字符
System.out.println("GBK 编码:" + Hex.encodeAndBeautifyHex(tao.getBytes("GBK")));
System.out.println("ISO-8859-1解码:" + new String(tao.getBytes("GBK"), "ISO-8859-1"));
// 一个汉字变成一个问号
System.out.println();
System.out.println("ISO-8859-1编码:" + Hex.encodeAndBeautifyHex(tao.getBytes("ISO-8859-1")));
System.out.println("ISO-8859-1解码:" + new String(tao.getBytes("ISO-8859-1"), "ISO-8859-1"));
// 一个汉字变成两个问号
System.out.println();
System.out.println("GBK 编码:" + Hex.encodeAndBeautifyHex(tao.getBytes("GBK")));
String tao2 = new String(tao.getBytes("GBK"), "ISO-8859-1");
System.out.println("ISO-8859-1解码:" + tao2);
System.out.println("GBK 编码:" + Hex.encodeAndBeautifyHex(tao2.getBytes("GBK")));
System.out.println("GBK 解码:" + new String(tao2.getBytes("GBK"), "GBK"));调试时,查看变量 iso8859 的值,如图:跟第一张乱码图中的乱码完全一样。猜测是tomcat或spring mvc处理上传请求时,使用了默认的 ISO-8859-1 来解码请求参数,导致我们获取的文件名为乱码。假设容器或mvc框架在处理请求中的字符串参数时使用该参数原本的编码对其进行编码,再使用ISO-8859-1来解码以获取字符串值,那么发现乱码时就可以通过逆向运算得到原本的字符串值,即先使用ISO-8859-1对乱码字符串进行编码,再使用该字符串原本的字符编码进行解码。上述代码还演示了误用其他字符编码(例如GBK)进行解码,得到乱码后,再通过逆运算还原回来。完整输出结果:
"美女" toCharArray:[美, 女] "美女"的十六进制unicode码:[7f8e, 5973] OS Default Charset:UTF-8 使用不同的字符编码方案对其进行编码: --------------------------------------------------------- Default: e7 be 8e e5 a5 b3 UTF-8: e7 be 8e e5 a5 b3 ISO-8859-1:3f 3f GBK: c3 c0 c5 ae 重现web页面文件上传时中文名乱码及还原过程: --------------------------------------------------------- 场景一、第一次获取字符串时误用ISO-8859-1进行解码: bytes got by encoding with ISO-8859-1:e7 be 8e e5 a5 b3 1.先使用系统默认字符编码(UTF-8)对其进行编码,再使用ISO-8859-1对编码得到的字节数组进行解码:ç¾å¥³ 2.先使用ISO-8859-1对第一步得到的乱码字符串进行编码,再使用UTF-8对编码得到的字节数组进行解码:美女 场景二、第一次获取字符串时误用GBK进行解码: bytes got by encoding with GBK:e7 be 8e e5 a5 b3 1.先使用UTF-8对其进行编码,再使用GBK对编码得到的字节数组进行解码:缇庡コ 2.先使用GBK对第一步得到的乱码字符串进行编码,再使用UTF-8对编码得到的字节数组进行解码:美女 各种乱码情况演示: --------------------------------------------------------- GBK 编码:cc d4 a3 a1 ce d2 cf b2 bb b6 a3 a1 ISO-8859-1解码:ÌÔ£¡ÎÒϲ»¶£¡ ISO-8859-1编码:3f 3f 3f 3f 3f 3f ISO-8859-1解码:?????? GBK 编码:cc d4 a3 a1 ce d2 cf b2 bb b6 a3 a1 ISO-8859-1解码:ÌÔ£¡ÎÒϲ»¶£¡ GBK 编码:3f 3f 3f 3f 3f 3f 3f 3f 3f 3f 3f 3f GBK 解码:????????????
特别说明:由于我将windows的默认字符编码修改为UTF-8了,所以调用getBytes()进行编码时使用的就是UTF-8。
本文参考了一篇很赞的博文:深入分析Java中的中文编码问题,但是该文中对误用ISO-8859-1进行解码,乱码后通过再次编码、解码还原回来的解释无法让我信服:
这种情况是这样的,ISO-8859-1 字符集的编码范围是 0000-00FF,正好和一个字节的编码范围相对应。这种特性保证了使用 ISO-8859-1 进行编码和解码可以保持编码数值“不变”。虽然中文字符在经过网络传输时,被错误地“拆”成了两个欧洲字符,但由于输出时也是用 ISO-8859-1,结果被“拆”开的中文字的两半又被合并在一起,从而又刚好组成了一个正确的汉字。虽然最终能取得正确的汉字,但是还是不建议用这种不正常的方式取得参数值,因为这中间增加了一次额外的编码与解码,这种情况出现乱码时因为 Tomcat
的配置文件中 useBodyEncodingForURI 配置项没有设置为”true”,从而造成第一次解析式用 ISO-8859-1 来解析才造成乱码的。
上面的演示代码中我们误用GBK进行解码也能还原回来。所以我觉得能还原回来的原因很简单,就是逆向处理,就想数学中的逆运算一样,而非作者解释的那样。
到目前为止说深入有点汗颜呐,还有好多很基础的东西没搞清楚,先抛出来有空再深究吧。
http请求中的header、字符串参数及其他文本内容在发送给服务端时,是否需要先根据页面指定的字符编码转换为字节数组,才能在网络上传输?整个请求都需要转换为字节数组才能在网络上传输吗?
web容器为什么不知道正确的字符编码?
web容器或servlet如何解析并获取到参数值以及http header中各字段的内容(对上传来说就是Content-Disposition中的filename)?如果真如前面猜测的那样,容器在处理字符串参数或http header时,如何决定使用哪种字符编码进行编码、解码操作?
参考资源
深入分析Java中的中文编码问题unicode汉字编码查询、unicode汉字编码查询2

相关文章推荐
- python 中文乱码 问题深入分析
- python 中文乱码 问题深入分析
- [转]Python中文乱码问题深入分析
- python 中文乱码 问题深入分析
- Codeblocks中文乱码原因分析和解决 编译器设置
- Java基础——孙鑫谈Java中文乱码问题产生原因分析(一)
- python 中文乱码问题深入分析
- python 中文乱码问题深入分析
- python 中文乱码 问题深入分析
- python 中文乱码问题深入分析
- python中文乱码问题深入分析
- python 中文乱码 问题深入分析
- Code:Blocks 中文乱码问题原因分析和解决方法
- 深入分析java中文乱码问题
- python 中文乱码问题深入分析
- ajax中文乱码原因分析及解决方案
- Code:Blocks 中文乱码问题原因分析和解决方法!
- Code:Blocks 中文乱码问题原因分析和解决方法!
- python 中文乱码问题深入分析