java-jsoup自适应爬取网页表格的内容
2014-01-24 15:32
375 查看
在爬取数据的过程中,我们有时候需要爬取页面中的表格 但表格的样式千变万化 下面的类和方法可以解析大部分的表格 得到 属性名 和 对应值.
需要的包链接:
http://download.csdn.net/detail/q383965374/5960953
类如下:
TestCrawTable -----测试类
DataTableUtil --------验证是否是我们需要的table
TableUtil -----解析表格
下面是一些工具类和元素类
PropertyInfo
SimFeatureUtil 相似度对比
StringUtil 去除多余字符
TableElement
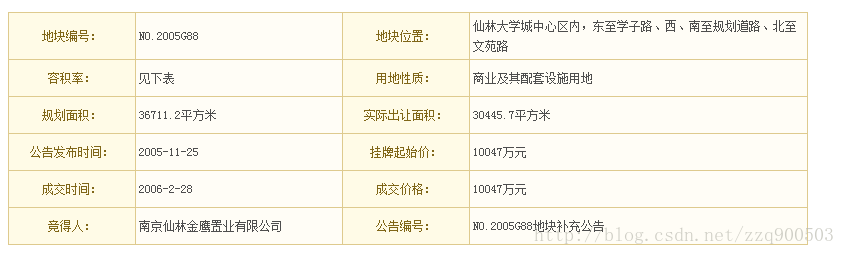
提取的表格:
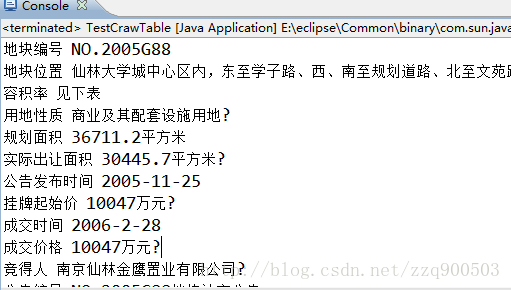
运行结果:
完整的例子下载:
java爬取网页表格的例子(运行环境myeclipse)
需要的包链接:
http://download.csdn.net/detail/q383965374/5960953
类如下:
TestCrawTable -----测试类
package com;
import java.io.IOException;
import java.util.List;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class TestCrawTable {
public static void main(String[] args) {
try {
Document document = Jsoup.connect(
"http://www.landnj.cn/LandInfo.aspx?flag=gongshi&Id=172")
.get();
if (document != null) {
List<TableElement> tableElemts = DataTableUtil
.getFitElement(document);
if (tableElemts != null && tableElemts.size() > 0) {
List<PropertyInfo> propertyInfos = TableUtil
.extractPropertyInfos(tableElemts);
if (propertyInfos != null && propertyInfos.size() > 0) {
for (PropertyInfo propertyInfo : propertyInfos) {
System.out.println(propertyInfo.getName() + " "
+ propertyInfo.getValue());
}
System.out.println("-----------------------------------");
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}DataTableUtil --------验证是否是我们需要的table
package com;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.parser.Tag;
import org.jsoup.select.Elements;
public class DataTableUtil {
private final static int NUM = 5;
//要抓取的表格可能出现的属性名
static String[] Propertys={"地块编号","宗地编号","地块位置","用地性质","规划面积","出让面积","发布时间","挂牌起始价","位置","交易时间","面积","规划用途","容积率","起价","成交价","交易方式","竞得人"};
/**
* 找到适合的装数据的TABle
*
* @param location
* @param document
* @return
*/
//取最里面的table进入isValueElement方法检测是不是我们需要的table
public static List<TableElement> getFitElement(Document document) {
if (Propertys != null) {
Element element = document.getElementsByTag("body").get(0);
List<TableElement> fitElments = new ArrayList<TableElement>();
Elements tableElements = element.getElementsByTag("table");
if (tableElements != null && tableElements.size() > 0) {
for (int i = 0; i < tableElements.size(); i++) {
Element tableElement = tableElements.get(i);
Elements ces = tableElement.getElementsByTag("table");
if (ces != null && ces.size() > 1) {
} else {
TableElement te;
if ((te = isValueElement(Propertys,tableElement)) != null) {
fitElments.add(te);
}
}
}
} else {
return null;
}
return fitElments;
}
return null;
}
//找出属性名所在的行,把属性名所在的行之上的信息去掉
//ri为属性名所在行的结尾索引
//row为属性名所在行占的行数
//ri-row为属性名所在行的开始索引,这里取属性名所在行到表格的结尾行
private static Element removeRedundance(String[] Propertys,
Element element) {
Elements tres = element.getElementsByTag("tr");
Element trElement = tres.get(0);
Elements tde = trElement.getElementsByTag("td");
int row = 1;
for (Element tdElement : tde) {
String attribute = tdElement.attr("rowspan");
if (attribute != null && !attribute.equals("")) {
int rowSpan = Integer.valueOf(attribute);
if (rowSpan > row) {
row = rowSpan;
}
}
}
List<Element> elements = new ArrayList<Element>();
for (int i = 0; i < row; i++) {
elements.add(tres.get(i));
}
int ri = 0;
while (!isValueElements(Propertys, elements)) {
elements = new ArrayList<Element>();
row = 1;
Elements tdes = tres.get(ri).getElementsByTag("td");
for (Element tdElement : tdes) {
String attribute = tdElement.attr("rowspan");
if (attribute != null && !attribute.equals("")) {
int rowSpan = Integer.valueOf(attribute);
if (rowSpan > row) {
row = rowSpan;
}
}
}
for (int i = 0; i < row; i++) {
elements.add(tres.get(ri + i));
}
ri = ri + row;
}
if (ri > 0) {
Elements trs = element.getElementsByTag("tr");
int size = trs.size();
Element newElement = new Element(Tag.valueOf("table"), "table");
for (int i = ri-row; i < size; i++) {
newElement.appendChild(trs.get(i));
}
return newElement;
}
return element;
}
private static boolean isValueElements(
String[] Propertys, List<Element> trElements) {
int index = 0;
int size = trElements.size();
for (int i = 0; i < size; i++) {
List<Element> propertyElements = new ArrayList<Element>();
Element element = trElements.get(i);
Elements tdElements = element.getElementsByTag("td");
Elements thElements = element.getElementsByTag("th");
if(thElements!=null&&thElements.size()>0){
for(Element thelement : thElements){
propertyElements.add(thelement);
}
}
if(tdElements!=null&&tdElements.size()>0){
for(Element tdelement : tdElements){
propertyElements.add(tdelement);
}
}
for (Element tdElement : propertyElements) {
String text = tdElement.text();
if (!text.trim().equals("")) {
String value = adjuestmentParm(text);
if (value != null) {
value = StringUtil.parseString(value);
double max = 0.0d;
for (int j = 0; j < Propertys.length; j++) {
double temp = SimFeatureUtil.sim(Propertys[j], value);
if (temp > max) {
max = temp;
}
}
if (max >= 0.6) {
index++;
}
}
}
}
}
if (index >= NUM) {
return true;
} else {
return false;
}
}
private static boolean regual(String reg, String string) {
Pattern pattern = Pattern.compile(reg);
Matcher ma = pattern.matcher(string);
if (ma.find()) {
return true;
}
return false;
}
//清除获取的信息标题上的单位及一些字符提高匹配的相似度
public static String adjuestmentParm(String parm) {
if (regual("\\(", parm)) {
parm = parm.substring(0, parm.indexOf("("));
} else if (regual("(", parm)) {
parm = parm.substring(0, parm.indexOf("("));
} else if (regual("万元", parm)) {
parm = parm.substring(0, parm.indexOf("万元"));
} else if (regual("亩", parm)) {
parm = parm.substring(0, parm.indexOf("亩"));
} else if (regual("公顷", parm)) {
parm = parm.substring(0, parm.indexOf("公顷"));
} else if (regual("米", parm)) {
parm = parm.substring(0, parm.indexOf("米"));
}
return parm;
}
//取出表格中的td或者th单元格的值进行相似度比较
//index记录相似值大于0.6的值个数
//consist记录连续不相似个数
//当连续不相似的个数达到10个时 就break 跳出循环
//consistFlag记录连续相似个数
//当index个数大于等于我们设定的个数时说明该table是包含我们要获取数据的table
//当consistFlag大于2时说明表格内容是竖向的 setCross为false
//进入removeRedundance方法检查是否table中的前几行(tr)不是以标题行开始,把这几行去掉
//例如:http://kmland.km.gov.cn/view.asp?id=7089&frist_lanmu=173
private static TableElement isValueElement(
String[] Propertys, Element element) {
TableElement tableElement = new TableElement();
List<Element> propertyElements = new ArrayList<Element>();
Elements tdElements = element.getElementsByTag("td");
Elements thElements = element.getElementsByTag("th");
if(thElements!=null&&thElements.size()>0){
for(Element thelement : thElements){
propertyElements.add(thelement);
}
}
if(tdElements!=null&&tdElements.size()>0){
for(Element tdelement : tdElements){
propertyElements.add(tdelement);
}
}
int index = 0;
int consist = 0;
int size = propertyElements.size();
int consistFlag = 0;
for (int i = 0; i < size; i++) {
consist++;
Element tdElement = propertyElements.get(i);
String text = tdElement.text();
if (!text.trim().equals("")) {
String value = adjuestmentParm(text);
if (value != null) {
value = StringUtil.parseString(value);
double max = 0.0d;
for (int j = 0; j < Propertys.length; j++) {
double temp = SimFeatureUtil.sim(
Propertys[j], value);
if (temp > max) {
max = temp;
}
}
if (max >= 0.6) {
index++;
if (consist == 1) {
consist = 0;
consistFlag++;
} else {
consist = 0;
}
} else {
if (consist >= 10) {
break;
}
}
}
}
}
if (index >= NUM) {
tableElement.setWordNum(index);
if (consistFlag >= 2) {
tableElement.setElement(removeRedundance(Propertys, element));
tableElement.setCross(false);
} else {
tableElement.setElement(element);
}
return tableElement;
} else {
return null;
}
}
}TableUtil -----解析表格
package com;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class TableUtil {
//横向的表格进入getAcrossTableValue方法解析 竖向的表格进入getTableValue方法解析
public static List<PropertyInfo> extractPropertyInfos(List<TableElement> tableElemts) {
List<PropertyInfo> propertyInfos = new ArrayList<PropertyInfo>();
if(tableElemts!=null&&tableElemts.size()>0){
for (TableElement element : tableElemts) {
if(element.isCross()){
propertyInfos.addAll(TableUtil.getAcrossTableValue(element.getElement()));
}else{
propertyInfos.addAll(TableUtil.getTableValue(element.getElement()));
}
}
return propertyInfos;
}
return null;
}
//对于竖向内容的表格先取出属性名占的最大行数存为row
public static List<PropertyInfo> getTableValue(Element tableElement) {
Elements trElements = tableElement.getElementsByTag("tr");
int row = getRowElement(trElements.get(0));
List<String> propertys = parseTablePropertys(row,trElements);
return parsePropertyValue(row, propertys, trElements);
}
/**
* 提取TABLE属性
*
* @param tableElement
*/
//把每行的元素存入ptdELementsList列表中,把每行的列数存入length 然后进入parsePropertyString函数对第一行内容提取得到属性名
private static List<String> parseTablePropertys(int row,Elements trElements) {
List<String> propertys = new ArrayList<String>();
List<Elements> ptdELementsList = new ArrayList<Elements>();
int[] lengths = new int[row]; // 储存每行的长度(列数-单元格个数)
int[] index = new int[row]; // 每行位置
for (int i = 0; i < row; i++) {
Element trElement = trElements.get(i);
Elements elements = new Elements();
Elements tdElements = trElement.getElementsByTag("td");
Elements thElements = trElement.getElementsByTag("th");
if(tdElements!=null&&tdElements.size()>0){
elements.addAll(tdElements);
}
if(thElements!=null&&thElements.size()>0){
elements.addAll(thElements);
}
ptdELementsList.add(elements);
lengths[i] = elements.size();
}
parsePropertyString(propertys, index, lengths, 0, ptdELementsList);
return propertys;
}
//提取内容的值---遍历除属性行之外的行 依次提取td元素进入parseValues提取内容的值
//flags记录行的状态
//valueFlags记录每个属性一个值对多个单元格的状态
//vtdElements记录每行单元格的元素td
//size值的总行数
//length记录每行的单元格td数
private static List<PropertyInfo> parsePropertyValue(int row, List<String> propertys,
Elements trElements) {
int propertysSize = propertys.size();
List<Elements> vtdElements = new ArrayList<Elements>();
int trsize = trElements.size();
int size = trsize - row;
int[] lengths = new int[size];
boolean[] flags = new boolean[size];
boolean[][] valueFlags = new boolean[size][propertysSize];
for (int i = row; i < trsize; i++) {
Element trElement = trElements.get(i);
Elements velements = new Elements();
Elements tdElements = trElement.getElementsByTag("td");
Elements thElements = trElement.getElementsByTag("th");
if(thElements!=null&&thElements.size()>0){
velements.addAll(thElements);
}
if(tdElements!=null&&tdElements.size()>0){
velements.addAll(tdElements);
}
// Elements tdElements = trElement.getElementsByTag("td");
if (velements != null && velements.size() > 0) {
lengths[i-row] = velements.size();
vtdElements.add(velements);
for(int j = 0 ; j < propertysSize;j++){
valueFlags[i-row][j]= false;
}
flags[i-row] = true;
} else {
size--;
}
}
return parseValues(propertys, vtdElements, size, lengths, flags,valueFlags);
}
/**
* 取TABLE里面的数据 包含 ROWSPAN 表明该元素对应多个PROPERTY 包含COLSPAN表明该元素对应多条数据
*
* @param propertysSize
* @param vtdElements
* @param size
* @param lengths
* @param flags
* @param valueFlags
*/
//一个单元格的内容对应多条记录的 例子:http://kmland.km.gov.cn/view.asp?id=7089&frist_lanmu=173
//遇到一对多的值 则取出它的rowspan和colspan的,把对应位置的值赋值,并修改该位置的valueFlag为true
private static List<PropertyInfo> parseValues(List<String> propertys,
List<Elements> vtdElements, int size, int[] lengths,
boolean[] flags, boolean[][] valueFlags) {
int propertysSize = propertys.size();
String[][] pValueStrs = new String[size][propertysSize];
for (int i = 0; i < size; i++) {
Elements tdValueElements = vtdElements.get(i);
int k = 0;
for (int j = 0; j < lengths[i]; j++) {
Element tdValueElement = null;
try {
tdValueElement = tdValueElements.get(j);
} catch (Exception e) {
flags[i] = false;
break;
}
if(valueFlags[i][k]){
while (valueFlags[i][k]) {
k++;
}
}
if (tdValueElement.hasAttr("rowspan")) {
int rowspan = Integer.valueOf(tdValueElement.attr("rowspan"));
int colspan = 1;
if (tdValueElement.hasAttr("colspan")) {
colspan = Integer.valueOf(tdValueElement.attr("colspan"));
}
if (rowspan > 1) {
System.out.println(rowspan);
for (int m = 0; m < rowspan; m++) {
for (int n = 0; n < colspan; n++) {
System.out.println("i = " + i +"m=" +m);
try {
valueFlags[i + m][k + n] = true;
pValueStrs[i + m][k + n] = tdValueElement.text();
} catch (Exception e) {
System.out.println("i = " + i +"m=" +m +"k+n = "+ (k+n)+ "length");
}
}
}
}
}else if (tdValueElement.hasAttr("colspan")) {
int colspan = Integer.valueOf(tdValueElement
.attr("colspan"));
if (colspan > 1) {
if (colspan >= size - 1) {
flags[i] = false;
break;
}
for (int m = 0; m < colspan; m++) {
valueFlags[i][k] = true;
pValueStrs[i+m][k] = tdValueElement.text();
}
}
}else{
if(tdValueElement!=null){
pValueStrs[i][k] = tdValueElement.text();
}
}
k++;
}
}
List<PropertyInfo> propertyInfos = new ArrayList<PropertyInfo>();
for (int i = 0; i < size; i++) {
if (flags[i]) {
for (int j = 0; j < propertysSize; j++) {
if(propertys.get(j)!=null){
PropertyInfo propertyValue = new PropertyInfo();
propertyValue.setName(propertys.get(j));
propertyValue.setValue(pValueStrs[i][j]);
propertyInfos.add(propertyValue);
}
}
}
}
return propertyInfos;
}
public static List<PropertyInfo> getAcrossTableValue(Element element)
{
// Elements tdElements = element.getElementsByTag("td");
Elements trElements = element.getElementsByTag("tr");
List<PropertyInfo> propertyValues = new ArrayList<PropertyInfo>();
for(Element trElement:trElements){
Elements tdElements = trElement.getElementsByTag("td");
int size = tdElements.size();
if(size % 2 ==0){
PropertyInfo propertyValue = null;
for (int i = 0; i < size; i++) {
Element tdElement = tdElements.get(i);
String value = tdElement.text();
if (i % 2 == 0) {
propertyValue = new PropertyInfo();
propertyValue.setName(StringUtil.parseString(value));
} else {
propertyValue.setValue(value);
propertyValues.add(propertyValue);
}
}
}
}
return propertyValues;
}
/**
* 提取属性名
*
* @param propertyStrs
* @param index
* @param lengths
* @param ind
* @param tdElementsList
*/
//遍历属性行中的td,取它的colspan,如果它横跨的大于1则说明它是包含多个小标题的大标题,则进入第二行取值
private static void parsePropertyString(List<String> propertyStrs,
int[] index, int[] lengths, int ind, List<Elements> tdElementsList) {
Elements tdElements = tdElementsList.get(ind);
for (int i = index[ind]; i < lengths[ind]; i++) {
index[ind] = index[ind] + 1;
Element tdElement = tdElements.get(i);
String attribute = tdElement.attr("colspan");
String value = StringUtil.parseString(tdElement.text());
// if (!value.trim().equals("")) {
if (attribute != null && !attribute.equals("")) {
int col = Integer.valueOf(attribute);
if (col > 1) {
parsePropertyString(propertyStrs, index, lengths,
ind + 1, tdElementsList);
} else {
propertyStrs.add(value);
}
} else {
propertyStrs.add(value);
}
// }
}
}
/**
* 提取属性占的ROW数 取出属性中含有的最大ROWSPAN数
*
* @param trElement
* @return
*/
private static int getRowElement(Element trElement) {
Elements tdElements = trElement.getElementsByTag("td");
int row = 1;
for (Element tdElement : tdElements) {
String attribute = tdElement.attr("rowspan");
if (attribute != null && !attribute.equals("")) {
int rowSpan = Integer.valueOf(attribute);
if (rowSpan > row) {
row = rowSpan;
}
}
}
return row;
}
}下面是一些工具类和元素类
PropertyInfo
package com;
public class PropertyInfo {
private String name;
private String value;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getValue() {
return value;
}
public void setValue(String value) {
this.value = value;
}
}SimFeatureUtil 相似度对比
package com;
public class SimFeatureUtil {
private static int min(int one, int two, int three) {
int min = one;
if (two < min) {
min = two;
}
if (three < min) {
min = three;
}
return min;
}
public static int ld(String str1, String str2) {
int d[][]; // 矩阵
int n = str1.length();
int m = str2.length();
int i; // 遍历str1的
int j; // 遍历str2的
char ch1; // str1的
char ch2; // str2的
int temp; // 记录相同字符,在某个矩阵位置值的增量,不是0就是1
if (n == 0) {
return m;
}
if (m == 0) {
return n;
}
d = new int[n + 1][m + 1];
for (i = 0; i <= n; i++) { // 初始化第一列
d[i][0] = i;
}
for (j = 0; j <= m; j++) { // 初始化第一行
d[0][j] = j;
}
for (i = 1; i <= n; i++) { // 遍历str1
ch1 = str1.charAt(i - 1);
// 去匹配str2
for (j = 1; j <= m; j++) {
ch2 = str2.charAt(j - 1);
if (ch1 == ch2) {
temp = 0;
} else {
temp = 1;
}
// 左边+1,上边+1, 左上角+temp取最小
d[i][j] = min(d[i - 1][j] + 1, d[i][j - 1] + 1, d[i - 1][j - 1]+ temp);
}
}
return d
[m];
}
public static double sim(String str1, String str2) {
try {
double ld = (double)ld(str1, str2);
return (1-ld/(double)Math.max(str1.length(), str2.length()));
// double length = (double)str1.length() /(double) str2.length();
// return (1 - (double) ld / Math.max(str1.length(), str2.length()))* length;
} catch (Exception e) {
return 0.1;
}
}
public static void main(String[] args) {
String str1 = "地块编号";
String str2 = "地块编号";
System.out.println("ld=" + ld(str1, str2));
System.out.println("sim=" + sim(str1, str2));
}
}StringUtil 去除多余字符
package com;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class StringUtil {
private static Pattern pattern = Pattern.compile("[\\u4e00-\\u9fa5a-zA-Z\\d\\../:]");
/**
* 去掉多余字符
*
* @return
*/
public static String parseString(String str) {
StringBuilder sb = new StringBuilder();
Matcher matcher = pattern.matcher(str);
while (matcher.find()) {
sb.append(matcher.group());
}
return sb.toString();
}
}TableElement
package com;
import org.jsoup.nodes.Element;
public class TableElement {
private Element element;
private boolean isCross;
private int wordNum;
public TableElement(){
isCross = true;
}
public Element getElement() {
return element;
}
public void setElement(Element element) {
this.element = element;
}
public boolean isCross() {
return isCross;
}
public void setCross(boolean isCross) {
this.isCross = isCross;
}
public int getWordNum() {
return wordNum;
}
public void setWordNum(int wordNum) {
this.wordNum = wordNum;
}
}提取的表格:
运行结果:
完整的例子下载:
java爬取网页表格的例子(运行环境myeclipse)

相关文章推荐
- java-jsoup自适应爬取网页表格的内容
- 【Java Utility】Jsoup网页爬虫工具--设置Element的HTML内容【十二】
- 如何让网页适应所有的屏幕宽度+表格根据内容自适应
- 【Java Utility】Jsoup网页爬虫工具--从元素/元素集中提取属性、文本和HTML内容【九】
- JSoup——用Java解析html网页内容
- java学习--网络爬虫(使用jsoup爬取网页内容)
- java使用jsoup爬取网页内容
- java爬取网页内容 简单例子(2)——附jsoup的select用法详解
- java爬取网页内容 简单例子(2)——附jsoup的select用法详解
- java爬取网页内容 简单例子(2)——附jsoup的select用法详解
- java爬虫(使用jsoup设置代理,抓取网页内容)
- java爬取网页内容 简单例子(2)——附jsoup的select用法详解
- java爬取网页内容 简单例子(2)——附jsoup的select用法详解
- JAVA使用爬虫抓取网站网页内容的方法
- 浅析JAVA实现网页取内容
- Jsoup采集百度新闻内容,网页显示并实时更新
- Java使用Jsoup解析网页
- java根据 正则表达式解析html网页内容
- 转!!Java JTable 根据表格内容 自动调整表格列宽
- 使用Java把文本内容转换成网页的实现方法分享