Cassandra – 理解关键概念和数据模型
2013-12-09 00:00
253 查看
摘要: Cassandra的设计理论倾向于实现CAP原则中的AP(Availability and Partition Tolerance)——高可用性和分布式,它的分布式是基于一致性哈希环(Consistent Hash Ring)算法实现的。
Cassandra的设计理论倾向于实现CAP原则中的AP(Availability and Partition Tolerance)——高可用性和分布式,它的分布式是基于一致性哈希环(Consistent Hash Ring)算法实现的。
面向行(Row-Oriented)
我们常常说Cassandra是一个面向列(Column-Oriented)的数据库,其实这不完全对——数据是以松散结构的多维哈希表存储在数据库中;所谓松散结构,是指每行数据可以有不同的列结构,而在关系型数据中,同一张表的所有行必须有相同的列。在Cassandra中可以使用一个唯一识别号访问行,所以我们可以更好理解为,Cassandra是一个带索引的,面向行的存储。
无结构(Schema Free)
Cassandra只需要你定义一个逻辑上的容器(Keyspaces)装载列族(Column Families),之后,你可以自由地向列族中添加数据。每一个列族都被设计为一组数据关联或排列。这种结构意味着,根据你的需求场景,你可以只保存你需要的数据,而不必拘泥于早前定义的表结构。
适用场景(Use Cases for Cassandra)
快速开发应用程序:Schema Free的特点,让Cassandra可以快速适应你的初期变更;如果你使用关系型数据库,那么就不得不从数据表、DAO层、Logic/Service层到UI层进行层层变更,哪怕只是一个小小的列名或字段类型变化;
大量写入、统计和分析:Cassandra的列族设计是囊括数据关联和排序的,并且可以不存储不需要的数据,这极大减省了表联接和冗余字段带来的性能开销,后者恰恰是高并发写入操作、统计分析时关系型数据库的瓶颈;
需要扩展的部署结构:Cassandra是面向分布式的设计,这让它可以灵活地水平扩展,以在运维阶段满足你的需求,而不必考虑“将数据迁往更高性能的服务器”这样的问题。
数据模型(Data Model)
我们从最基本的概念来理解Cassandra的数据模型,先假设使用一个最简单的值结构来存放一堆数据(Values)。

但问题是,除非我们记录了每个值的存放地址,我们将无法访问到这些数据,这看起来很像一个数组或集合,我们必须记住某个值的索引号,并且还要预先定义好这个数组的宽度,否则它会无法容纳足够多的数据。
解决办法是为每个数据添加一个唯一名称(Name),只要我们记住了这个名称,就能找到这个数据了,这样,我们就有了一堆名称——值对(Name/Value Pair)。
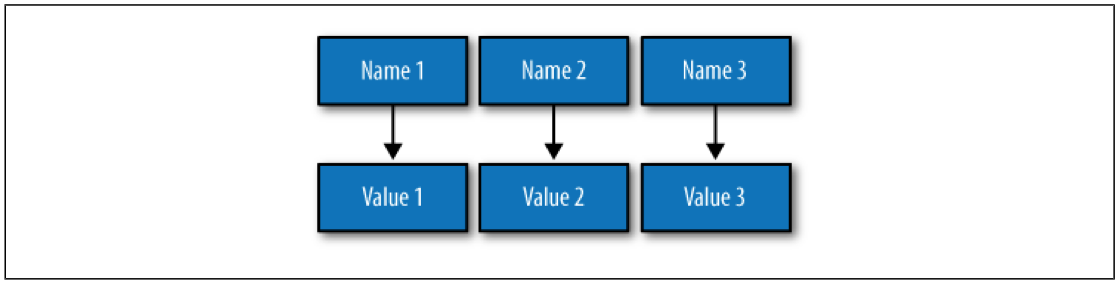
这个结构很像哈希表,可以满足一些信息的存储,例如用户的基本信息,姓、名
3ff0
、电话、手机、公司、地址等,并且我们可以根据需要来决定存储哪些名称和值,如此,我们就得到了一个单独的行(Single Row),并引出了Cassandra数据库中重要的行列概念定义:
一组包含名称值对的数据叫做行(Row),而每一组名称值对(Name/Value Pair)被称之为列(Column)。
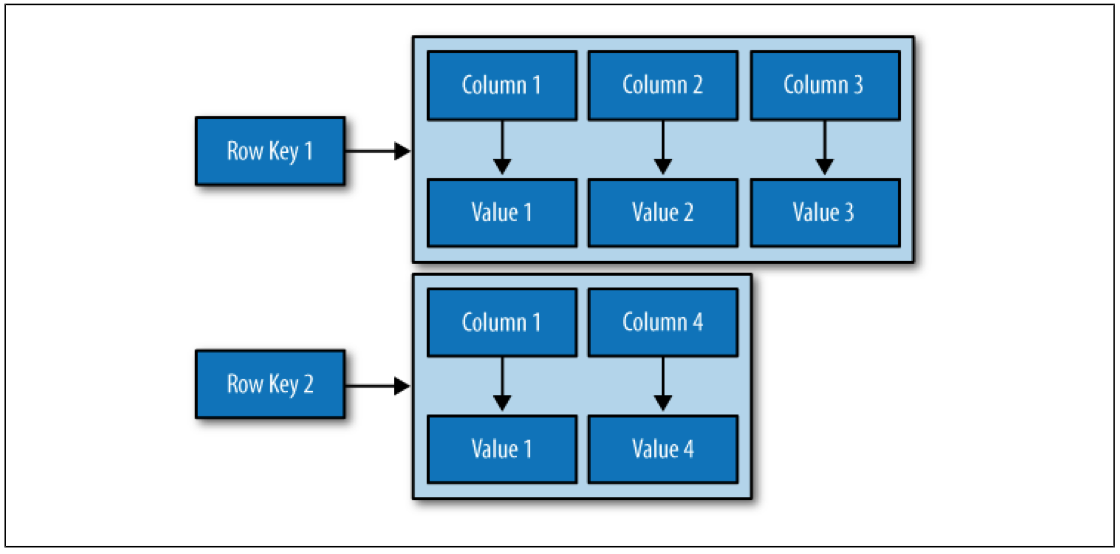
在关系型数据库中,列的名称必须是字符串,但在Cassandra中列名称可以为任意类型,这意味着,你可以将列名称也作为一个数据来存储。换一种说法,你不必被数据类型约束,往Cassandra中添加数据就够了。
下面的示例可以让我们更好地理解Cassandra的数据存储:
另外,Cassandra还有一种可在列之间建立关联的超级列(Super Column),你可以往超级列中添加子列。

键空间(Keyspaces)
键空间是Cassandra的数据容器,可以理解为关系型数据库中的数据库(Database)。对于一个Keyspace来说,有以下几个属性:
数据复制节点数目(Replication factor ):定义Keyspace中每行数据的复制节点数目,如果定义为三,在哈希环上,每行数据将会有三个拷贝节点,并且都能够被客户端请求到。
复制替换策略(Replica placement strategy):定义在一致性哈希环中某个节点的替换策略。
列族(Column Families):类似于关系型数据库中的表(Table),是列的容器。
列族(Column Families)
上面已经讲到,列族是列的容器,它的结构像是一个四维哈希表:
如果用JSON表示,一组存放在列族中的数据看起来是这样的:
使用Cassandra创建键空间Hotelier,列族为Hotel,并查询行键(Row Key)为“NYN_042”的结果显示:
列(Column)
如果你对“列”的理解来自于关系型数据库,那么很容易产生和我之前一样的误解,以为Cassandra是把关系型数据库的行列进行了某种倒置而得到的设计。其实不是这样的,Cassandra的列是一组键值对,它的结构如下图所示(事实上,这个数据结构是Cassandra 0.7.0,最新的2.0.3版本中ByteBuffer替代了byte[],long型的日期时间替代了IClock):

使用JSON描述的列结构:
超级列(Super Column)的结构:

复合键(Composite Keys)
有时我们会遇到不同省份可能有同样的城市名称,或不同的城市有重名的街道,这时使用单一的城市名称或街道名称来作为Key就会无法识别。Cassandra允许你使用Key1:Key2的结构来存储一对值作为Key,一个常见的例子是使用<userid:lastupdate>这样的结构来存储用户ID及最后登录时间。下面是一个例子:
最后让我们来巩固一下Cassandra和关系型数据库的区别吧:
没有查询语言:No SQL (Structured Query Language);
没有外键约束:关系型数据库的最重要特征;
双重簇索引:在关系型数据库中,每个表只能指定一个簇索引,其它的索引查询都会导致全表扫描,但在Cassandra中,我们可以有第二级的簇索引;
排序是在设计时决策:Cassandra不支持Order By,排序是需要设计时考虑,而不是像在关系型数据库查询时刻使用Order By;
无数据结构约定:这是Cassandra最大的优势,在关系型数据库中,我们设计数据库结构时总是慎之又慎,但在Cassandra中不需要预先约定数据结构。
本文参考自《Cassandra: The Definitive Guide》
原文链接:Cassandra – 理解关键概念和数据模型
Cassandra的设计理论倾向于实现CAP原则中的AP(Availability and Partition Tolerance)——高可用性和分布式,它的分布式是基于一致性哈希环(Consistent Hash Ring)算法实现的。
面向行(Row-Oriented)
我们常常说Cassandra是一个面向列(Column-Oriented)的数据库,其实这不完全对——数据是以松散结构的多维哈希表存储在数据库中;所谓松散结构,是指每行数据可以有不同的列结构,而在关系型数据中,同一张表的所有行必须有相同的列。在Cassandra中可以使用一个唯一识别号访问行,所以我们可以更好理解为,Cassandra是一个带索引的,面向行的存储。
无结构(Schema Free)
Cassandra只需要你定义一个逻辑上的容器(Keyspaces)装载列族(Column Families),之后,你可以自由地向列族中添加数据。每一个列族都被设计为一组数据关联或排列。这种结构意味着,根据你的需求场景,你可以只保存你需要的数据,而不必拘泥于早前定义的表结构。
适用场景(Use Cases for Cassandra)
快速开发应用程序:Schema Free的特点,让Cassandra可以快速适应你的初期变更;如果你使用关系型数据库,那么就不得不从数据表、DAO层、Logic/Service层到UI层进行层层变更,哪怕只是一个小小的列名或字段类型变化;
大量写入、统计和分析:Cassandra的列族设计是囊括数据关联和排序的,并且可以不存储不需要的数据,这极大减省了表联接和冗余字段带来的性能开销,后者恰恰是高并发写入操作、统计分析时关系型数据库的瓶颈;
需要扩展的部署结构:Cassandra是面向分布式的设计,这让它可以灵活地水平扩展,以在运维阶段满足你的需求,而不必考虑“将数据迁往更高性能的服务器”这样的问题。
数据模型(Data Model)
我们从最基本的概念来理解Cassandra的数据模型,先假设使用一个最简单的值结构来存放一堆数据(Values)。

但问题是,除非我们记录了每个值的存放地址,我们将无法访问到这些数据,这看起来很像一个数组或集合,我们必须记住某个值的索引号,并且还要预先定义好这个数组的宽度,否则它会无法容纳足够多的数据。
解决办法是为每个数据添加一个唯一名称(Name),只要我们记住了这个名称,就能找到这个数据了,这样,我们就有了一堆名称——值对(Name/Value Pair)。

这个结构很像哈希表,可以满足一些信息的存储,例如用户的基本信息,姓、名
3ff0
、电话、手机、公司、地址等,并且我们可以根据需要来决定存储哪些名称和值,如此,我们就得到了一个单独的行(Single Row),并引出了Cassandra数据库中重要的行列概念定义:
一组包含名称值对的数据叫做行(Row),而每一组名称值对(Name/Value Pair)被称之为列(Column)。

在关系型数据库中,列的名称必须是字符串,但在Cassandra中列名称可以为任意类型,这意味着,你可以将列名称也作为一个数据来存储。换一种说法,你不必被数据类型约束,往Cassandra中添加数据就够了。
下面的示例可以让我们更好地理解Cassandra的数据存储:
Musician: ColumnFamily 1 bootsy: RowKey email: bootsy@pfunk.com, ColumnName:Value instrument: bass ColumnName:Value george: RowKey email: george@pfunk.com ColumnName:Value Band: ColumnFamily 2 george: RowKey pfunk: 1968-2010 ColumnName:Value
另外,Cassandra还有一种可在列之间建立关联的超级列(Super Column),你可以往超级列中添加子列。

键空间(Keyspaces)
键空间是Cassandra的数据容器,可以理解为关系型数据库中的数据库(Database)。对于一个Keyspace来说,有以下几个属性:
数据复制节点数目(Replication factor ):定义Keyspace中每行数据的复制节点数目,如果定义为三,在哈希环上,每行数据将会有三个拷贝节点,并且都能够被客户端请求到。
复制替换策略(Replica placement strategy):定义在一致性哈希环中某个节点的替换策略。
列族(Column Families):类似于关系型数据库中的表(Table),是列的容器。
列族(Column Families)
上面已经讲到,列族是列的容器,它的结构像是一个四维哈希表:
[Keyspace][ColumnFamily][Key][Column]
如果用JSON表示,一组存放在列族中的数据看起来是这样的:
Hotel {
key: AZC_043 { name: Cambria Suites Hayden, phone: 480-444-4444,address: 400 N. Hayden Rd., city: Scottsdale, state: AZ, zip: 85255}
key: AZS_011 { name: Clarion Scottsdale Peak, phone: 480-333-3333,address: 3000 N. Scottsdale Rd, city: Scottsdale, state: AZ, zip: 85255}
key: CAS_021 { name: W Hotel, phone: 415-222-2222,address: 181 3rd Street, city: San Francisco, state: CA, zip: 94103}
key: NYN_042 { name: Waldorf Hotel, phone: 212-555-5555,address: 301 Park Ave, city: New York, state: NY, zip: 10019} }使用Cassandra创建键空间Hotelier,列族为Hotel,并查询行键(Row Key)为“NYN_042”的结果显示:
cassandra> get Hotelier.Hotel['NYN_042'] => (column=zip, value=10019, timestamp=3894166157031651) => (column=state, value=NY, timestamp=3894166157031651) => (column=phone, value=212-555-5555, timestamp=3894166157031651) => (column=name, value=The Waldorf=Astoria, timestamp=3894166157031651) => (column=city, value=New York, timestamp=3894166157031651)
列(Column)
如果你对“列”的理解来自于关系型数据库,那么很容易产生和我之前一样的误解,以为Cassandra是把关系型数据库的行列进行了某种倒置而得到的设计。其实不是这样的,Cassandra的列是一组键值对,它的结构如下图所示(事实上,这个数据结构是Cassandra 0.7.0,最新的2.0.3版本中ByteBuffer替代了byte[],long型的日期时间替代了IClock):

使用JSON描述的列结构:
{
"name": "email",
"value: "me@example.com",
"timestamp": 1274654183103300
}超级列(Super Column)的结构:

复合键(Composite Keys)
有时我们会遇到不同省份可能有同样的城市名称,或不同的城市有重名的街道,这时使用单一的城市名称或街道名称来作为Key就会无法识别。Cassandra允许你使用Key1:Key2的结构来存储一对值作为Key,一个常见的例子是使用<userid:lastupdate>这样的结构来存储用户ID及最后登录时间。下面是一个例子:
HotelByCity (CF) Key: city:state {
key: Phoenix:AZ {AZC_043: -, AZS_011: -}
key: San Francisco:CA {CAS_021: -}
key: New York:NY {NYN_042: -}
}最后让我们来巩固一下Cassandra和关系型数据库的区别吧:
没有查询语言:No SQL (Structured Query Language);
没有外键约束:关系型数据库的最重要特征;
双重簇索引:在关系型数据库中,每个表只能指定一个簇索引,其它的索引查询都会导致全表扫描,但在Cassandra中,我们可以有第二级的簇索引;
排序是在设计时决策:Cassandra不支持Order By,排序是需要设计时考虑,而不是像在关系型数据库查询时刻使用Order By;
无数据结构约定:这是Cassandra最大的优势,在关系型数据库中,我们设计数据库结构时总是慎之又慎,但在Cassandra中不需要预先约定数据结构。
本文参考自《Cassandra: The Definitive Guide》
原文链接:Cassandra – 理解关键概念和数据模型

相关文章推荐
- Cassandra的数据模型的理解
- Cassandra的数据模型的理解
- Cassandra 数据模型设计总结
- 理解Javascript_04_数据模型
- 理解数据模型
- 列数据库--Cassandra数据模型
- 理解Oracle Fusion Middleware中的关键概念
- PowerDesigner教程系列(二)概念数据模型
- 政务大数据的概念模型
- 关于winsock中网络编程事件模型和窗口消息模型中FD_WRITE的理解与数据的发送需要注意的关键点
- 从概念理解Lucene的Index(索引)文档模型
- PowerDesigner教程系列(一)概念数据模型
- Cassandra 数据模型与关系数据库模型比较
- PowerDesigner教程系列(二)概念数据模型
- Cassandra数据模型设计最佳实践(上)
- 维度模型数据仓库基础对象概念一览
- 大数据概念炒作周期模型
- 关于数据挖掘其中的一些基本概念的理解
- 辨异 —— 机器学习概念辨异、模型理解
- 数据挖掘概念与技术9--多维数据模型