使用Python的yield实现流计算模式
2013-12-01 11:19
701 查看
首先先提一下上一篇《如何猜出Y combinator》中用的方法太复杂了。其实在Lambda演算中实现递归的思想很简单,就是函数把自己作为第一个参数传入函数,然后后面就是简单的Lambda变换提取出Y combinator了。好,接下来是本篇的正文:
------------------------------------------------------------------------------------
昨天fengidri给我演示了yield的用法,让我大受启发——可以用yield来实现SICP里描述的流计算模式。
所谓的流,也就是stream,实质上是一个惰性求值的列表。Python的Generator也算是一种流吧。
下面是生成一个简单的整数序列流的函数:
这个函数生成一个流,这个流是一个从i开始的无穷整数列表(当然如果i传入一个非整数也可以,这时候输出的序列就不是整数咯)。每次调用next()操作返回一个整数:
我们知道,有两个非常常用的对序列变换的函数:map和filter。下面代码实现了针对流的stream_map和stream_filter:
stream_map对流stream里的每个元素根据函数func做变换,stream_filter将流stream中不满足函数pred描述的条件的元素过滤掉。这两个函数在后面的例子中会经常用到。接下来看看我们可以利用流来做什么。
1、2是素数,将2后面的整数中是2倍数的数删去(过滤);
2、3是素数,将3后面的整数中是3倍数的数删去;
3、4在第1步已经被删掉了。5是素数。将5后面的整数中是5倍数的数删去;
……
重复这个过程,最后留下来的就是素数序列。以流计算模式的思路来看,就是每次取出一个素数p后,就以不整除这个素数p作为过滤条件对后面的流进行过滤。下面是代码:
最开始的流是一个从2开始的整数序列。每次从流中取出一个数x(第一次取出的是2,后面取出的是后继的素数),新建一个过滤条件divisible(x),用stream_filter过滤这个序列。举个例子:
1、第一次调用,返回2,stream变成:{x | x <- [3, 4, ...], x%2 != 0}
2、第二次调用,返回3,stream变成:{x | x <- [4, 5, ...], x%2 != 0, x%3 != 0}
3、第三次调用,返回5(因为4被过滤了),stream变成:{x | x <- [6, 7, ...], x%2 != 0, x%3 != 0, x%5 != 0}
……
留下来的只剩素数。下面代码打印前100个素数:
输出:2 3 5 7 11 13 17 19 23 29 31 37 41 43 47 53 59 61 67 71 73 79 83 89 97 101 103 107 109 113 127 131 137 139 149 151 157 163 167 173 179 181 191 193 197 199 211 223 227 229 233 239 241 251 257 263 269 271 277 281 283 293 307 311 313 317 331 337 347 349 353 359 367 373 379 383 389 397 401 409 419 421 431 433 439 443 449 457 461 463 467 479 487 491 499 503 509 521 523 541
$$ {\pi \over 4} = 1 – {1 \over 2} + {1 \over 3} – {1 \over 4} + \ldots $$
首先写一个生成这个级数每一项的流:
接下来定义一个流的变换,这个变换输入一个流stream,输出stream的部分和序列。也就是说输出流的第一项是stream的第一项,第二项是stream的第一项加第二项,第三项是stream的第一项加第二项加第三项……
于是上面说的级数的部分和序列的4倍就是一个逼近\(\pi\)的序列:
输出是:4.0 2.66666666667 3.46666666667 2.89523809524 3.33968253968 2.97604617605 3.28373848374 3.01707181707 3.25236593472 3.04183961893
pi_stream的收敛速度慢得令人发指,不过有一种叫序列加速器的技巧能加快pi_stream的收敛速度。这个加速器是欧拉发现的。对收敛序列采用如下变换,将会极大地加快原序列的收敛速度:
$$ S_{n+1} – {(S_{n+1} – S_n)^2 \over S_{n-1} – 2S_n + S_{n_1}} $$
\(S_n\)就是原序列的第\(n\)项。在我们的问题里就是pi_stream的第\(n\)项。加速器变换的代码:
利用加速器帮助计算\(\pi\):
输出是:3.16666666667 3.13333333333 3.14523809524 3.13968253968 3.14271284271 3.14088134088 3.14207181707 3.14125482361 3.14183961893 3.1414067185
收敛速度明显快很多了,第十项和原来相比更接近\(\pi\)了。
可以多次对序列加速:
加速2次的输出:3.14210526316 3.14145021645 3.141643324 3.1415712902 3.1416028416 3.14158732095 3.14159565524 3.14159086271 3.14159377424 3.14159192394
加速3次的输出:3.14159935732 3.1415908604 3.14159323124 3.14159243844 3.14159274346 3.14159261243 3.14159267391 3.14159264291 3.14159265951 3.14159265016
另外,SICP还描述了一个“超级加速器”的技巧,原理大致是取对角线,越靠后的项被加速越多次。这里就不细讲了,直接贴代码和输出吧。
输出:4.0 3.16666666667 3.14210526316 3.14159935732 3.14159271403 3.14159265398 3.14159265359 3.14159265359 3.14159265359
可以看出从第7项开始就没什么变化了。SICP里有提到,这个序列的第8项就已经精确到14位数字,原序列需要计算到\(10^{13}\)的数量级的项才能到达这个精度。另外,在这里不能计算到第10项——计算第10项的时候程序就会像李卫公的开方机器一样散架——浮点数溢出。

代码的重点在partial_sums_with_init函数。这里利用lambda做出了一个延后求值的技巧,因为feedback(就是那条反馈的线)就是最终输出,而计算最终输出又需要feedback的输入(第一项不用,第一项返回初始值init)。这部分也不细讲了,代码应该写得很清楚了,用文字讲反而画蛇添足。利用这种模拟电路的方法可以用来做积分、微分的数值计算、计算微分方程的数值解等。
------------------------------------我是最后的分割线---------------------------------------------------------
最后说一下,这里用yield实现的流计算模式要特别注意“副作用”。这里的流(Generator)每次调用next(),都会改变状态,所以一个流放入一个变换后就不能再放入其他变换了。
完整代码可以在https://github.com/sKabYY/palestra/blob/master/python/stream/stream.py下载。
对了,SICP是《计算机的构造与解释》的简称,最近刚看完,蛮有意思的一本书,推荐大家看看。
------------------------------------------------------------------------------------
昨天fengidri给我演示了yield的用法,让我大受启发——可以用yield来实现SICP里描述的流计算模式。
所谓的流,也就是stream,实质上是一个惰性求值的列表。Python的Generator也算是一种流吧。
下面是生成一个简单的整数序列流的函数:
def integers_starting_from(i): while True: yield i i += 1
这个函数生成一个流,这个流是一个从i开始的无穷整数列表(当然如果i传入一个非整数也可以,这时候输出的序列就不是整数咯)。每次调用next()操作返回一个整数:
stream = integers_starting_from(3) print stream.next() # 打印3 print stream.next() # 打印4
我们知道,有两个非常常用的对序列变换的函数:map和filter。下面代码实现了针对流的stream_map和stream_filter:
def stream_map(func, stream): while True: yield func(stream.next()) def stream_filter(pred, stream): while True: x = stream.next() if pred(x): yield x
stream_map对流stream里的每个元素根据函数func做变换,stream_filter将流stream中不满足函数pred描述的条件的元素过滤掉。这两个函数在后面的例子中会经常用到。接下来看看我们可以利用流来做什么。
用筛选法求素数序列
筛选法求素数序列是这样求的:1、2是素数,将2后面的整数中是2倍数的数删去(过滤);
2、3是素数,将3后面的整数中是3倍数的数删去;
3、4在第1步已经被删掉了。5是素数。将5后面的整数中是5倍数的数删去;
……
重复这个过程,最后留下来的就是素数序列。以流计算模式的思路来看,就是每次取出一个素数p后,就以不整除这个素数p作为过滤条件对后面的流进行过滤。下面是代码:
def sieve(): def divisible(x): return lambda e: e % x != 0 stream = integers_starting_from(2) while True: x = stream.next() yield x stream = stream_filter( divisible(x), #lambda e: e % x != 0, <-- 这里不能用lambda,否则x的值会不对导致过滤错误。 stream)
最开始的流是一个从2开始的整数序列。每次从流中取出一个数x(第一次取出的是2,后面取出的是后继的素数),新建一个过滤条件divisible(x),用stream_filter过滤这个序列。举个例子:
1、第一次调用,返回2,stream变成:{x | x <- [3, 4, ...], x%2 != 0}
2、第二次调用,返回3,stream变成:{x | x <- [4, 5, ...], x%2 != 0, x%3 != 0}
3、第三次调用,返回5(因为4被过滤了),stream变成:{x | x <- [6, 7, ...], x%2 != 0, x%3 != 0, x%5 != 0}
……
留下来的只剩素数。下面代码打印前100个素数:
def printn(n, stream): for _ in xrange(n): print stream.next(), print printn(100, sieve())
输出:2 3 5 7 11 13 17 19 23 29 31 37 41 43 47 53 59 61 67 71 73 79 83 89 97 101 103 107 109 113 127 131 137 139 149 151 157 163 167 173 179 181 191 193 197 199 211 223 227 229 233 239 241 251 257 263 269 271 277 281 283 293 307 311 313 317 331 337 347 349 353 359 367 373 379 383 389 397 401 409 419 421 431 433 439 443 449 457 461 463 467 479 487 491 499 503 509 521 523 541
用级数和计算\(\pi\)
\(\pi\)可以用这个级数来计算:$$ {\pi \over 4} = 1 – {1 \over 2} + {1 \over 3} – {1 \over 4} + \ldots $$
首先写一个生成这个级数每一项的流:
def pi_summands(): n = 1 sign = 1 while True: yield 1.0 / n * sign n += 2 sign *= -1
接下来定义一个流的变换,这个变换输入一个流stream,输出stream的部分和序列。也就是说输出流的第一项是stream的第一项,第二项是stream的第一项加第二项,第三项是stream的第一项加第二项加第三项……
def partial_sums(stream): acc = stream.next() yield acc while True: acc += stream.next() yield acc
于是上面说的级数的部分和序列的4倍就是一个逼近\(\pi\)的序列:
def pi_stream(): return stream_map( lambda x: 4 * x, partial_sums(pi_summands())) printn(10, pi_stream()) # 打印前10个近似值
输出是:4.0 2.66666666667 3.46666666667 2.89523809524 3.33968253968 2.97604617605 3.28373848374 3.01707181707 3.25236593472 3.04183961893
pi_stream的收敛速度慢得令人发指,不过有一种叫序列加速器的技巧能加快pi_stream的收敛速度。这个加速器是欧拉发现的。对收敛序列采用如下变换,将会极大地加快原序列的收敛速度:
$$ S_{n+1} – {(S_{n+1} – S_n)^2 \over S_{n-1} – 2S_n + S_{n_1}} $$
\(S_n\)就是原序列的第\(n\)项。在我们的问题里就是pi_stream的第\(n\)项。加速器变换的代码:
def euler_transform(stream): def transform(s0, s1, s2): ds = s2 - s1 return s2 - ds * ds / (s0 + s2 - 2 * s1) s0 = stream.next() s1 = stream.next() while True: s2 = stream.next() yield transform(s0, s1, s2) s0, s1 = s1, s2
利用加速器帮助计算\(\pi\):
printn(10, euler_transform(pi_stream()))
输出是:3.16666666667 3.13333333333 3.14523809524 3.13968253968 3.14271284271 3.14088134088 3.14207181707 3.14125482361 3.14183961893 3.1414067185
收敛速度明显快很多了,第十项和原来相比更接近\(\pi\)了。
可以多次对序列加速:
# 加速2次 printn(10, euler_transform(euler_transform(pi_stream()))) # 加速3次 printn(10, euler_transform(euler_transform(euler_transform(pi_stream()))))
加速2次的输出:3.14210526316 3.14145021645 3.141643324 3.1415712902 3.1416028416 3.14158732095 3.14159565524 3.14159086271 3.14159377424 3.14159192394
加速3次的输出:3.14159935732 3.1415908604 3.14159323124 3.14159243844 3.14159274346 3.14159261243 3.14159267391 3.14159264291 3.14159265951 3.14159265016
另外,SICP还描述了一个“超级加速器”的技巧,原理大致是取对角线,越靠后的项被加速越多次。这里就不细讲了,直接贴代码和输出吧。
def accelerated_sequence(transform, stream): s = stream while True: s, s_bak = tee(s) yield s.next() s = transform(s_bak) # 打印前9项 printn(9, accelerated_sequence(euler_transform, pi_stream()))
输出:4.0 3.16666666667 3.14210526316 3.14159935732 3.14159271403 3.14159265398 3.14159265359 3.14159265359 3.14159265359
可以看出从第7项开始就没什么变化了。SICP里有提到,这个序列的第8项就已经精确到14位数字,原序列需要计算到\(10^{13}\)的数量级的项才能到达这个精度。另外,在这里不能计算到第10项——计算第10项的时候程序就会像李卫公的开方机器一样散架——浮点数溢出。
模拟电路进行计算
重新来看求部分和的问题。求部分和其实相当于一个带反馈的电路: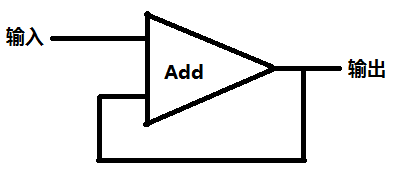
def add_stream(s1, s2): while True: yield s1.next() + s2.next() def stream_cons(v, f): yield v while True: yield f().next() def partial_sums_with_init(stream, init): def _s(): return stream_cons(init, lambda: add_stream(stream, feedback)) output, feedback = tee(_s()) return output # 打印自然数部分和的前10项 printn(10, partial_sums_with_init(integers_starting_from(1), 0))
代码的重点在partial_sums_with_init函数。这里利用lambda做出了一个延后求值的技巧,因为feedback(就是那条反馈的线)就是最终输出,而计算最终输出又需要feedback的输入(第一项不用,第一项返回初始值init)。这部分也不细讲了,代码应该写得很清楚了,用文字讲反而画蛇添足。利用这种模拟电路的方法可以用来做积分、微分的数值计算、计算微分方程的数值解等。
------------------------------------我是最后的分割线---------------------------------------------------------
最后说一下,这里用yield实现的流计算模式要特别注意“副作用”。这里的流(Generator)每次调用next(),都会改变状态,所以一个流放入一个变换后就不能再放入其他变换了。
完整代码可以在https://github.com/sKabYY/palestra/blob/master/python/stream/stream.py下载。
对了,SICP是《计算机的构造与解释》的简称,最近刚看完,蛮有意思的一本书,推荐大家看看。

相关文章推荐
- 使用观察者模式实现线程将计算结果回调给多个对象
- Python实现一些简单的算法(2)—计算余数与random模块的使用
- Python yield 实现线程内参与者模式(线程内并发)
- Python使用logging结合decorator模式实现优化日志输出的方法
- Python3-Selenium3使用PO设计模式(Page Object)实现简单的页面登录操作
- 浅谈使用Python内置函数getattr实现分发模式
- python中getattr函数使用方法 getattr实现工厂模式
- 使用 __new__ 实现 Python 的单例模式
- Python的yield协程机制实现生产者-消费者模式
- python的协程和并发-使用yield实现并有使用详解
- python中的__new__方法与__init__方法区别与调用;通过使用__new__实现单例模式
- Python使用logging结合decorator模式实现优化日志输出的方法
- python中getattr函数使用方法 getattr实现工厂模式
- [python]使用python实现Hadoop MapReduce程序:计算一组数据的均值和方差
- 使用Python语言写一个简单的KMP模式匹配算法实现
- Python中使用 metaclass 实现Singleton 模式
- 流畅的python 第六章: 使用一等函数实现设计模式
- 使用python的yield实现任务调度.给定一个任务列表,每个任务轮流切换执行,类似于切片
- 设计模式-观察者模式,以及如何使用观察者来为app实现即时通讯功能
- 使用python获取CPU和内存信息的思路与实现(linux系统)