Google在KDD2013上关于CTR的一篇论文
2013-11-13 11:31
218 查看
最近在做CTR,刚好Google在KDD发了一篇文章,讲了他们的一些尝试,总结一下:
先是一些公式的符号说明:

一、优化算法
CTR中经常用Logistic regression进行训练,一个常用的Loss Function为

Online gradient descent(OGD)是一个常用的优化方法,但是在加上L1正则化后,这种方法不能产生有效的稀疏模型。相比之下 Regularized Dual Averaging (RDA)拥有更好的稀疏性,但是精度不如OGD好。
FTRL-Proximal 方法可以同时得到稀疏性与精确性,不同于OGD的迭代步骤:

其
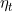
是一个非增的学习率
FTRL-Proximal通过下式迭代:

其中参数
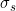
是学习率,一般我们有
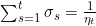
。
更新公式:

算法如下:

这里多个一个
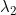
是一个L2正则化参数。
二、学习率
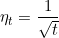
由于在求解时,这样,对每一个坐标我们都使用了同样的参数,这样一些没有使用的坐标的参数也会下降,显然这不太合理。
一个近似最优的选择是:

g是梯度向量
三、存储空间
1.特征选择
在CTR中,跟多特征仅仅出现了一次(In fact, in some of our models, half the unique features occur only once in the entire training set of billions of examples),这样特征几乎没有什么用,但是存储起来非常浪费空间。L1正则化虽然解决了一些问题,但是这样降低了一些精度,因此另一个选择是
probabilistic feature inclusion,这种方法中,一个特征第一次出现时,会以一定的概率被保存使用。关于这个概率Google尝试了两种方法:
Poisson Inclusion:以概率p增加特征,这样一般特征被加入就需要出现1/p次
Bloom Filter Inclusion:用一系列的Bloom flters来检测特征的前n次出现,一旦检测到出现了n次(因为BF有冲突,所以实际可能少于n),就加入模型并用在后面的训练中。
2.系数编码
因为大部分系数都在-2和2之间,因此使用了定点的q2.13编码,同时也保证了小数的一些精度。编码包括一位的符号,2位的整数和13位的小数。
因此误差可能在OGD算法中发散,因此使用了一个简单的随机取整策略:

R是一个0到1的随机整数。
3.多个相似模型的训练
在测试一些超参数的影响时,同时训练多个模型非常有用。观察发现,有些数据可以被多个模型共用,但是另外一些(如系数)不能,如果把模型的系数存在一个HASH表里,就可以让多个变体同时使用这些参数,比如学习率。
4.单值结构
有时我们想训练一些模型,他们之间只是删除或增加了一些特征。单值特征为每一个特征存了一个权重,权重被所有有该特征的模型共享,学习方法如下:
在OGD更新中,每个模型用他自己的的那部分特征计算一个Loss, 然后对每一个特征,每一个模型计算一个新的系数,最后把所有值平均后存为单值。该单值下一步被所有模型使用。
5.计数与梯度
假设所有事件包括统一特征的概率相同(一个粗糙但是有效的估计),其中出现了P次,没有出现N次,那么出现的概率就是p=P/(N+P),那么在logistic regression中,正事件的导数是p-1,负事件p,梯度的平方和就是:

6.采样训练数据:
CTR中的负样本远高与正样本,因此采样的数据包括满足所有的正样本和部分负样本:

在训练中给正样本1的权重,负样本1/r的权重以避免模型结果出错。权重乘如Loss Function对应项中。


四、模型评价1
1.进度验证(Progressive Validation)
因为计算梯度的同时需要计算预测值,因此可以收集这些值。在线的loss反映了算法的表现---他度量了训练一个数据前得到的预测结果。这样也使得所有数据被同时作用训练集和测试集使用。
2.可视化加强理解

上图对query进行了切片后,将两个模型与一个控制模型模型进行了比较。度量用颜色表示,每行是一个模型,每列是一个切片。
五、置信估计

六、预测矫正
矫正的数据

p是模型预测的CTR,d是一些训练数据。
一个常用矫正:

两个参数可以用Poisson regression在数据上训练。
先是一些公式的符号说明:

一、优化算法
CTR中经常用Logistic regression进行训练,一个常用的Loss Function为

Online gradient descent(OGD)是一个常用的优化方法,但是在加上L1正则化后,这种方法不能产生有效的稀疏模型。相比之下 Regularized Dual Averaging (RDA)拥有更好的稀疏性,但是精度不如OGD好。
FTRL-Proximal 方法可以同时得到稀疏性与精确性,不同于OGD的迭代步骤:

其
是一个非增的学习率
FTRL-Proximal通过下式迭代:

其中参数
是学习率,一般我们有
。
更新公式:

算法如下:

这里多个一个
是一个L2正则化参数。
二、学习率
由于在求解时,这样,对每一个坐标我们都使用了同样的参数,这样一些没有使用的坐标的参数也会下降,显然这不太合理。
一个近似最优的选择是:

g是梯度向量
三、存储空间
1.特征选择
在CTR中,跟多特征仅仅出现了一次(In fact, in some of our models, half the unique features occur only once in the entire training set of billions of examples),这样特征几乎没有什么用,但是存储起来非常浪费空间。L1正则化虽然解决了一些问题,但是这样降低了一些精度,因此另一个选择是
probabilistic feature inclusion,这种方法中,一个特征第一次出现时,会以一定的概率被保存使用。关于这个概率Google尝试了两种方法:
Poisson Inclusion:以概率p增加特征,这样一般特征被加入就需要出现1/p次
Bloom Filter Inclusion:用一系列的Bloom flters来检测特征的前n次出现,一旦检测到出现了n次(因为BF有冲突,所以实际可能少于n),就加入模型并用在后面的训练中。
2.系数编码
因为大部分系数都在-2和2之间,因此使用了定点的q2.13编码,同时也保证了小数的一些精度。编码包括一位的符号,2位的整数和13位的小数。
因此误差可能在OGD算法中发散,因此使用了一个简单的随机取整策略:

R是一个0到1的随机整数。
3.多个相似模型的训练
在测试一些超参数的影响时,同时训练多个模型非常有用。观察发现,有些数据可以被多个模型共用,但是另外一些(如系数)不能,如果把模型的系数存在一个HASH表里,就可以让多个变体同时使用这些参数,比如学习率。
4.单值结构
有时我们想训练一些模型,他们之间只是删除或增加了一些特征。单值特征为每一个特征存了一个权重,权重被所有有该特征的模型共享,学习方法如下:
在OGD更新中,每个模型用他自己的的那部分特征计算一个Loss, 然后对每一个特征,每一个模型计算一个新的系数,最后把所有值平均后存为单值。该单值下一步被所有模型使用。
5.计数与梯度
假设所有事件包括统一特征的概率相同(一个粗糙但是有效的估计),其中出现了P次,没有出现N次,那么出现的概率就是p=P/(N+P),那么在logistic regression中,正事件的导数是p-1,负事件p,梯度的平方和就是:

6.采样训练数据:
CTR中的负样本远高与正样本,因此采样的数据包括满足所有的正样本和部分负样本:

在训练中给正样本1的权重,负样本1/r的权重以避免模型结果出错。权重乘如Loss Function对应项中。


四、模型评价1
1.进度验证(Progressive Validation)
因为计算梯度的同时需要计算预测值,因此可以收集这些值。在线的loss反映了算法的表现---他度量了训练一个数据前得到的预测结果。这样也使得所有数据被同时作用训练集和测试集使用。
2.可视化加强理解

上图对query进行了切片后,将两个模型与一个控制模型模型进行了比较。度量用颜色表示,每行是一个模型,每列是一个切片。
五、置信估计

六、预测矫正
矫正的数据

p是模型预测的CTR,d是一些训练数据。
一个常用矫正:

两个参数可以用Poisson regression在数据上训练。

相关文章推荐
- Google在KDD2013上关于CTR的一篇论文(转载)
- Google在KDD2013上关于CTR的一篇论文
- Google关于BigTable技术论文中文版
- 一篇关于数学建模美赛论文撰写的心得
- 最后推荐一篇关于Pre-Echo的总结论文
- 关于IP分片的一篇小论文
- 关于一篇icsp的论文
- 一场关于Google成功和博士发表论文的大讨论
- 关于x264的一篇论文:讲解很详细
- 关于x264的一篇论文:讲解很详细
- 一篇关于如何用深度学习完成自动上色(Automatic Image Colorization)的论文浅析
- 关于地震:一篇过气的牛论文
- 关于google是如何搜索的论文
- 一篇关于AC自动机论文的译文:《Biosequence Algorithms, Spring 2005 Lecture 4: Set Matching and Aho-Corasick Algorit
- 最近在写一篇论文,关于通用计算的
- 一篇关于UG二次开发的论文
- Google关于大数据的三篇著名论文 中文版
- 一篇关于javascript面向对象开发的论文
- 关于EDA的一篇短论文
- Google关于MapReduce技术论文中文版