C语言学习笔记
2013-10-29 22:08
435 查看
原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 、作者信息和本声明。否则将追究法律责任。http://kymsha.blog.51cto.com/647951/289350
1. 编译和链接
将程序转化为机器可执行的代码,C语言分为三个步骤:
A. 预编译。程序首先会交给预处理器,预处理器执行以#开头的指令,然后给程序添加指令,或者修改指令。
B. 编译。修改后的程序进入编译器,编译器会把程序翻译成机器指令(也就是目标代码),但是这样的程序还是不能执行的。
C. 链接。链接器把由编译器产生的目标代码和其他所需的代码整合到一起,这些附加代码包括程序中用到的库函数。这样就产生了完全可执行的程序。
2. main函数中的exit和return
在main函数中,以两者结尾是一样的。都是终止程序执行,并且向操作系统返回0。
不过exit需要引入stdlib.h库函数。
3. %i和%d
在printf中使用时,两者没有区别,但是在scanf中,%d只能接受10进制的整数。
但是%i还可以接受八进制和十六进制的整数。

4. scanf函数
scanf本质上是一种“模式匹配”函数。
但是在Visual Studio中调用scanf函数时会给出这样的提示:The function may be unsafe.Please using scanf_s instead.
当用户从键盘输入时,程序并没有读取输入,而是把用户的输入放在一个隐藏的缓冲区中,由scanf来读取。因此如果用户输入了多余的字符,scanf无法彻底完成模式匹配,scanf就会把字符放回缓冲区供后续scanf函数的读取。
1. C语言中的布尔类型
在C语言中,是没有布尔类型的,0就是false,非0就是true。
于是,写习惯了Java/C#的我们自然会很不习惯,这个时候,我们不妨用宏定义来使我们的代码看起来更舒服一些。
在C99中,长期缺乏布尔类型的问题得到的解决,但是在目前,C99标准还没有得到很好的推广。暂且不提。
2. limits.h
习惯了平台无关的我们,在学习C语言时,必须需要注意他的平台相关性。其中很典型的例子就是在不同的平台下,不同的编译器下,int的取值范围是不同的。
在C#中,我们可以用Int32.MaxValue来获得,那么在C语言中,我们该怎么获得呢?
在C中,提供了一个头文件limits.h,里面有很多宏定义。
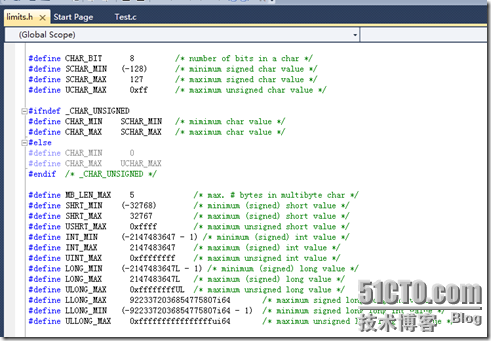
那么我们就很容易得到int类型的取值范围。
3.
浮点类型
在C语言中,提供了三种浮点类型:分别为
float:单精度浮点数,
double:双精度浮点数,
long double:扩展精度浮点数。
在一般要求不严格的情况下,float就足够了,其次是double,long double几乎不会用到。
在C99中,浮点类型包括两种,分别为实浮点类型,就是我们上面提到的。还有复数类型,分别对应为float_Complex等等。
4. 字符类型
在C语言中,一般采用的ASCII编码,而字符类型又分为有符号型和无符号型。在C语言标准中,对此并无规定,因此是由不同的编译器自己决定。
因此考虑到可移植性,如果涉及到符号相关,我们不要假设char是有符号还是无符号,而用signed和unsigned来显式标识。
由于在C语言中,字符实际上是被作为整数来处理的,因此在C89中,将字符类型和整数类型统称为整值类型。
C语言读入字符不会跳过空白字符。我们可以看一个简单的例子:
我现在键入一个换行:
他也把换行符读入,然后打印出来。
那么我们如何读入一串字符串呢?
当然,我们也可以这样来写:
5. getchar和putchar
在C语言中,为我们提供了专门输入和输出字符的函数,也就是getchar()和putchar().
让我们看下getchar()和putchar()的定义。
_Check_return_ _CRTIMP int __cdecl getchar(void);
_Check_return_opt_ _CRTIMP int __cdecl putchar(_In_ int _Ch);
我们可以看到,其实他们返回的都是int类型的值。OK,让我们看看他们都返回什么。
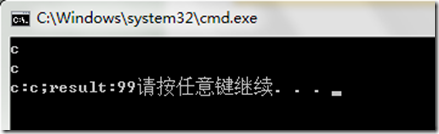
我们可以看到,他们都是返回其字符的ASCII码。
那么,既然C语言为我们提供了这样专门的函数,一定说明他在读取和输出字符方法比scanf和printf有着特殊的优势。
A. 由于getchar和putchar函数实现比较简单,因此较之效率更高。
B. 为了额外的效率提升,通常getchar和putchar都是作为宏来实现的。
总之,他们相较之略显重量的scanf和printf效率更高。
另外,我们还可以用getchar来实现读取字符的C语言惯用法。
这样的函数一直读到换行终止。
另外:
我们也可以这样来实现忽略一切空白,当然也可以修改程序使之忽略其他字符。
另外,我们在前文说过,scanf在无法完成彻底模式匹配时,会把剩余的字符放到缓冲区,供下次读取。那么我们来看这样一段代码:
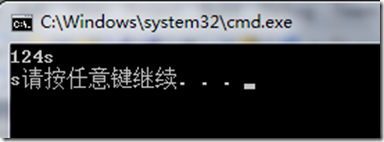
由此可知,getchar()也会首先打缓冲区里去读取字符。
1. 数组大小
我相信,在C#/Java中,更多的人愿意用List<T>来取代数组,一方面是List提供了较多的方法,另一方面也无需我们去指定数组的大小。
那么在C语言中,我们既然需要必须指定数组的大小,而一般来讲,很多数组大小事我们无法确定并且经常会发生变化的,那么我们最好的方式就是用宏定义来限定数组的大小。
如果包含多个数组的话,用宏就很难记忆,那么我们就可以利用sizeof运算符。
注意,我们之前说过,sizeof返回的值是size_t,因此,我们在计算时,最好将其先强制类型转换为我们可以控制的类型。
2. 数组初始化
一般情况下,我们初始化数组都是把整数数组初始化为0,那么我们一般会怎么做呢?
那么如过SIZE=100怎么办,那么很多人都会这样去做。
其实我们完全不用麻烦,这么一句代码就可以搞定了。
在C99中,提供了一种初始化式,使得我们可以这样来写。
而其他的数字就都默认为0。那么我们来考虑这样一段代码:
那么在C99中,这段代码的结果究竟是什么呢?这个就需要我们来了解一下数组初始化式的原理。
其实,编译器在初始化式数组列表时,都会记录下一个待初始化的元素的位置,比如说在初始化index=0的元素时,会记录下1,这样以此类推,但是当初始化index=5的时候,首先根据他的初始化式记录下一个待初始化的元素时index=1,然后初始化index=0的元素为6。那么也就是说:最后的结果应该是{6,7,8,4,5,0,0,0,0,0}。
3. 常量数组
当数组加上const就变成了常量数组,常量数组主要有两个好处。
1. 告诉使用者,这个数组是不应该被改变的。
2. 有助于编译器发现错误。
4. C99的变长数组
这是个很爽的东西,我们再也不必担心为数组指定大小而发愁了,指定大了会造成空间的浪费,指定小了又不够用。
在C99中,他的长度会由程序执行时进行计算。
方式如下:
5. 数组的复制
很多时候,我们需要把一个数组的元素复制到另一个数组上,我们大多数人第一个想到的就是循环复制。
其实还有一种更好的方法是使用memcpy方法,这是一个底层函数,它把内存的字节从一个地方复制到另一个地方,效率更高。
本文出自 “kym” 博客,请务必保留此出处http://kymsha.blog.51cto.com/647951/289350
1. 编译和链接
将程序转化为机器可执行的代码,C语言分为三个步骤:
A. 预编译。程序首先会交给预处理器,预处理器执行以#开头的指令,然后给程序添加指令,或者修改指令。
B. 编译。修改后的程序进入编译器,编译器会把程序翻译成机器指令(也就是目标代码),但是这样的程序还是不能执行的。
C. 链接。链接器把由编译器产生的目标代码和其他所需的代码整合到一起,这些附加代码包括程序中用到的库函数。这样就产生了完全可执行的程序。
2. main函数中的exit和return
在main函数中,以两者结尾是一样的。都是终止程序执行,并且向操作系统返回0。
不过exit需要引入stdlib.h库函数。
#include <stdio.h>
#include <stdlib.h>
int main (void)
{
printf("Hello world");
exit(0);
//return 0;
}3. %i和%d
在printf中使用时,两者没有区别,但是在scanf中,%d只能接受10进制的整数。
但是%i还可以接受八进制和十六进制的整数。
#include <stdio.h>
#include <stdlib.h>
int main (void)
{
int i ;
scanf_s("%i",&i);
printf("%d",i);
}
4. scanf函数
scanf本质上是一种“模式匹配”函数。
但是在Visual Studio中调用scanf函数时会给出这样的提示:The function may be unsafe.Please using scanf_s instead.
当用户从键盘输入时,程序并没有读取输入,而是把用户的输入放在一个隐藏的缓冲区中,由scanf来读取。因此如果用户输入了多余的字符,scanf无法彻底完成模式匹配,scanf就会把字符放回缓冲区供后续scanf函数的读取。
1. C语言中的布尔类型
在C语言中,是没有布尔类型的,0就是false,非0就是true。
于是,写习惯了Java/C#的我们自然会很不习惯,这个时候,我们不妨用宏定义来使我们的代码看起来更舒服一些。
#define BOOL int
#define TRUE 1
#define FALSE 0
int main (void)
{
BOOL flag=TRUE;
if(flag)
{
printf("true");
}
else
{
printf("false");
}
}在C99中,长期缺乏布尔类型的问题得到的解决,但是在目前,C99标准还没有得到很好的推广。暂且不提。
2. limits.h
习惯了平台无关的我们,在学习C语言时,必须需要注意他的平台相关性。其中很典型的例子就是在不同的平台下,不同的编译器下,int的取值范围是不同的。
在C#中,我们可以用Int32.MaxValue来获得,那么在C语言中,我们该怎么获得呢?
在C中,提供了一个头文件limits.h,里面有很多宏定义。

那么我们就很容易得到int类型的取值范围。
#include <stdio.h>
#include <stdlib.h>
#include <limits.h>
int main (void)
{
printf("int的最小值是:%d;最大值是:%d",INT_MIN,INT_MAX);
return 0;
}3.
浮点类型
在C语言中,提供了三种浮点类型:分别为
float:单精度浮点数,
double:双精度浮点数,
long double:扩展精度浮点数。
在一般要求不严格的情况下,float就足够了,其次是double,long double几乎不会用到。
在C99中,浮点类型包括两种,分别为实浮点类型,就是我们上面提到的。还有复数类型,分别对应为float_Complex等等。
4. 字符类型
在C语言中,一般采用的ASCII编码,而字符类型又分为有符号型和无符号型。在C语言标准中,对此并无规定,因此是由不同的编译器自己决定。
因此考虑到可移植性,如果涉及到符号相关,我们不要假设char是有符号还是无符号,而用signed和unsigned来显式标识。
由于在C语言中,字符实际上是被作为整数来处理的,因此在C89中,将字符类型和整数类型统称为整值类型。
C语言读入字符不会跳过空白字符。我们可以看一个简单的例子:
int main (void)
{
char ch;
scanf("%c",&ch);
printf("%c",ch);
return 0;
}我现在键入一个换行:

他也把换行符读入,然后打印出来。
那么我们如何读入一串字符串呢?
int main (void)
{
char ch='a';
int count=0;
do
{
scanf("%c",&ch);
count++;
}while(ch!='\n');
printf("%d",count-1);
}当然,我们也可以这样来写:
int main (void)
{
char ch='a';
int count=0;
scanf("%c",&ch);
while(ch!='\n')
{
count++;
scanf("%c",&ch);
}
printf("%d",count);
}5. getchar和putchar
在C语言中,为我们提供了专门输入和输出字符的函数,也就是getchar()和putchar().
让我们看下getchar()和putchar()的定义。
_Check_return_ _CRTIMP int __cdecl getchar(void);
_Check_return_opt_ _CRTIMP int __cdecl putchar(_In_ int _Ch);
我们可以看到,其实他们返回的都是int类型的值。OK,让我们看看他们都返回什么。
int main (void)
{
char c;
int result;
c=getchar();
result = putchar(c);
printf("\nc:%c;result:%d",c,result);
}
我们可以看到,他们都是返回其字符的ASCII码。
那么,既然C语言为我们提供了这样专门的函数,一定说明他在读取和输出字符方法比scanf和printf有着特殊的优势。
A. 由于getchar和putchar函数实现比较简单,因此较之效率更高。
B. 为了额外的效率提升,通常getchar和putchar都是作为宏来实现的。
总之,他们相较之略显重量的scanf和printf效率更高。
另外,我们还可以用getchar来实现读取字符的C语言惯用法。
int main (void)
{
while(getchar()!='\n');
return 0;
}这样的函数一直读到换行终止。
另外:
int main (void)
{
char c;
while((c=getchar())==' ');
switch(c)
{
case 'a':
printf("a");
break;
case 'q':
printf("q");
break;
default:
printf("others");
break;
}
}我们也可以这样来实现忽略一切空白,当然也可以修改程序使之忽略其他字符。
另外,我们在前文说过,scanf在无法完成彻底模式匹配时,会把剩余的字符放到缓冲区,供下次读取。那么我们来看这样一段代码:
int main (void)
{
int i ;
char c;
scanf("%d",&i);
c=getchar();
printf("%c",c);
}
由此可知,getchar()也会首先打缓冲区里去读取字符。
1. 数组大小
我相信,在C#/Java中,更多的人愿意用List<T>来取代数组,一方面是List提供了较多的方法,另一方面也无需我们去指定数组的大小。
那么在C语言中,我们既然需要必须指定数组的大小,而一般来讲,很多数组大小事我们无法确定并且经常会发生变化的,那么我们最好的方式就是用宏定义来限定数组的大小。
#define SIZE 10
int main (void)
{
int a[SIZE];
}如果包含多个数组的话,用宏就很难记忆,那么我们就可以利用sizeof运算符。
int main (void)
{
int a[]={1,3,4,55,6,7,89,9,0};
int i ;
printf("%d",(int)sizeof(a)/(int)sizeof(a[0]));
for(i=0;i<(int)sizeof(a)/(int)sizeof(a[0]);i++)
{
a[i]=0;
}
for(i=0;i<(int)sizeof(a)/(int)sizeof(a[0]);i++)
{
printf("%d\n",a[i]);
}
}注意,我们之前说过,sizeof返回的值是size_t,因此,我们在计算时,最好将其先强制类型转换为我们可以控制的类型。
2. 数组初始化
一般情况下,我们初始化数组都是把整数数组初始化为0,那么我们一般会怎么做呢?
#define SIZE 5
int main (void)
{
int a[SIZE]={0,0,0,0,0};
}那么如过SIZE=100怎么办,那么很多人都会这样去做。
#define SIZE 100
int main (void)
{
int a[SIZE];
int i ;
for(i=0;i<SIZE;i++)
{
a[i]=0;
}
}其实我们完全不用麻烦,这么一句代码就可以搞定了。
#define SIZE 100
int main (void)
{
int a[SIZE]={0};
}在C99中,提供了一种初始化式,使得我们可以这样来写。
#define SIZE 100
int main (void)
{
int a[SIZE]={[5]=100,[50]=49};
}而其他的数字就都默认为0。那么我们来考虑这样一段代码:
#define SIZE 10
int main (void)
{
int a[SIZE]={1,2,3,4,5,[0]=6,7,8};
}那么在C99中,这段代码的结果究竟是什么呢?这个就需要我们来了解一下数组初始化式的原理。
其实,编译器在初始化式数组列表时,都会记录下一个待初始化的元素的位置,比如说在初始化index=0的元素时,会记录下1,这样以此类推,但是当初始化index=5的时候,首先根据他的初始化式记录下一个待初始化的元素时index=1,然后初始化index=0的元素为6。那么也就是说:最后的结果应该是{6,7,8,4,5,0,0,0,0,0}。
3. 常量数组
当数组加上const就变成了常量数组,常量数组主要有两个好处。
1. 告诉使用者,这个数组是不应该被改变的。
2. 有助于编译器发现错误。
4. C99的变长数组
这是个很爽的东西,我们再也不必担心为数组指定大小而发愁了,指定大了会造成空间的浪费,指定小了又不够用。
在C99中,他的长度会由程序执行时进行计算。
方式如下:
int main (void)
{
int size;
int a[size];
scanf("%d",&size);
}5. 数组的复制
很多时候,我们需要把一个数组的元素复制到另一个数组上,我们大多数人第一个想到的就是循环复制。
#define SIZE 10
int main (void)
{
int a[SIZE];
int b[SIZE];
int i ;
for(i=0;i<SIZE;i++)
{
a[i]=i;
}
for(i=0;i<SIZE;i++)
{
b[i]=a[i];
}
for(i=0;i<SIZE;i++)
{
printf("%d",b[i]);
}
}其实还有一种更好的方法是使用memcpy方法,这是一个底层函数,它把内存的字节从一个地方复制到另一个地方,效率更高。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define SIZE 10
int main (void)
{
int a[SIZE];
int b[SIZE];
int i ;
for(i=0;i<SIZE;i++)
{
a[i]=i;
}
memcpy(b,a,sizeof(a));
for(i=0;i<SIZE;i++)
{
printf("%d",b[i]);
}
}本文出自 “kym” 博客,请务必保留此出处http://kymsha.blog.51cto.com/647951/289350
