C语言的内存模型
2013-10-24 23:39
197 查看
本文以IA-32环境为例.
一、内存类型
1.代码段(Code or Text):代码段由程序中的机器码组成。在C语言中,程序语句进行编译后,形成机器代码。在执行程序的过程中,CPU的程序计数器指向代码段的每一条代码,并由处理器依次运行。
2.只读数据段(RO data):只读数据段是程序使用的一些不会被更改的数据,使用这些数方式类似查表式的操作,由于这些变量不需要更改,因此只需要放置在只读存储器中即可。
3.已初始化读写数据段(RW data):已初始化数据是在程序中声明,并且具有初值的变量,这些变量需要占用存储器的空间,在程序执行时它们需要位于可读写的内存区域内,并具有初值,以供程序运行时读写。
4.未初始化读写数据段(BSS):未初始化读写据是在程序中声明,但是没有初始化的变量,这些变量在程序运行之前不需要占用存储器的空间。
5.堆(heap):堆内存只在程序运行时出现,一般由程序员分配(malloc)和释放(free)。在具有操作系统的情况下,如果程序员没释放,操作系统可以在程序结束后回收内存。
6.栈(stack):栈内存只在程序运行时出现,在函数内部使用的变量,函数的参数以及返回值将使用栈空间,栈空间由编译器自动分配和释放。C语言默认的调用惯例规定函数参数一般是按从右向左的顺序入栈。(注1)
二、内存布局
1.内存静态布局
C语言目标文件的内存布局如下图所示:
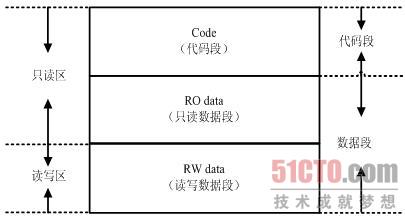
C语言程序分为映像和运行时两种状态。在编译-连接后形成的映像中,将只包含代码段(Text)、只读数据段(ROData)和读写数据段(RWData)。在程序运行之前,将动态生成未初始化数据段(BSS)(注2),在程序的运行时还将动态形成堆(Heap)区域和栈(Stack)区域。
一般来说,在静态的映像文件中,各个部分称之为节(Section),而在运行时的各个部分称之为段(Segment)。如果不详细区分,可以统称为段。
2.内存动态布局
这里主要是区分堆与栈的概念。
栈:在windows下栈是向低地址扩展的数据结构,是一块连续的内存区域(它的生长方向与内存的生长方向相反)。栈的大小是固定的。如果申请的空间超过栈的剩余空间时,将提示overflow。
堆:堆是向高地址扩展的数据结构(它的生长方向与内存的生长方向相同),是不连续的内存区域。这是由于系统使用链表来存储空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。
由于栈是函数调用的核心结构,而且栈的生长方向与内存生长方向相反,这里着重讲一下栈的结构。
下图是一张小端模式的栈内存示意图。上部是低地址区,下部是高地址区,从右往左,地址依次升高。(假设一行为4字节)
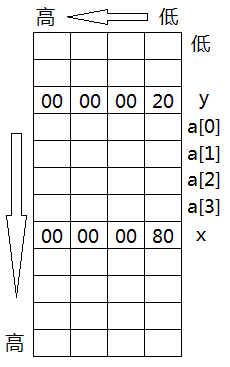
某函数内部现有如下代码片段:
依次由高地址向低地址方向分配内存x,a[],y(假设比x更高的地址已经被分配)。值得注意的是,数组内部还是由低地址到高地址的方式来分配a[0],a[1],a[2],a[3]。(所以虽然栈里内存的分配方向与栈增长方向相反,但是我们在做指针自增操作*p++的时候得到的结果与我们的预期一致。)
当我们操作不慎,数组访问越界时:
printf("%x", *(a + 4));
得到的结果将是80,而非20。
值得注意的是,假设地址按单字节编码,那么x的地址,其实就是"80"所在字节的内存编码。所以,对于如下代码:
我们得到的结果将是80000000。
这里就有必要解释一下大端模式和小端模式的概念了。
Big-Endian和Little-Endian的定义如下:
Little-Endian就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
Big-Endian就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
举一个例子,比如上述变量x的值0x00 00 00 80在内存中的表示形式为:
大端模式:
高地址<-----------------低地址
0x80 | 0x00 | 0x00 | 0x00
小端模式:
高地址<-----------------低地址
0x00 | 0x00 | 0x00 | 0x80
可见,大端模式和字符串的存储模式类似。
所以,对于上述代码,在大端模式的机器上得到的结果将是00000080。
是不是有点迷糊?其实遇到大小端问题时,只要把上述的内存布局图画出来,再记住大小端模式的存放方式(这里有个口诀可以帮助记忆:小弟弟低低,大端自然就刚好相反了。。。是不是略邪恶

)问题就迎刃而解了。
这篇博文暂时先写到这儿,欢迎拍砖。有啥不对的地方还望能及时指出。
注1:为什么C语言要选择从右至左呢?
由于C语言支持函数具有可变参数:采用自右向左的入栈方式,可以保证最前面的参数将是所有参数中最靠近栈顶的(注意:不是栈顶)。如果采用自左至右的入栈方式,那么最左面的参数将是最靠近栈底的,如果事先不知道参数的个数,那么就无法通过栈指针的相对位移获取最左边的参数。
这边引申一道经典的笔试题:
想一想,答案究竟是多少呢?知道了参数入栈顺序,这题应该轻松加愉快了吧~
注2:与读写数据段类似,BSS也属于静态数据区,但是该段中的数据没有经过初始化。因此它只会在目标文件中被标识,而不会真正称为目标文件中的一段,该段将会在运行时产生。未初始化数据段只在运行的初始化阶段才会产生,因此它的大小不会影响目标文件的大小。
一、内存类型
1.代码段(Code or Text):代码段由程序中的机器码组成。在C语言中,程序语句进行编译后,形成机器代码。在执行程序的过程中,CPU的程序计数器指向代码段的每一条代码,并由处理器依次运行。
2.只读数据段(RO data):只读数据段是程序使用的一些不会被更改的数据,使用这些数方式类似查表式的操作,由于这些变量不需要更改,因此只需要放置在只读存储器中即可。
3.已初始化读写数据段(RW data):已初始化数据是在程序中声明,并且具有初值的变量,这些变量需要占用存储器的空间,在程序执行时它们需要位于可读写的内存区域内,并具有初值,以供程序运行时读写。
4.未初始化读写数据段(BSS):未初始化读写据是在程序中声明,但是没有初始化的变量,这些变量在程序运行之前不需要占用存储器的空间。
5.堆(heap):堆内存只在程序运行时出现,一般由程序员分配(malloc)和释放(free)。在具有操作系统的情况下,如果程序员没释放,操作系统可以在程序结束后回收内存。
6.栈(stack):栈内存只在程序运行时出现,在函数内部使用的变量,函数的参数以及返回值将使用栈空间,栈空间由编译器自动分配和释放。C语言默认的调用惯例规定函数参数一般是按从右向左的顺序入栈。(注1)
二、内存布局
1.内存静态布局
C语言目标文件的内存布局如下图所示:
C语言程序分为映像和运行时两种状态。在编译-连接后形成的映像中,将只包含代码段(Text)、只读数据段(ROData)和读写数据段(RWData)。在程序运行之前,将动态生成未初始化数据段(BSS)(注2),在程序的运行时还将动态形成堆(Heap)区域和栈(Stack)区域。
一般来说,在静态的映像文件中,各个部分称之为节(Section),而在运行时的各个部分称之为段(Segment)。如果不详细区分,可以统称为段。
2.内存动态布局
这里主要是区分堆与栈的概念。
栈:在windows下栈是向低地址扩展的数据结构,是一块连续的内存区域(它的生长方向与内存的生长方向相反)。栈的大小是固定的。如果申请的空间超过栈的剩余空间时,将提示overflow。
堆:堆是向高地址扩展的数据结构(它的生长方向与内存的生长方向相同),是不连续的内存区域。这是由于系统使用链表来存储空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。
由于栈是函数调用的核心结构,而且栈的生长方向与内存生长方向相反,这里着重讲一下栈的结构。
下图是一张小端模式的栈内存示意图。上部是低地址区,下部是高地址区,从右往左,地址依次升高。(假设一行为4字节)
某函数内部现有如下代码片段:
int x = 0x80; int a[4]; int y = 0x20;
依次由高地址向低地址方向分配内存x,a[],y(假设比x更高的地址已经被分配)。值得注意的是,数组内部还是由低地址到高地址的方式来分配a[0],a[1],a[2],a[3]。(所以虽然栈里内存的分配方向与栈增长方向相反,但是我们在做指针自增操作*p++的时候得到的结果与我们的预期一致。)
当我们操作不慎,数组访问越界时:
printf("%x", *(a + 4));
得到的结果将是80,而非20。
值得注意的是,假设地址按单字节编码,那么x的地址,其实就是"80"所在字节的内存编码。所以,对于如下代码:
char *p = (char *) &x;
for (i = 0; i < sizeof(x); i++)
printf("%x", *(p + i));我们得到的结果将是80000000。
这里就有必要解释一下大端模式和小端模式的概念了。
Big-Endian和Little-Endian的定义如下:
Little-Endian就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
Big-Endian就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
举一个例子,比如上述变量x的值0x00 00 00 80在内存中的表示形式为:
大端模式:
高地址<-----------------低地址
0x80 | 0x00 | 0x00 | 0x00
小端模式:
高地址<-----------------低地址
0x00 | 0x00 | 0x00 | 0x80
可见,大端模式和字符串的存储模式类似。
所以,对于上述代码,在大端模式的机器上得到的结果将是00000080。
是不是有点迷糊?其实遇到大小端问题时,只要把上述的内存布局图画出来,再记住大小端模式的存放方式(这里有个口诀可以帮助记忆:小弟弟低低,大端自然就刚好相反了。。。是不是略邪恶
)问题就迎刃而解了。
这篇博文暂时先写到这儿,欢迎拍砖。有啥不对的地方还望能及时指出。
注1:为什么C语言要选择从右至左呢?
由于C语言支持函数具有可变参数:采用自右向左的入栈方式,可以保证最前面的参数将是所有参数中最靠近栈顶的(注意:不是栈顶)。如果采用自左至右的入栈方式,那么最左面的参数将是最靠近栈底的,如果事先不知道参数的个数,那么就无法通过栈指针的相对位移获取最左边的参数。
这边引申一道经典的笔试题:
int i = 3;
printf("%d %d %d", i++, ++i, ++i);想一想,答案究竟是多少呢?知道了参数入栈顺序,这题应该轻松加愉快了吧~
注2:与读写数据段类似,BSS也属于静态数据区,但是该段中的数据没有经过初始化。因此它只会在目标文件中被标识,而不会真正称为目标文件中的一段,该段将会在运行时产生。未初始化数据段只在运行的初始化阶段才会产生,因此它的大小不会影响目标文件的大小。

相关文章推荐
- C语言内存模型相关
- c语言内存模型
- 【C语言提高24】二级指针做输入的第一种内存模型:数组指针
- 【C语言提高25】二级指针做输入的第二种内存模型:二维数组
- C语言中,二级指针的三种内存模型
- 【C语言提高04】程序的内存四区模型
- 【C语言提高26】二级指针做输入的第三种内存模型:手工打造二维内存
- 【C语言提高27】二级指针三种内存模型总述
- C语言内存模型及运行时内存布局
- C语言提高之技术模型层次、学习标准、特点、内存四区、函数调用模型
- C语言内存模型与指针以及变量的关系
- c语言学习之基础知识点介绍(十):内存空间模型、地址解释及指针变量
- C语言中的内存模型
- C语言 二级指针内存模型混合实战
- 玩儿转C语言:系统内存模型之实模式和保护模式
- C语言 二级指针内存模型②
- C语言 二级指针内存模型混合实战
- C语言内存模型(内存组织方式)
- C语言 二级指针内存模型混合实战
- c语言结构体内存模型及计算(转载)