(二)线性结构之LinkedList的实现
2013-10-04 18:38
176 查看
链表结构
链式存储结构是基于指针实现的。我们把一个数据元素和一个指针称为结点。
链式存储结构是用指针把相互直接关联的结点(即直接前驱结点或直接后继结点)链接起来。链式存储结构的线性表称为链表。
链表类型
根据链表的构造方式的不同可以分为:
1.单向链表
2.单向循环链表
3.双向循环链表
单链表结构
单链表是构成链表的每个结点只有一个指向直接后继结点的指针。
单链表的表示方法:
单链表中每个结点的结构:

单链表有带头结点结构和不带头结点结构两种。我们把指向单链表的指针称为单链表的头指针。头指针所指的不存放数据元素的第一个结点称作头结点。存放第一个数据元素的结点称作第一个数据元素结点,或称首元结点。

从线性表的定义可知,线性表要求允许在任意位置进行插入和删除。当选用带头结点的单链表时,插入和删除操作的实现方法比不用带头结点单链表的实现方法简单。
设头指针用head表示,在单链表中任意结点(但不是第一个数据元素结点)前插入一个新结点的方法如图2-6所示。算法实现时,首先把插入位置定位在要插入结点的前一个结点位置,然后把s表示的新结点插入单链表中。
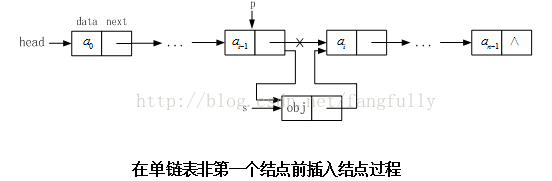
要在第一个数据元素结点前插入一个新结点,若采用不带头结点的单链表结构,则结点插入后,头指针head就要等于新插入结点s,这和在非第一个数据元素结点前插入结点时的情况不同。另外,还有一些不同情况需要考虑。因此,算法对这两种情况就要分别设计实现方法。
而如果采用带头结点的单链表结构,算法实现时,p指向头结点,改变的是p指针的next指针的值,而头指针head的值不变。因此,算法实现方法比较简单。在带头结点单链表中第一个数据元素结点前插入一个新结点的过程如图所示。
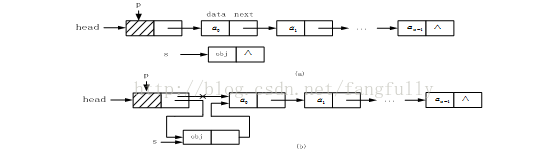
图在带头结点单链表第一个结点前插入结点过程
结点类
单链表是由一个一个结点组成的,因此,要设计单链表类,必须先设计结点类。结点类的成员变量有两个:一个是数据元素,另一个是表示下一个结点的对象引用(即指针)。
设计操作:
1.头结点的初始化
2.非头结点的构造
3.获取该结点指向的下个结点
4.设置该结点指向的下个结点
5.设置该结点的数据
6.获取该结点的数据
单链表的实现
单链表类的成员变量至少要有两个:一个是头指针,另一个是单链表中的数据元素个数。但是,如果再增加一个表示单链表当前结点位置的成员变量,则有些成员函数的设计将更加方便。
单链表的效率分析
在单链表的任何位置上插入数据元素的概率相等时,在单链表中插入一个数据元素时比较数据元素的平均次数为:
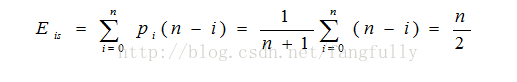
删除单链表的一个数据元素时比较数据元素的平均次数为:
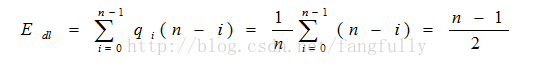
因此,单链表插入和删除操作的时间复杂度均为O(n)。另外,单链表取数据元素操作的时间复杂度也为O(n)。
顺序表和单链表的比较
顺序表的主要优点是支持随机读取,以及内存空间利用效率高;顺序表的主要缺点是需要预先给出数组的最大数据元素个数,而这通常很难准确作到。当实际的数据元素个数超过了预先给出的个数,会发生异常。另外,顺序表插入和删除操作时需要移动较多的数据元素。
和顺序表相比,单链表的主要优点是不需要预先给出数据元素的最大个数。另外,单链表插入和删除操作时不需要移动数据元素。
单链表的主要缺点是每个结点中要有一个指针,因此单链表的空间利用率略低于顺序表的。另外,单链表不支持随机读取,单链表取数据元素操作的时间复杂度为O(n);而顺序表支持随机读取,顺序表取数据元素操作的时间复杂度为O(1)。
链式存储结构是基于指针实现的。我们把一个数据元素和一个指针称为结点。
链式存储结构是用指针把相互直接关联的结点(即直接前驱结点或直接后继结点)链接起来。链式存储结构的线性表称为链表。
链表类型
根据链表的构造方式的不同可以分为:
1.单向链表
2.单向循环链表
3.双向循环链表
单链表结构
单链表是构成链表的每个结点只有一个指向直接后继结点的指针。
单链表的表示方法:
单链表中每个结点的结构:
单链表有带头结点结构和不带头结点结构两种。我们把指向单链表的指针称为单链表的头指针。头指针所指的不存放数据元素的第一个结点称作头结点。存放第一个数据元素的结点称作第一个数据元素结点,或称首元结点。
从线性表的定义可知,线性表要求允许在任意位置进行插入和删除。当选用带头结点的单链表时,插入和删除操作的实现方法比不用带头结点单链表的实现方法简单。
设头指针用head表示,在单链表中任意结点(但不是第一个数据元素结点)前插入一个新结点的方法如图2-6所示。算法实现时,首先把插入位置定位在要插入结点的前一个结点位置,然后把s表示的新结点插入单链表中。
要在第一个数据元素结点前插入一个新结点,若采用不带头结点的单链表结构,则结点插入后,头指针head就要等于新插入结点s,这和在非第一个数据元素结点前插入结点时的情况不同。另外,还有一些不同情况需要考虑。因此,算法对这两种情况就要分别设计实现方法。
而如果采用带头结点的单链表结构,算法实现时,p指向头结点,改变的是p指针的next指针的值,而头指针head的值不变。因此,算法实现方法比较简单。在带头结点单链表中第一个数据元素结点前插入一个新结点的过程如图所示。
图在带头结点单链表第一个结点前插入结点过程
结点类
单链表是由一个一个结点组成的,因此,要设计单链表类,必须先设计结点类。结点类的成员变量有两个:一个是数据元素,另一个是表示下一个结点的对象引用(即指针)。
设计操作:
1.头结点的初始化
2.非头结点的构造
3.获取该结点指向的下个结点
4.设置该结点指向的下个结点
5.设置该结点的数据
6.获取该结点的数据
//节点类
public class Node {
Object element; // 数据域
Node next; // 指针域
//头结点的构造方法
public Node(Node nextval){
this.next=nextval;
}
//非头结点的构造方法
public Node(Object obj,Node nextval){
this.element=obj;
this.next=nextval;
}
public Object getElement() {
return element;
}
public void setElement(Object element) {
this.element = element;
}
public Node getNext() {
return next;
}
public void setNext(Node next) {
this.next = next;
}
public String toString()
{
return this.element.toString();
}
}单链表的实现
单链表类的成员变量至少要有两个:一个是头指针,另一个是单链表中的数据元素个数。但是,如果再增加一个表示单链表当前结点位置的成员变量,则有些成员函数的设计将更加方便。
public interface List {
// 获得线性表长度
public int size();
// 判断线性表是否为空
public boolean isEmpty();
// 插入元素
public void add(int index, Object obj) throws Exception;
// 删除元素
public void delete(int index) throws Exception;
// 获取指定位置的元素
public Object get(int index) throws Exception;
}//单向链表
public class LinkedList implements List {
Node head; // 头指针
Node current;// 当前结点对象
int size;// 结点个数
// 初始化一个空链表
public LinkedList() {
// 初始化头结点,让头指针指向头结点。并且让当前结点对象等于头结点。
this.head = this.current = new Node(null);
this.size = 0;// 单向链表,初始长度为零。
}
// 定位函数,实现当前操作对象的前一个结点,也就是让当前结点对象定位到要操作结点的前一个结点。
public void index(int index) throws Exception {
if (index < -1 || index > this.size - 1) {
throw new Exception("参数错误!");
}
if (index == -1) {
return;
}
this.current = this.head.next;
int j = 0;
while (current != null && j < index) {
this.current = this.current.next;
j++;
}
}
@Override
public int size() {
// TODO Auto-generated method stub
return this.size;
}
@Override
public boolean isEmpty() {
// TODO Auto-generated method stub
return this.size == 0;
}
@Override
public void add(int index, Object obj) throws Exception {
// TODO Auto-generated method stub
if (index < 0 || index > this.size) {
throw new Exception("参数错误!");
}
this.index(index - 1);
this.current.setNext(new Node(obj, this.current.next));
this.size++;
}
@Override
public void delete(int index) throws Exception {
// TODO Auto-generated method stub
// 判断链表是否为空
if (isEmpty()) {
throw new Exception("链表为空,无法删除!");
}
if (index < 0 || index > size) {
throw new Exception("参数错误!");
}
this.index(index-1);
this.current.setNext(this.current.next.next);
this.size--;
}
@Override
public Object get(int index) throws Exception {
// TODO Auto-generated method stub
if(index <-1 || index >size-1)
{
throw new Exception("参数非法!");
}
this.index(index);
return this.current.getElement();
}
}单链表的效率分析
在单链表的任何位置上插入数据元素的概率相等时,在单链表中插入一个数据元素时比较数据元素的平均次数为:
删除单链表的一个数据元素时比较数据元素的平均次数为:
因此,单链表插入和删除操作的时间复杂度均为O(n)。另外,单链表取数据元素操作的时间复杂度也为O(n)。
顺序表和单链表的比较
顺序表的主要优点是支持随机读取,以及内存空间利用效率高;顺序表的主要缺点是需要预先给出数组的最大数据元素个数,而这通常很难准确作到。当实际的数据元素个数超过了预先给出的个数,会发生异常。另外,顺序表插入和删除操作时需要移动较多的数据元素。
和顺序表相比,单链表的主要优点是不需要预先给出数据元素的最大个数。另外,单链表插入和删除操作时不需要移动数据元素。
单链表的主要缺点是每个结点中要有一个指针,因此单链表的空间利用率略低于顺序表的。另外,单链表不支持随机读取,单链表取数据元素操作的时间复杂度为O(n);而顺序表支持随机读取,顺序表取数据元素操作的时间复杂度为O(1)。

相关文章推荐
- 数据结构 PAT 02-线性结构2 Reversing Linked List 单链表实现
- (二)线性结构之LinkedList的实现
- PAT 02-线性结构3 Reversing Linked List 【JAVA实现】
- C++ 02-线性结构3 Reversing Linked List
- 02-线性结构2 Reversing Linked List
- 02-线性结构1. Reversing Linked List (25)
- [数据结构]02-线性结构3 Reversing Linked List
- 数据结构之线性表之顺序表和链表(通过数据结构角度深入理解arrayList和linkedList的特性)
- 数据结构与算法---C#实现LinkedList实例
- 逆转链表-pta02-线性结构3 Reversing Linked List
- 数据结构——Doubly_Linked_List的代码实现
- java 数据结构 LinkedList的基本实现
- 02-线性结构2. Reversing Linked List (25)
- 02-线性结构3 Reversing Linked List
- 数据结构练习 02-线性结构2. Reversing Linked List (25)
- 02-线性结构2 Reversing Linked List
- 02-线性结构1. Reversing Linked List (25)
- ArrayList,List等非链式线性结构是如何实现动态增长的
- 02-线性结构2 Reversing Linked List
- Linked List实现队列的数据存储结构