实习快两个月了,发些研究成果与总结。关于覆盖测试的基本概念可以上网查阅,这里直接从研究对比开始讲吧。因为内容太多,开始之前先给个目录:
(1)覆盖测试工具的简要对比
(2)LINUX下工具GCOV的实现原理
(3)LINUX下工具GCOV的使用说明
(4) WINDOWS下工具coverage validator原理与使用说明
(5)修改GCOV适用于分布式测试覆盖率统计原理与方法
下面是部分C++ code coverage tool 的一个粗略的对比表格。这里重点研究了GCOV,COVTOOL,coverage validator,后续有时间的话,会针对旺旺重点研究下XCOVER. 有些工具没有具体研究,有兴趣的话,可以查看相应链接。
| Free orcommercial | Platform/complier | Coverage level | Show Execute counters | Easy to use | output | Useable in large | implement | others | | gcov | Free | Linux ,only gcc | Decision coverage | Yes | yes | HTML report | No | Instrument as compiling | nonsupport shared library | | COVTOOL | Free | linux | Line | boolean | no | Merge.db, ASCII report | yes | Instrument as compiling | Nonsupport thread | | xcover | Free | platform-independent library, gcc4.3+ | Line coverage | Yes | no | HTML report | ? | Source file only,denpend on stlsoft | Written in c | | GCT | Free | Unix,linux,Only for c | Branch/condition | no | yes | No HTML | yes | Instrument as compiling | Only for c,work well with if,case,for | | Coverage validator | Commercial | Windows | decision | yes | yes | HTML,XML, | yes | No recompile,With pdb file | Powerful filters,do not affect performance | | BullseyeCoverage | Commercial | Windows,unix, | Branch/condition | no | yes | Csv report,Easy to change to perl | yes | hook | Work well with vc,cppunit | | Pure coverage | Commercial | Unix,windows | decision | yes | yes | HTML,XML, | yes | Object Code Insertion | Work well with Purify |
GCOV 实现原理
1、背景介绍
GCOV是一个GNU的本地覆盖测试工具, 伴随GCC发布,配合GCC共同实现对C或者C++文件的语句覆盖和分支覆盖测试。是一个命令行方式的控制台程序。需要工具链的支持。
LCOV由 IBM 开发,由 Linux Test Project 维护的开放源代码工具。是GCOV结果展现的一个前端。这个工具由一组构建于基于文本的GCOV 输出之上的 PERL 脚本构成,以实现基于 HTML 的输出, 并生成一棵完整的 HTML 树。输出包括覆盖率百分比、图表以及概述页,可以快速浏览覆盖率数据。支持大项目,提供三种等级视图,分别为目录视图,文件视图,源代码视图。
2、GCOV分析
2.1 基本概念
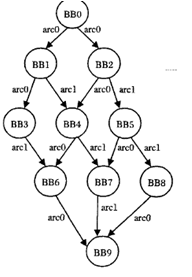
1. 基本块BB
如果一段程序的第一条语句被执行过一次,这段程序中的每一个都要执行一次,称为基本块。一个BB中的所有语句的执行次数一定是相同的。一般由多个顺序执行语句后边跟一个跳转语句组成。所以一般情况下BB的最后一条语句一定是一个跳转语句,跳转的目的地是另外一个BB的第一条语句,如果跳转时有条件的,就产生了分支,该BB就有两个BB作为目的地。
下图是个典型的基本块:
2.跳转ARC
从一个BB到另外一个BB的跳转叫做一个arc,要想知道程序中的每个语句和分支的执行次数,就必须知道每个BB和ARC的执行次数
3. 程序流图
如果把BB作为一个节点,这样一个函数中的所有BB就构成了一个有向图。,要想知道程序中的每个语句和分支的执行次数,就必须知道每个BB和ARC的执行次数。根据图论可以知道有向图中BB的入度和出度是相同的,所以只要知道了部分的BB或者arc大小,就可以推断所有的大小。
这里选择由arc的执行次数来推断BB的执行次数。
所以对部分 ARC插桩,只要满足可以统计出来所有的BB和ARC的执行次数即可。
以下是针对某个函数的程序流图:
2.2 GCOV原理与实现
2.2.1原理简介
GCOV是一个纯软件的覆盖测试工具,被测程序的预处理,插桩和编译成目标文件三个步骤由GCC一次完成。GCOV本身只负责数据处理和结果显示,下图是GCOV的工作原理。
gcov工作原理
从左图可以看出,GCOV统计覆盖率主要包括三个阶段:
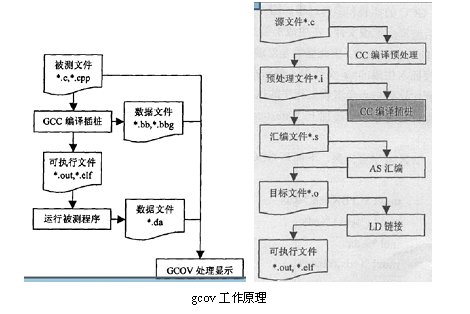
l 编译阶段:
加入编译选项gcc –o hello –fprofile-arcs –ftest-coverage hello
除了为每个C文件生成*.o目标文件以外还要生成数据文件*.bb和*.bbg(在早期的GCC版本中是包含这两个文件,后期变成*.gcno文件,但是内部仍然包含这两个文件的结构),分别记录行信息和程序流图信息,供GCOV计算覆盖率时用。
l 数据收集与提取阶段:
./hello 执行时收集数据。
被测程序运行后为每个源文件生成一个*.da数据文件,后期编译器成为.gcda文件,分别记录了*.c文件中程序的执行情况。
l 报告形成阶段:
gcov –a hello.c 收集某个源文件的覆盖率情况
执行后会生成输出文件覆盖率情况,可以重定向保存到某个文件中,同时生成hello.c.gcov形式的文件,文件格式是带有标示信息的源文件。
从右边图可以看出,GCOV的插桩时段,是在编译阶段完成:
被测程序文件首先经过编译预处理,然后编译成汇编文件,在生成汇编文件的同时完成插桩。插桩是在生成汇编文件的阶段完成的,因此插桩是汇编时候的插桩,每个桩点插入3~4条汇编语句,直接插入生成的*.s文件中,最后汇编文件汇编生成目标文件。在程序运行过程中桩点负责收集程序的执行信息。
2.2.2 覆盖率收集过程
gcov的实现源文件包括:coverge.c, gcov.c, gcov-io.c, libgcov.c, profile.c ,libgcc2.c以及他们的头文件,以下从具体的三个阶段来讨论覆盖率收集的过程。
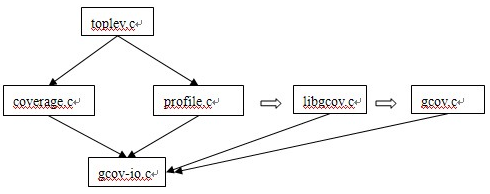
1、编译阶段
在编译阶段,当加入相应的编译选项后,由toplev.c中的函数调用coverage.c与profile.c中的函数,这些函数又调用gcov-io.c中的函数。其中coverage.c中的build_gcov_info 产生一些数据结构,并调用gcov_init 。 同时profile.c会创建程序流图,由profile.c中的函数创建的程序流图,同时gcno中的每个arc会调用insert_insn_on_edge函数来增加counter.
2、数据收集阶段
在数据收集阶段,即在程序运行时。会调用libgcov.c中的函数来增加struct gcov_info的count字段的信息,当程序退出时,gcov_exit会被调用,这个函数将收集到的数据信息写入到.gcda文件中。
3、生成报告阶段
运行($gcov 源文件)后就产生这个后缀文件。gcov要分析的话需要依赖于.gcno,.gcda,.c三个文件,记住这个分析一定要保证:.gcda产生的时候依赖的.gcno要一致,就是说我.gcda和.gcno一定要是配套的。
gcov的分析过程:(用.bbg与.bb代替.gcno来讲)
gcov读取.bbg中的程序流图信息,建立被测源文件中每个函数的程序流图
读取.gcda信息,将已知的弧执行次数填入到程序流图中
根据节点入度等于出度的原理推算出其他的弧与基本块的执行次数
读取.bb文件,根本对应关系计算出每行代码的执行次数
对应分支的话还需要计算分支的起始位置
输出计算结果
2.2.3 插桩方法
现在为止,我们知道,
Gcc编译运行产生了什么数据以及gcov分析覆盖率的过程。
还有两个问题:
a. gcc加入编译参数后,是怎么插桩的
b. 在什么位置,插入了什么数据呢?
1. 插桩过程所进行的修改
1) 每个源文件对应桩点数组:
GCC在插桩的过程中会像源文件的末尾插入一个静态数组,BX2.,数组的大小就是这个源文件中桩点的个数。
BX2+0代表第0个桩点的位置,BX2+n代表第n个桩点的位置。
数组的值就是桩点的执行次数。
2) 每个桩点插入汇编语句:
按照我的理解插入的汇编语句是inc$(BX2+n).
3) BX2数组链表:
为了便于统计,gcc还将各个源文件中的BX2数组链接成一个链表,这个链表结构是在测试main函数之前就产生了,在调用main之前会有一个类似构造函数的函数,进行构建链表。这个函数会在退出时调用exit函数计算执行次数生成.gcda文件。
2. 一些数据结构与函数功能
1) BX2数组:
每个源文件对应一个,记录每个桩点的执行次数。
2) bb结构:
因为要将各个源文件的BX2组织起来,便于统一输出,为每个源文件定义一个bb结构如下:
struct bb
{
long zero_word; //是否被插入到链表中
const char *file_name; //当前被测试文件名
long *count;//指向bx2的指针
long ncounts;//桩点个数
struct bb *next;//下一个文件的BX2信息
};
3) BX链表:
将BX2组织起来,头指针bb_head,链表元素结构为bb结构。调用void _bb_init_func(struct bb * block), 传入头指针bb_head创建。
4) 创建链表过程:void _bb_init_func(struct bb * block)
GCC为被测源文件插入了一个构造函数_GLOBAL_$I$XXXGCOV()的定义,其中XXX指当前被测文件中的第一个全局函数的函数名的生成,此函数在main函数调用之前会同构造函数一起被调用,这个全局函数的功能就是调用_bb_init_func函数,以该文件的bb结构的起始地址为参数进行调用。
该函数定义在GCC自带的库文件Libgcc.a中,源码位于gcc/libgcc2.c中,定义如下:
void _bb_init_func(struct bb * blocks)
{
if(block->zero_word)//已经连接不管
Return;
if(!bb_head)
ON_EXIT(_bb_exit_func,0);//程序退出时候,写.gcda数据
blocks->zero_word=0;
blocks->next=bb_head;//插入到链表中
bb_head=blocks;
}
该函数首先检查bb结构是否被插入到链表中,如果是则返回,接着检查bb结构的链头是否被初始化,否则注册退出时执行函数_bb_exit_func,该函数负责返回bb链中的每个结构,并生成.gcda数据文件。
这样在main函数之前,所有的bb结构都被连接成一个链表。
5)写入数据文件的过程:_bb_exit_func()
在被测程序运行完成之后,注册退出时会执行函数_bb_exit_func(),将从这个链表的头开始为每一个bb结构开始为源文件创建.gcda文件。写入的文件格式就是BX2数组内容,可以从bb结构中的BX2结构指针找到。
至此,整个插桩过程就讲完了。
|
|
