redis数据结构之压缩列表
2013-08-09 13:33
453 查看
压缩列表用于存储长度受限的字符串和整数。废话不多说,直接上redis压缩列表的内存结构示意图:

从图中可以看出,redis压缩列表由表示压缩列表占总内存的字节数的zlbytes,表示到达ziplist 表尾节点的偏移量的zltail,表示ziplist 中节点的数量的zllen,各个节点以及用于标记ziplist的末端的zlend。
注意:zllen并不是一直表示节点的数量,只有zllen小于UINT16_MAX时才是,当这个值等于UINT16_MAX时,节点的数量需要遍历整个ziplist 才能计算得出。zlend的值是固定的,也就是255.
从图中可以看出,压缩列表总是有11个字节的固定长度(4+4+2+1),而这11个字节的长度也就是压缩列表的头部与尾部,在新建一个压缩列表的时候,也就是只有这11个字节,下面来看下新建压缩列表的函数:
在讲述压缩列表插入之前,先要介绍下其余的东西。上面的图讲述了压缩列表的格式,但是并没有各个节点的格式,下面以一张图来描述下:
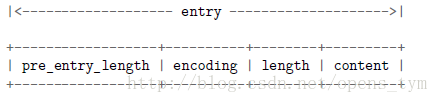
上图就描述了各个节点的格式,但是节点中域的长度并不是固定的,下面来讲述下:
pre_entry_length从字面意思就能看出来它表示前一个节点的长度,pre_entry_length可以占用1个字节也可以占用5个字节。如果前一节点的长度小于254 字节,那么只使用一个字节保存它的值。如果前一节点的长度大于等于254 字节,那么将第1 个字节的值设为254 ,然后用接下来的4 个字节保存实际长度。
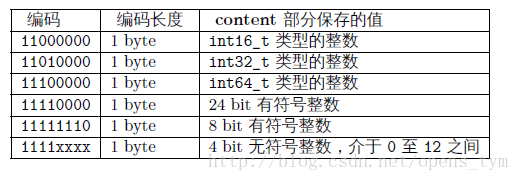
encoding可以分为四种,其中三种是为字符串准备的,最后一种就是为整数准备的。具体如下表格所示:

以上是编码字符串所用到的。下面的是编码整数的
下面结合插入数据到压缩表来讲述这些编码方式。插入数据到压缩表主要是通过ziplistInsert,这个函数会调用__ziplistInsert,而实际插入数据的也是__ziplistInsert这个函数来进行操作的。这里我只列出比较重要的一部分代码。
从图中可以看出,redis压缩列表由表示压缩列表占总内存的字节数的zlbytes,表示到达ziplist 表尾节点的偏移量的zltail,表示ziplist 中节点的数量的zllen,各个节点以及用于标记ziplist的末端的zlend。
注意:zllen并不是一直表示节点的数量,只有zllen小于UINT16_MAX时才是,当这个值等于UINT16_MAX时,节点的数量需要遍历整个ziplist 才能计算得出。zlend的值是固定的,也就是255.
从图中可以看出,压缩列表总是有11个字节的固定长度(4+4+2+1),而这11个字节的长度也就是压缩列表的头部与尾部,在新建一个压缩列表的时候,也就是只有这11个字节,下面来看下新建压缩列表的函数:
unsigned char *ziplistNew(void) {
// 分配 2 个 32 bit,一个 16 bit,以及一个 8 bit
// 分别用于 <zlbytes><zltail><zllen> 和 <zlend>
unsigned int bytes = ZIPLIST_HEADER_SIZE+1;
unsigned char *zl = zmalloc(bytes);
// 设置长度
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
// 设置表尾偏移量
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
// 设置列表项数量
ZIPLIST_LENGTH(zl) = 0;
// 设置表尾标识
zl[bytes-1] = ZIP_END;
return zl;
}而ZIPLIST_HEADER_SIZE的定义是个宏,如下:#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t))结合上面的宏可以看出ziplistNew中的bytes就是11。ziplistNew的功能也很简单就不多说了。
在讲述压缩列表插入之前,先要介绍下其余的东西。上面的图讲述了压缩列表的格式,但是并没有各个节点的格式,下面以一张图来描述下:
上图就描述了各个节点的格式,但是节点中域的长度并不是固定的,下面来讲述下:
pre_entry_length从字面意思就能看出来它表示前一个节点的长度,pre_entry_length可以占用1个字节也可以占用5个字节。如果前一节点的长度小于254 字节,那么只使用一个字节保存它的值。如果前一节点的长度大于等于254 字节,那么将第1 个字节的值设为254 ,然后用接下来的4 个字节保存实际长度。
encoding可以分为四种,其中三种是为字符串准备的,最后一种就是为整数准备的。具体如下表格所示:
以上是编码字符串所用到的。下面的是编码整数的
下面结合插入数据到压缩表来讲述这些编码方式。插入数据到压缩表主要是通过ziplistInsert,这个函数会调用__ziplistInsert,而实际插入数据的也是__ziplistInsert这个函数来进行操作的。这里我只列出比较重要的一部分代码。
static unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) {
.....
if (zipTryEncoding(s,slen,&value,&encoding)) {
/* 'encoding' is set to the appropriate integer encoding */
// s 可以保存为整数,那么继续计算保存它所需的空间
reqlen = zipIntSize(encoding);
} else {
/* 'encoding' is untouched, however zipEncodeLength will use the
* string length to figure out how to encode it. */
// 不能保存为整数,直接使用字符串长度
reqlen = slen;
}
// 计算编码 prevlen 所需的长度
reqlen += zipPrevEncodeLength(NULL,prevlen);
// 计算编码 slen 所需的长度
reqlen += zipEncodeLength(NULL,encoding,slen);
// 如果添加的位置不是表尾,那么必须确定后继节点的 prevlen 空间
// 足以保存新节点的编码长度
// zipPrevLenByteDiff 的返回值有三种可能:
// 1)新旧两个节点的编码长度相等,返回 0
// 2)新节点编码长度 > 旧节点编码长度,返回 5 - 1 = 4
// 3)旧节点编码长度 > 新编码节点长度,返回 1 - 5 = -4
nextdiff = (p[0] != ZIP_END) ? zipPrevLenByteDiff(p,reqlen) : 0;
.....
// 如果新节点不是添加到列表末端,那么它后面就有其他节点
// 因此,我们需要移动这部分节点
if (p[0] != ZIP_END) {
/* Subtract one because of the ZIP_END bytes */
// 向右移动移原有数据,为新节点让出空间
// O(N)
memmove(p+reqlen,p-nextdiff,curlen-offset-1+nextdiff);
/* Encode this entry's raw length in the next entry. */
// 将本节点的长度编码至下一节点
zipPrevEncodeLength(p+reqlen,reqlen);
/* Update offset for tail */
// 更新 ziplist 的表尾偏移量
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+reqlen);
/* When the tail contains more than one entry, we need to take
* "nextdiff" in account as well. Otherwise, a change in the
* size of prevlen doesn't have an effect on the *tail* offset. */
// 有需要的话,将 nextdiff 也加上到 zltail 上
tail = zipEntry(p+reqlen);
if (p[reqlen+tail.headersize+tail.len] != ZIP_END) {
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
}
} else {
/* This element will be the new tail. */
// 更新 ziplist 的 zltail 属性,现在新添加节点为表尾节点
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(p-zl);
}
.....
if (nextdiff != 0) {
offset = p-zl;
// O(N^2)
zl = __ziplistCascadeUpdate(zl,p+reqlen);
p = zl+offset;
}...... }代码中大部分都有注释,也比较简单,这里我要说的是if(nextdiff!=0)的情况,如果nextdiff不为0,说明新插入的数据的长度与以前这个位置的数据长度不同,而next中的pre_entry_length就需要进行改变,所以要扩展或者收缩next的大小,next大小的改变也同时需要改变next下一个节点的pre_entry_length,直到整个压缩列表全部进行更改。而上面的if语句就是做这件事的。

相关文章推荐
- Redis-数据结构-6-压缩列表
- 【Redis源码剖析】 - Redis内置数据结构之压缩列表ziplist
- Redis设计与实现系列-基本数据结构-链表和压缩列表
- redis 底层数据结构 压缩列表 ziplist
- Redis设计与实现系列-基本数据结构-链表和压缩列表
- Redis-数据结构-压缩列表-ziplist
- redis基本数据结构之压缩列表
- redis 数据结构 整数集合和压缩列表
- 【Redis源码剖析】 - Redis内置数据结构之压缩列表ziplist
- redis 底层数据结构 压缩列表 ziplist
- redis数据结构之压缩列表详解
- 详解redis数据结构之压缩列表
- Redis源码阅读笔记-压缩列表结构
- Redis数据结构和内部编码--列表(list)
- Redis源码剖析和注释(六)--- 压缩列表(ziplist)
- 图解Skip List——本质是空间换时间的数据结构,在lucene的倒排列表,bigtable,hbase,cassandra的memtable,redis中sorted set中均用到
- 【redis源码分析】压缩列表---ziplist
- Redis源码剖析--压缩列表
- redis:压缩列表
- Redis 压缩列表