基于Mongodb进行分布式数据存储
2013-07-07 13:14
477 查看
/article/4598261.html
基于Mongodb进行分布式数据存储
注:本文是研究Mongodb分布式数据存储的副产品,通过本文的相关步骤可以将一个大表中的数据分布到几个mongo服务器上。
MongoDB的1.6版本中auto-sharding功能基本稳定并可以尝试放到生产环境下使用。因为其是auto-sharding,即mongodb通过mongos(一个自动分片模块,用于构建一个大规模的可扩展的数据库集群,这个集群可以并入动态增加的机器)自动建立一个水平扩展的数据库集群系统,将数据库分表存储在sharding的各个节点上。
一个mongodb集群包括一些shards(包括一些mongod进程),mongos路由进程,一个或多个config服务器
(注:本文的测试用例需求64位的mongo程序,因为我在32位的mongo没成功过)。
下面是一些相关词汇说明:
Shards : 每一个shard包括一个或多个服务和存储数据的mongod进程(mongod是MongoDB数据的核心进程)典型的每个shard开启多个服务来提高服务的可用性。这些服务/mongod进程在shard中组成一个复制集
Chunks: Chunk是一个来自特殊集合中的一个数据范围,(collection,minKey,maxKey)描叙一个chunk,它介于minKey和maxKey范围之间。例如chunks 的maxsize大小是100M,如果一个文件达到或超过这个范围时,会被切分到2个新的chunks中。当一个shard的数据过量时,chunks将会被迁移到其他的shards上。同样,chunks也可以迁移到其他的shards上
Config Servers : Config服务器存储着集群的metadata信息,包括每个服务器,每个shard的基本信息和chunk信息Config服务器主要存储的是chunk信息。每一个config服务器都复制了完整的chunk信息。
接着看一下要配置的测试环境信息:
模拟2个shard服务和一个config服务, 均运行在10.0.4.85机器上,只是端口不同
Shard1:27020
Shard2:27021
Config:27022
Mongos启动时默认使用的27017端口
在C,D,E磁盘下分别建立如下文件夹:
mongodb\bin
mongodb\db
然后用CMD命令行依次打开相应文件夹下的mongd文件:
c:\mongodb\bin\mongod --dbpath c:\mongodb\db\ --port 27020
d:\mongodb\bin\mongod --dbpath d:\mongodb\db\ --port 27021
e:\mongodb\bin\mongod --configsvr --dbpath e:\mongodb\db\ --port 27022 (注:config配置服务器)
启动mongos时,默认开启了27017端口
e:\mongodb\bin\mongos --configdb 10.0.4.85:27022
然后打开mongo:
E:\mongodb\bin>mongo 回车 (有时加端口会造成下面的addshard命令出问题)
> use admin
switched to db admin
> db.runCommand( { addshard : "10.0.4.85:27020", allowLocal : 1, maxSize:2 , minKey:1, maxKey:10} )
--添加sharding,maxsize单位是M,此处设置比较小的数值只为演示sharding效果
{ "shardAdded" : "shard0000", "ok" : 1 }
> db.runCommand( { addshard : "10.0.4.85:27021", allowLocal : 1, minKey:1000} )
{ "shardAdded" : "shard0001", "ok" : 1 }
注:如果要移除sharding,可用下面写法
db.runCommand( { removeshard : "localhost:10000" } );
> db.runCommand({listshards:1}); 查看shard节点列表

{
"shards" : [
{
"_id" : "shard0000",
"host" : "10.0.4.85:27020"
},
{
"_id" : "shard0001",
"host" : "10.0.4.85:27021"
}
],
"ok" : 1
}
接下来创建相应数据库并设置其"可以sharding",新建自动切片的库user001:
> config = connect("10.0.4.85:27022")
> config = config.getSisterDB("config")
> dnt_mongodb=db.getSisterDB("dnt_mongodb");
dnt_mongodb
> db.runCommand({enablesharding:"dnt_mongodb"})
{ "ok" : 1 }
注:一旦enable了个数据库,mongos将会把数据库里的不同数据集放在不同的分片上。除非数据集被分片(下面会设置),否则一个数据集的所有数据将放在一个分片上。
> db.printShardingStatus();
--- Sharding Status ---
sharding version: { "_id" : 1, "version" : 3 }
shards:
{ "_id" : "shard0000", "host" : "10.0.4.85:27020" }
{ "_id" : "shard0001", "host" : "10.0.4.85:27021" }
databases:
{ "_id" : "admin", "partitioned" : false, "primary" : "config" }
{ "_id" : "dnt_mongodb", "partitioned" : true, "primary" : "shard0000" }
> db.runCommand( { shardcollection : "dnt_mongodb.posts1", key : {_id : 1}, unique: true } )
{ "collectionsharded" : "dnt_mongodb.posts1", "ok" : 1 }
--使用shardcollection 命令分隔数据集,key自动生成 [必须为唯一索引unique index]。
如果要进行GridFS sharding,则需进行如下设置:
db.runCommand( { shardcollection : "dnt_mongodb.attach_gfstream.chunks", key : { files_id : 1 } } )
{"ok" : 1} ,更多内容参见http://eshilin.blog.163.com/blog/static/13288033020106215227346/
> db.printShardingStatus()
--- Sharding Status ---
sharding version: { "_id" : 1, "version" : 3 }
shards:
{ "_id" : "shard0000", "host" : "localhost:27020" }
{ "_id" : "shard0001", "host" : "localhost:27021" }
databases:
{ "_id" : "admin", "partitioned" : false, "primary" : "config" }
{ "_id" : "user001", "partitioned" : true, "primary" : "shard0000" }
dnt_mongodb.posts1e chunks:
{ "name" : { $minKey : 1 } } -->> { "name" : { $maxKey :
1 } } on : shard0000 { "t" : 1000, "i" : 0
下面我用一个工具来批量向dnt_mongodb数据库的 posts1表中导入数据,大约是16万条数据。导入过程中mongos会显示类似如下信息:
Tue Sep 07 12:13:15 [conn14] autosplitting dnt_mongodb.posts1 size: 47273960 shard: ns:dnt_mongodb.posts1 at: shard0000:10.0.4.85:27020 lastmod: 1|0 min: { _id: MinKey } max: { _id: MaxKey } on: { _id: 19 }(splitThreshold 47185920)
Tue Sep 07 12:13:15 [conn14] config change: { _id: "4_85-2010-09-07T04:13:15-0", server: "4_85", time: new Date(1283832795994), what: "split", ns: "dnt_mongodb.posts1", details: { before: { min: { _id: MinKey }, max: { _id: MaxKey } }, left: { min: { _id: MinKey }, max: { _id: 19 } }, right: { min: { _id: 19 }, max: {_id: MaxKey } } } }
Tue Sep 07 12:13:16 [conn14] moving chunk (auto): ns:dnt_mongodb.posts1 at: shard0000:10.0.4.85:27020 lastmod: 1|1 min: { _id: MinKey } max: { _id: 19 } to: shard0001:10.0.4.85:27021 #objects: 0
Tue Sep 07 12:13:16 [conn14] moving chunk ns: dnt_mongodb.posts1 moving ( ns:dnt_mongodb.posts1 at: shard0000:10.0.4.85:27020 lastmod: 1|1 min: { _id: MinKey }max: { _id: 19 }) shard0000:10.0.4.85:27020 -> shard0001:10.0.4.85:27021
Tue Sep 07 12:13:23 [WriteBackListener] ~ScopedDBConnection: _conn != null
Tue Sep 07 12:13:23 [WriteBackListener] ERROR: splitIfShould failed: ns: dnt_mongodb.posts1 findOne has stale config
Tue Sep 07 12:13:28 [WriteBackListener] autosplitting dnt_mongodb.posts1 size: 54106804 shard: ns:dnt_mongodb.posts1 at: shard0000:10.0.4.85:27020 lastmod: 2|1min: { _id: 19 } max: { _id: MaxKey } on: { _id: 71452 }(splitThreshold 47185920)
Tue Sep 07 12:13:28 [WriteBackListener] config change: { _id: "4_85-2010-09-07T04:13:28-1", server: "4_85", time: new Date(1283832808738), what: "split", ns: "dnt_mongodb.posts1", details: { before: { min: { _id: 19 }, max: { _id: MaxKey }}, left: { min: { _id: 19 }, max: { _id: 71452 } }, right: { min: { _id: 71452 }, max: { _id: MaxKey } } } }
在完成自动sharding之后,可以使用mongo看一下结果:
> use dnt_mongodb
switched to db dnt_mongodb
> show collections
posts1
system.indexes
> db.posts1.stats()
{
"sharded" : true,
"ns" : "dnt_mongodb.posts1",
"count" : 161531,
"size" : 195882316,
"avgObjSize" : 1212.6608267143768,
"storageSize" : 231467776,
"nindexes" : 1,
"nchunks" : 5,
"shards" : {
"shard0000" : {
"ns" : "dnt_mongodb.posts1",
"count" : 62434,
"size" : 54525632,
"avgObjSize" : 873.3323509626165,
"storageSize" : 65217024,
"numExtents" : 10,
"nindexes" : 1,
"lastExtentSize" : 17394176,
"paddingFactor" : 1,
"flags" : 1,
"totalIndexSize" : 2179072,
"indexSizes" : {
"_id_" : 2179072
},
"ok" : 1
},
"shard0001" : {
"ns" : "dnt_mongodb.posts1",
"count" : 99097,
"size" : 141356684,
"avgObjSize" : 1426.4476623913943,
"storageSize" : 166250752,
"numExtents" : 12,
"nindexes" : 1,
"lastExtentSize" : 37473024,
"paddingFactor" : 1,
"flags" : 1,
"totalIndexSize" : 3424256,
"indexSizes" : {
"_id_" : 3424256
},
"ok" : 1
}
},
"ok" : 1
}
通过上面的结果,可以出现16万条记录均分在了两个sharding上,其中shard0000中有62434条,shard0001中有99097条。下面看一下这两个sharding-chunk的分布情况(图中的错误提示‘输入字符串格式不正确’主要因为运行环境与编译程序使用的环境不同,一个是64,一个是32位系统):
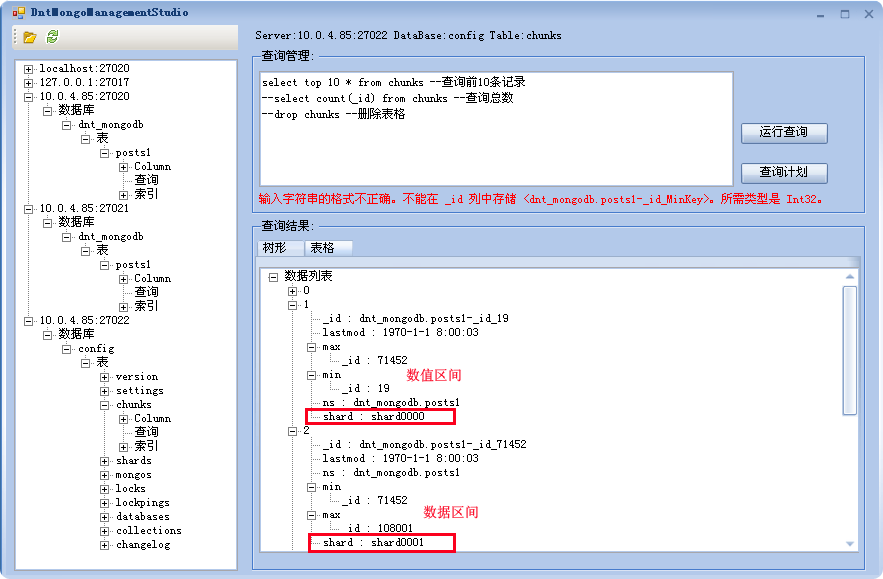
可以看到数据被按区间自动分割开了,有点像sqlserver的数据分区表,只不过这是自动完成的(目前我没找到可以手工指定区间上下限的方式,如有知道的TX可以跟我说一下)。当然在本文中的测试中,共有5个chunk,其中4个位于shard0001,这种情况可以在每次测试过程中会发生变化,包括两个sharding被分配的记录数。另外就是在mongodb移动过程前后会在shard0000上生成一个文件夹,里面包括一些bson文件,名字形如(表格+日期等信息):
post-cleanup.2010-09-07T04-13-31.1.bson
该文件主要包括一些数据库,表结构及相关记录等信息,我想应该是用于数据恢复备份啥的。
好的,今天的内容就先到这里了。
分类: MongoDB
标签: mongodb, sharding, chunks
绿色通道: 好文要顶 关注我 收藏该文与我联系


代震军
关注 - 4
粉丝 - 900
荣誉:推荐博客
+加关注
7
0
(请您对文章做出评价)
« 上一篇:发布基于silverlight4的HaoRna.WebCam摄像头应用源码
» 下一篇:基于Mongodb分布式存储物理文件
posted on 2010-09-07 13:30 代震军 阅读(9913) 评论(24) 编辑 收藏
FeedBack:
#1楼
2010-09-07 13:42 | 来客心动
请问你是如何批量导入数据的,mongodb支持批量导入吗?
你这个图像工具是哪里找的啊?开源的吗?
支持(0)反对(0)
#2楼[楼主]
2010-09-07 13:51 | 代震军
@来客心动
是为discuznt企业版数据导入时开发的。
支持(0)反对(0)
#3楼[楼主]
2010-09-07 13:52 | 代震军
mongodb目前没看到过官方的批量导入工具,呵呵。我想这类东西还是自己开发比较好。
支持(0)反对(0)
#4楼
2010-09-07 14:58 | 来客心动
即使你所谓的披露,其实还是一个document,一个documnet的写入的,对吧
还有,你把面向对象的sql,搬到nosql,有点别扭的,个人觉得
支持(0)反对(0)
#5楼
2010-09-07 15:40 | 吉日嘎拉 不仅权限管理
支持老代,老代的照片神情,跟我的照片很像,哈哈,都有点儿老啦。
支持(0)反对(0)
#6楼
2010-09-07 17:21 | 《小YY》
哎,我们的MONGODB(LINUX) 磁盘已经到了2T了
支持(0)反对(0)
#7楼
2010-09-07 17:52 | liy
还在关于用TT还是MongoDB纠结中
支持(0)反对(0)
#8楼
2010-09-07 18:01 | Allen Zhang
看了老代的文章,才知道自己了解得太少,跟本就没机会接触到mongodb这类东西。
支持(0)反对(0)
#9楼
2010-09-07 20:30 | Jeffrey Zhao
引用
liy:还在关于在TT还是MongoDB纠结中
不是一种东西,基本定一个场景后就没得选了。
支持(0)反对(0)
#10楼
2010-09-07 20:31 | Jeffrey Zhao
引用
来客心动:
还有,你把面向对象的sql,搬到nosql,有点别扭的,个人觉得
我倒觉得没什么别扭的,SQL是数据集合的查询语言,MongoDB和关系型数据库在表现形式上最大的区别也就是schmeless,即使不能绝对温和,一点基于SQL的扩展就够了,嘿嘿……
支持(0)反对(0)
#11楼
2010-09-07 22:34 | aploo.com
请教:代哥!!!
近日也在测试Mongodb,小数量20W左右时没发现问题,
但导入200W左右真实的记录时,发现在查询时慢得要吐血!
哪怕只是用主键查询一条记录也是如此。
一、Mongodb服务器环境:
Windows2003 - 64位系统
1G内存
数据量200W
Mongodb文件大小20G左右
二、客户端
NoRM客户端;
三、我自已的分析
是否由于内存太小造成?20G的文件是否要有20G的内存
才能保证快速的查询呢?看文档Mongodb好像是文档和内存映射的,
如果内存不足是否就会造查询缓慢呢?由于没哪么大的内存,没办
法测试进行验证。
如果对内存真的要求哪么高,感觉这可能是Mongodb的一个最大
的缺点!
查看过记录集的状态,大小和索引都发现正常。
不知是哪个环节有问题?向各位大哥请教了。。。。
支持(0)反对(0)
#12楼
2010-09-08 08:51 | 刘晓军
关注。。
支持(0)反对(0)
#13楼
2010-09-08 09:34 | liy
@Jeffrey Zhao
我原来的评论打错了一个字,我意思是用TT还是用MongoDB?
测试下来,发现两个没有我想像中的那么快。
选这两个的原因主要是要进行大量的检索操作。
支持(0)反对(0)
#14楼[楼主]
2010-09-08 09:44 | 代震军
@aploo.com
内存是少了一些,必定操作系统本身也会占用一些内存。
另外建议不要用NoRM客户端,我之前的测试发现他的效率和并发能力不是很高,起码比samus-mongodb-csharp要差。
另外就是查询时如果查一条记录,尽量使用findone,而不是find(document selector),因为后者可能会造成类似整表扫描的情况。
还有就是尽量使用主键(如_id,唯一索引),它的效率最高。同时对于返回集合列表的find操作,尽量少用排序之类的方法,因为即使是mongodb,排序损耗也是要严重关注的。
支持(0)反对(0)
#15楼
2010-09-08 13:00 | Jeffrey Zhao
@liy
咦?你原来说的是什么呀?好像还是TT和MongoDB嘛……你希望它们多块呀?
支持(0)反对(0)
#16楼
2010-09-08 20:04 | 曾哲
收藏
支持(0)反对(0)
#17楼
2010-09-08 21:48 | aploo.com
@代震军
谢谢。。。
关于samus-mongodb-csharp项目之前我也看过,由于他不是强类型以及他的代码写得不漂亮所以没用。。。看来光看漂亮还是不行,最重要的是稳定性和效率。。。。下面我试下看看。
谢谢大哥提醒啊。。。
支持(0)反对(0)
#18楼
2011-02-10 03:59 | Chris Cheung
hi,您好,我想请问,如果是用shard进行分布式存储,那么在代码应该里面的connection string应该连接到config server吗?
我意思是:比如有两台shard server localhost:10000,localhost:10001
config server localhost:20000
那么connection string 应该是mongodb://localhost:10000,localhost:10001
还是
mongodb://localhost:20000
谢谢
支持(0)反对(0)
#19楼
2011-04-18 18:36 | eng308
为什么32位系统不行咯? 我32位系统,按照上面操作一切正常,但就是数据不自动分配,数据全部到了一个Shard1上面。。
支持(0)反对(0)
#20楼
2011-07-21 16:59 | 寒风吹过
两个shard :shard 1和shard 2
比如说当shard 1数据到一个值或大小,则自动转到shard 2中
请问下,这个值或大小在那里可以配置呢?
支持(0)反对(0)
#21楼
2011-08-01 09:04 | xinghebuluo
@Chris Cheung
也不是config server,是mongos。
在shard环境,包含的程序有:
1. shard (mongod)
2. config server(mongod)
3. router server(mongos)
客户端应该是去router server,也就是mongos。
请参考这里:
http://www.mongodb.org/display/DOCS/Sharding+Introduction
http://www.mongodb.org/display/DOCS/Simple+Initial+Sharding+Architecture
支持(0)反对(0)
#22楼
2012-07-21 13:38 | refactor
请问有没有办法,
db.runCommand({"shardcollection":"test.refactor","key":{"name":1}})
如上:
集合"refactor",片键"name".
根据片键 "name" 的值进行分片,
如 首字母为A-F 的放在第一片上,首字母为A-F 的放在第一片上,首字母为G-M的放在第二片上,其余的放在 第三片上.
盼回复....
支持(0)反对(0)
#23楼
2012-07-24 17:29 | xinghebuluo
@refactor
应该没有办法的.
mongodb内部需要按shard key对数据已经平衡,达到数据在shard集群中均匀分布.
按照你的想法,就违背了数据均衡分布的初衷了。
你可能需要用其他的shard key了。
支持(0)反对(0)
#24楼
2012-10-18 14:24 | 规格严格-功夫到家
应该可以自己定义均衡策略吧?
支持(0)反对(0)
基于Mongodb进行分布式数据存储
注:本文是研究Mongodb分布式数据存储的副产品,通过本文的相关步骤可以将一个大表中的数据分布到几个mongo服务器上。
MongoDB的1.6版本中auto-sharding功能基本稳定并可以尝试放到生产环境下使用。因为其是auto-sharding,即mongodb通过mongos(一个自动分片模块,用于构建一个大规模的可扩展的数据库集群,这个集群可以并入动态增加的机器)自动建立一个水平扩展的数据库集群系统,将数据库分表存储在sharding的各个节点上。
一个mongodb集群包括一些shards(包括一些mongod进程),mongos路由进程,一个或多个config服务器
(注:本文的测试用例需求64位的mongo程序,因为我在32位的mongo没成功过)。
下面是一些相关词汇说明:
Shards : 每一个shard包括一个或多个服务和存储数据的mongod进程(mongod是MongoDB数据的核心进程)典型的每个shard开启多个服务来提高服务的可用性。这些服务/mongod进程在shard中组成一个复制集
Chunks: Chunk是一个来自特殊集合中的一个数据范围,(collection,minKey,maxKey)描叙一个chunk,它介于minKey和maxKey范围之间。例如chunks 的maxsize大小是100M,如果一个文件达到或超过这个范围时,会被切分到2个新的chunks中。当一个shard的数据过量时,chunks将会被迁移到其他的shards上。同样,chunks也可以迁移到其他的shards上
Config Servers : Config服务器存储着集群的metadata信息,包括每个服务器,每个shard的基本信息和chunk信息Config服务器主要存储的是chunk信息。每一个config服务器都复制了完整的chunk信息。
接着看一下要配置的测试环境信息:
模拟2个shard服务和一个config服务, 均运行在10.0.4.85机器上,只是端口不同
Shard1:27020
Shard2:27021
Config:27022
Mongos启动时默认使用的27017端口
在C,D,E磁盘下分别建立如下文件夹:
mongodb\bin
mongodb\db
然后用CMD命令行依次打开相应文件夹下的mongd文件:
c:\mongodb\bin\mongod --dbpath c:\mongodb\db\ --port 27020
d:\mongodb\bin\mongod --dbpath d:\mongodb\db\ --port 27021
e:\mongodb\bin\mongod --configsvr --dbpath e:\mongodb\db\ --port 27022 (注:config配置服务器)
启动mongos时,默认开启了27017端口
e:\mongodb\bin\mongos --configdb 10.0.4.85:27022
然后打开mongo:
E:\mongodb\bin>mongo 回车 (有时加端口会造成下面的addshard命令出问题)
> use admin
switched to db admin
> db.runCommand( { addshard : "10.0.4.85:27020", allowLocal : 1, maxSize:2 , minKey:1, maxKey:10} )
--添加sharding,maxsize单位是M,此处设置比较小的数值只为演示sharding效果
{ "shardAdded" : "shard0000", "ok" : 1 }
> db.runCommand( { addshard : "10.0.4.85:27021", allowLocal : 1, minKey:1000} )
{ "shardAdded" : "shard0001", "ok" : 1 }
注:如果要移除sharding,可用下面写法
db.runCommand( { removeshard : "localhost:10000" } );
> db.runCommand({listshards:1}); 查看shard节点列表
{
"shards" : [
{
"_id" : "shard0000",
"host" : "10.0.4.85:27020"
},
{
"_id" : "shard0001",
"host" : "10.0.4.85:27021"
}
],
"ok" : 1
}
接下来创建相应数据库并设置其"可以sharding",新建自动切片的库user001:
> config = connect("10.0.4.85:27022")
> config = config.getSisterDB("config")
> dnt_mongodb=db.getSisterDB("dnt_mongodb");
dnt_mongodb
> db.runCommand({enablesharding:"dnt_mongodb"})
{ "ok" : 1 }
注:一旦enable了个数据库,mongos将会把数据库里的不同数据集放在不同的分片上。除非数据集被分片(下面会设置),否则一个数据集的所有数据将放在一个分片上。
> db.printShardingStatus();
--- Sharding Status ---
sharding version: { "_id" : 1, "version" : 3 }
shards:
{ "_id" : "shard0000", "host" : "10.0.4.85:27020" }
{ "_id" : "shard0001", "host" : "10.0.4.85:27021" }
databases:
{ "_id" : "admin", "partitioned" : false, "primary" : "config" }
{ "_id" : "dnt_mongodb", "partitioned" : true, "primary" : "shard0000" }
> db.runCommand( { shardcollection : "dnt_mongodb.posts1", key : {_id : 1}, unique: true } )
{ "collectionsharded" : "dnt_mongodb.posts1", "ok" : 1 }
--使用shardcollection 命令分隔数据集,key自动生成 [必须为唯一索引unique index]。
如果要进行GridFS sharding,则需进行如下设置:
db.runCommand( { shardcollection : "dnt_mongodb.attach_gfstream.chunks", key : { files_id : 1 } } )
{"ok" : 1} ,更多内容参见http://eshilin.blog.163.com/blog/static/13288033020106215227346/
> db.printShardingStatus()
--- Sharding Status ---
sharding version: { "_id" : 1, "version" : 3 }
shards:
{ "_id" : "shard0000", "host" : "localhost:27020" }
{ "_id" : "shard0001", "host" : "localhost:27021" }
databases:
{ "_id" : "admin", "partitioned" : false, "primary" : "config" }
{ "_id" : "user001", "partitioned" : true, "primary" : "shard0000" }
dnt_mongodb.posts1e chunks:
{ "name" : { $minKey : 1 } } -->> { "name" : { $maxKey :
1 } } on : shard0000 { "t" : 1000, "i" : 0
下面我用一个工具来批量向dnt_mongodb数据库的 posts1表中导入数据,大约是16万条数据。导入过程中mongos会显示类似如下信息:
Tue Sep 07 12:13:15 [conn14] autosplitting dnt_mongodb.posts1 size: 47273960 shard: ns:dnt_mongodb.posts1 at: shard0000:10.0.4.85:27020 lastmod: 1|0 min: { _id: MinKey } max: { _id: MaxKey } on: { _id: 19 }(splitThreshold 47185920)
Tue Sep 07 12:13:15 [conn14] config change: { _id: "4_85-2010-09-07T04:13:15-0", server: "4_85", time: new Date(1283832795994), what: "split", ns: "dnt_mongodb.posts1", details: { before: { min: { _id: MinKey }, max: { _id: MaxKey } }, left: { min: { _id: MinKey }, max: { _id: 19 } }, right: { min: { _id: 19 }, max: {_id: MaxKey } } } }
Tue Sep 07 12:13:16 [conn14] moving chunk (auto): ns:dnt_mongodb.posts1 at: shard0000:10.0.4.85:27020 lastmod: 1|1 min: { _id: MinKey } max: { _id: 19 } to: shard0001:10.0.4.85:27021 #objects: 0
Tue Sep 07 12:13:16 [conn14] moving chunk ns: dnt_mongodb.posts1 moving ( ns:dnt_mongodb.posts1 at: shard0000:10.0.4.85:27020 lastmod: 1|1 min: { _id: MinKey }max: { _id: 19 }) shard0000:10.0.4.85:27020 -> shard0001:10.0.4.85:27021
Tue Sep 07 12:13:23 [WriteBackListener] ~ScopedDBConnection: _conn != null
Tue Sep 07 12:13:23 [WriteBackListener] ERROR: splitIfShould failed: ns: dnt_mongodb.posts1 findOne has stale config
Tue Sep 07 12:13:28 [WriteBackListener] autosplitting dnt_mongodb.posts1 size: 54106804 shard: ns:dnt_mongodb.posts1 at: shard0000:10.0.4.85:27020 lastmod: 2|1min: { _id: 19 } max: { _id: MaxKey } on: { _id: 71452 }(splitThreshold 47185920)
Tue Sep 07 12:13:28 [WriteBackListener] config change: { _id: "4_85-2010-09-07T04:13:28-1", server: "4_85", time: new Date(1283832808738), what: "split", ns: "dnt_mongodb.posts1", details: { before: { min: { _id: 19 }, max: { _id: MaxKey }}, left: { min: { _id: 19 }, max: { _id: 71452 } }, right: { min: { _id: 71452 }, max: { _id: MaxKey } } } }
在完成自动sharding之后,可以使用mongo看一下结果:
> use dnt_mongodb
switched to db dnt_mongodb
> show collections
posts1
system.indexes
> db.posts1.stats()
{
"sharded" : true,
"ns" : "dnt_mongodb.posts1",
"count" : 161531,
"size" : 195882316,
"avgObjSize" : 1212.6608267143768,
"storageSize" : 231467776,
"nindexes" : 1,
"nchunks" : 5,
"shards" : {
"shard0000" : {
"ns" : "dnt_mongodb.posts1",
"count" : 62434,
"size" : 54525632,
"avgObjSize" : 873.3323509626165,
"storageSize" : 65217024,
"numExtents" : 10,
"nindexes" : 1,
"lastExtentSize" : 17394176,
"paddingFactor" : 1,
"flags" : 1,
"totalIndexSize" : 2179072,
"indexSizes" : {
"_id_" : 2179072
},
"ok" : 1
},
"shard0001" : {
"ns" : "dnt_mongodb.posts1",
"count" : 99097,
"size" : 141356684,
"avgObjSize" : 1426.4476623913943,
"storageSize" : 166250752,
"numExtents" : 12,
"nindexes" : 1,
"lastExtentSize" : 37473024,
"paddingFactor" : 1,
"flags" : 1,
"totalIndexSize" : 3424256,
"indexSizes" : {
"_id_" : 3424256
},
"ok" : 1
}
},
"ok" : 1
}
通过上面的结果,可以出现16万条记录均分在了两个sharding上,其中shard0000中有62434条,shard0001中有99097条。下面看一下这两个sharding-chunk的分布情况(图中的错误提示‘输入字符串格式不正确’主要因为运行环境与编译程序使用的环境不同,一个是64,一个是32位系统):
可以看到数据被按区间自动分割开了,有点像sqlserver的数据分区表,只不过这是自动完成的(目前我没找到可以手工指定区间上下限的方式,如有知道的TX可以跟我说一下)。当然在本文中的测试中,共有5个chunk,其中4个位于shard0001,这种情况可以在每次测试过程中会发生变化,包括两个sharding被分配的记录数。另外就是在mongodb移动过程前后会在shard0000上生成一个文件夹,里面包括一些bson文件,名字形如(表格+日期等信息):
post-cleanup.2010-09-07T04-13-31.1.bson
该文件主要包括一些数据库,表结构及相关记录等信息,我想应该是用于数据恢复备份啥的。
好的,今天的内容就先到这里了。
分类: MongoDB
标签: mongodb, sharding, chunks
绿色通道: 好文要顶 关注我 收藏该文与我联系
代震军
关注 - 4
粉丝 - 900
荣誉:推荐博客
+加关注
7
0
(请您对文章做出评价)
« 上一篇:发布基于silverlight4的HaoRna.WebCam摄像头应用源码
» 下一篇:基于Mongodb分布式存储物理文件
posted on 2010-09-07 13:30 代震军 阅读(9913) 评论(24) 编辑 收藏
FeedBack:
#1楼
2010-09-07 13:42 | 来客心动
请问你是如何批量导入数据的,mongodb支持批量导入吗?
你这个图像工具是哪里找的啊?开源的吗?
支持(0)反对(0)
#2楼[楼主]
2010-09-07 13:51 | 代震军
@来客心动
是为discuznt企业版数据导入时开发的。
支持(0)反对(0)
#3楼[楼主]
2010-09-07 13:52 | 代震军
mongodb目前没看到过官方的批量导入工具,呵呵。我想这类东西还是自己开发比较好。
支持(0)反对(0)
#4楼
2010-09-07 14:58 | 来客心动
即使你所谓的披露,其实还是一个document,一个documnet的写入的,对吧
还有,你把面向对象的sql,搬到nosql,有点别扭的,个人觉得
支持(0)反对(0)
#5楼
2010-09-07 15:40 | 吉日嘎拉 不仅权限管理
支持老代,老代的照片神情,跟我的照片很像,哈哈,都有点儿老啦。
支持(0)反对(0)
#6楼
2010-09-07 17:21 | 《小YY》
哎,我们的MONGODB(LINUX) 磁盘已经到了2T了
支持(0)反对(0)
#7楼
2010-09-07 17:52 | liy
还在关于用TT还是MongoDB纠结中
支持(0)反对(0)
#8楼
2010-09-07 18:01 | Allen Zhang
看了老代的文章,才知道自己了解得太少,跟本就没机会接触到mongodb这类东西。
支持(0)反对(0)
#9楼
2010-09-07 20:30 | Jeffrey Zhao
引用
liy:还在关于在TT还是MongoDB纠结中
不是一种东西,基本定一个场景后就没得选了。
支持(0)反对(0)
#10楼
2010-09-07 20:31 | Jeffrey Zhao
引用
来客心动:
还有,你把面向对象的sql,搬到nosql,有点别扭的,个人觉得
我倒觉得没什么别扭的,SQL是数据集合的查询语言,MongoDB和关系型数据库在表现形式上最大的区别也就是schmeless,即使不能绝对温和,一点基于SQL的扩展就够了,嘿嘿……
支持(0)反对(0)
#11楼
2010-09-07 22:34 | aploo.com
请教:代哥!!!
近日也在测试Mongodb,小数量20W左右时没发现问题,
但导入200W左右真实的记录时,发现在查询时慢得要吐血!
哪怕只是用主键查询一条记录也是如此。
一、Mongodb服务器环境:
Windows2003 - 64位系统
1G内存
数据量200W
Mongodb文件大小20G左右
二、客户端
NoRM客户端;
三、我自已的分析
是否由于内存太小造成?20G的文件是否要有20G的内存
才能保证快速的查询呢?看文档Mongodb好像是文档和内存映射的,
如果内存不足是否就会造查询缓慢呢?由于没哪么大的内存,没办
法测试进行验证。
如果对内存真的要求哪么高,感觉这可能是Mongodb的一个最大
的缺点!
查看过记录集的状态,大小和索引都发现正常。
不知是哪个环节有问题?向各位大哥请教了。。。。
支持(0)反对(0)
#12楼
2010-09-08 08:51 | 刘晓军
关注。。
支持(0)反对(0)
#13楼
2010-09-08 09:34 | liy
@Jeffrey Zhao
我原来的评论打错了一个字,我意思是用TT还是用MongoDB?
测试下来,发现两个没有我想像中的那么快。
选这两个的原因主要是要进行大量的检索操作。
支持(0)反对(0)
#14楼[楼主]
2010-09-08 09:44 | 代震军
@aploo.com
内存是少了一些,必定操作系统本身也会占用一些内存。
另外建议不要用NoRM客户端,我之前的测试发现他的效率和并发能力不是很高,起码比samus-mongodb-csharp要差。
另外就是查询时如果查一条记录,尽量使用findone,而不是find(document selector),因为后者可能会造成类似整表扫描的情况。
还有就是尽量使用主键(如_id,唯一索引),它的效率最高。同时对于返回集合列表的find操作,尽量少用排序之类的方法,因为即使是mongodb,排序损耗也是要严重关注的。
支持(0)反对(0)
#15楼
2010-09-08 13:00 | Jeffrey Zhao
@liy
咦?你原来说的是什么呀?好像还是TT和MongoDB嘛……你希望它们多块呀?
支持(0)反对(0)
#16楼
2010-09-08 20:04 | 曾哲
收藏
支持(0)反对(0)
#17楼
2010-09-08 21:48 | aploo.com
@代震军
谢谢。。。
关于samus-mongodb-csharp项目之前我也看过,由于他不是强类型以及他的代码写得不漂亮所以没用。。。看来光看漂亮还是不行,最重要的是稳定性和效率。。。。下面我试下看看。
谢谢大哥提醒啊。。。
支持(0)反对(0)
#18楼
2011-02-10 03:59 | Chris Cheung
hi,您好,我想请问,如果是用shard进行分布式存储,那么在代码应该里面的connection string应该连接到config server吗?
我意思是:比如有两台shard server localhost:10000,localhost:10001
config server localhost:20000
那么connection string 应该是mongodb://localhost:10000,localhost:10001
还是
mongodb://localhost:20000
谢谢
支持(0)反对(0)
#19楼
2011-04-18 18:36 | eng308
为什么32位系统不行咯? 我32位系统,按照上面操作一切正常,但就是数据不自动分配,数据全部到了一个Shard1上面。。
支持(0)反对(0)
#20楼
2011-07-21 16:59 | 寒风吹过
两个shard :shard 1和shard 2
比如说当shard 1数据到一个值或大小,则自动转到shard 2中
请问下,这个值或大小在那里可以配置呢?
支持(0)反对(0)
#21楼
2011-08-01 09:04 | xinghebuluo
@Chris Cheung
也不是config server,是mongos。
在shard环境,包含的程序有:
1. shard (mongod)
2. config server(mongod)
3. router server(mongos)
客户端应该是去router server,也就是mongos。
请参考这里:
http://www.mongodb.org/display/DOCS/Sharding+Introduction
http://www.mongodb.org/display/DOCS/Simple+Initial+Sharding+Architecture
支持(0)反对(0)
#22楼
2012-07-21 13:38 | refactor
请问有没有办法,
db.runCommand({"shardcollection":"test.refactor","key":{"name":1}})
如上:
集合"refactor",片键"name".
根据片键 "name" 的值进行分片,
如 首字母为A-F 的放在第一片上,首字母为A-F 的放在第一片上,首字母为G-M的放在第二片上,其余的放在 第三片上.
盼回复....
支持(0)反对(0)
#23楼
2012-07-24 17:29 | xinghebuluo
@refactor
应该没有办法的.
mongodb内部需要按shard key对数据已经平衡,达到数据在shard集群中均匀分布.
按照你的想法,就违背了数据均衡分布的初衷了。
你可能需要用其他的shard key了。
支持(0)反对(0)
#24楼
2012-10-18 14:24 | 规格严格-功夫到家
应该可以自己定义均衡策略吧?
支持(0)反对(0)

相关文章推荐
- 基于Mongodb进行分布式数据存储(转)
- 基于Mongodb进行分布式数据存储
- 基于Mongodb进行分布式数据存储
- 基于Mongodb进行分布式数据存储
- 基于Mongodb进行分布式数据存储
- 基于Mongodb进行分布式数据存储
- 基于Mongodb进行分布式数据存储
- 基于MongoDB进行分布式数据存储的步骤
- 基于分布式文件存储的数据库---MongoDB
- GridFS:基于MongoDB的分布式文件存储系统
- 使用Mongodb存储上传物理文件并进行SQUID加速(基于aspx页面)
- 基于mongoDB和C#分布式海量文件存储实验
- 使用Mongodb存储上传物理文件并进行SQUID加速(基于aspx页面)
- 使用Mongodb存储上传物理文件并进行SQUID加速(基于aspx页面)
- 基于云上分布式NoSQL的海量气象数据存储和查询方案
- MongoDB 基于分布式文件存储的数据库
- GridFS:基于MongoDB的分布式文件存储系统
- MongoDB一个基于分布式文件存储的数据库(介于关系数据库和非关系数据库之间的数据库)
- 基于Mongodb进行分布式数据存储【转】
- GridFS:基于MongoDB的分布式文件存储系统