linux系统编程之基础必备(七):read/write函数与(非)阻塞I/O的概念
2013-05-20 16:40
453 查看
一、read/write 函数
read函数从打开的设备或文件中读取数据。
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);
返回值:成功返回读取的字节数,出错返回-1并设置errno,如果在调read之前已到达文件末尾,则这次read返回0
参数count是请求读取的字节数,读上来的数据保存在缓冲区buf中,同时文件的当前读写位置向后移。注意这个读写位置和使用C标准I/O库时的读写位置有可能不同,这个读写位置是记在内核中的,而使用C标准I/O库时的读写位置是用户空间I/O缓冲区中的位置。比如用fgetc读一个字节,fgetc有可能从内核中预读1024个字节到I/O缓冲区中,再返回第一个字节,这时该文件在内核中记录的读写位置是1024,而在FILE结构体中记录的读写位置是1。注意返回值类型是ssize_t,表示有符号的size_t,这样既可以返回正的字节数、0(表示到达文件末尾)也可以返回负值-1(表示出错)。read函数返回时,返回值说明了buf中前多少个字节是刚读上来的。有些情况下,实际读到的字节数(返回值)会小于请求读的字节数count,例如:
1、读常规文件时,在读到count个字节之前已到达文件末尾。例如,距文件末尾还有30个字节而请求读100个字节,则read返回30,下次read将返回0。
2、从终端设备读,通常以行为单位,读到换行符就返回了。
3、从网络读,根据不同的传输层协议和内核缓存机制,返回值可能小于请求的字节数。
write函数向打开的设备或文件中写数据。
#include <unistd.h>
ssize_t write(int fd, const void *buf, size_t count);
返回值:成功返回写入的字节数,出错返回-1并设置errno
写常规文件时,write的返回值通常等于请求写的字节数count,而向终端设备或网络写则不一定。
读常规文件是不会阻塞的,不管读多少字节,read一定会在有限的时间内返回。从终端设备或网络读则不一定,如果从终端输入的数据没有换行符,调用read读终端设备就会阻塞,如果网络上没有接收到数据包,调用read从网络读就会阻塞,至于会阻塞多长时间也是不确定的,如果一直没有数据到达就一直阻塞在那里。同样,写常规文件是不会阻塞的,而向终端设备或网络写则不一定。
二、(非)阻塞I/O的概念
现在明确一下阻塞(Block)这个概念。当进程调用一个阻塞的系统函数时,该进程被置于睡眠(Sleep)状态,这时内核调度其它进程运行,直到该进程等待的事件发生了(比如网络上接收到数据包,或者调用sleep指定的睡眠时间到了)它才有可能继续运行。与睡眠状态相对的是运行(Running)状态,在Linux内核中,处于运行状态的进程分为两种情况:
1、正在被调度执行。CPU处于该进程的上下文环境中,程序计数器(eip)里保存着该进程的指令地址,通用寄存器里保存着该进程运算过程的中间结果,正在执行该进程的指令,正在读写该进程的地址空间。
2、就绪状态。该进程不需要等待什么事件发生,随时都可以执行,但CPU暂时还在执行另一个进程,所以该进程在一个就绪队列中等待被内核调度。系统中可能同时有多个就绪的进程,那么该调度谁执行呢?内核的调度算法是基于优先级和时间片的,而且会根据每个进程的运行情况动态调整它的优先级和时间片,让每个进程都能比较公平地得到机会执行,同时要兼顾用户体验,不能让和用户交互的进程响应太慢。
如果在open一个设备时指定了O_NONBLOCK标志,read/write就不会阻塞。以read为例,如果设备暂时没有数据可读就返回-1,同时置errno为EWOULDBLOCK(或者EAGAIN,这两个宏定义的值相同),表示本来应该阻塞在这里(would block,虚拟语气),事实上并没有阻塞而是直接返回错误,调用者应该试着再读一次(again)。这种行为方式称为轮询(Poll),调用者只是查询一下,而不是阻塞在这里死等,这样可以同时监视多个设备:
while(1)
{
非阻塞read(设备1);
if(设备1有数据到达)
处理数据;
非阻塞read(设备2);
if(设备2有数据到达)
处理数据;
..............................
}
如果read(设备1)是阻塞的,那么只要设备1没有数据到达就会一直阻塞在设备1的read调用上,即使设备2有数据到达也不能处理,使用非阻塞I/O就可以避免设备2得不到及时处理。
非阻塞I/O有一个缺点,如果所有设备都一直没有数据到达,调用者需要反复查询做无用功,如果阻塞在那里,操作系统可以调度别的进程执行,就不会做无用功了。在使用非阻塞I/O时,通常不会在一个while循环中一直不停地查询(这称为Tight Loop),而是每延迟等待一会儿来查询一下,以免做太多无用功,在延迟等待的时候可以调度其它进程执行。
while(1)
{
非阻塞read(设备1);
if(设备1有数据到达)
处理数据;
非阻塞read(设备2);
if(设备2有数据到达)
处理数据;
..............................
sleep(n);
}
这样做的问题是,设备1有数据到达时可能不能及时处理,最长需延迟n秒才能处理,而且反复查询还是做了很多无用功。而select/poll/epoll 等函数可以阻塞地同时监视多个设备,还可以设定阻塞等待的超时时间,从而圆满地解决了这个问题。
三、整个write过程
http://blog.chinaunix.net/uid-27105712-id-3270102.html
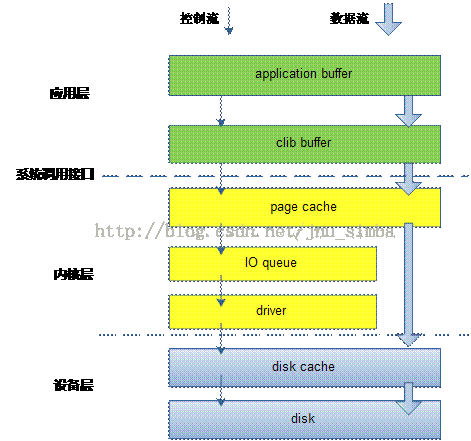
下面是整个write过程
glibc write是将app_buffer->libc_buffer->page_cache
write是将app_buffer->page_cache
mmap可以直接获取page_cache直写
write+O_DIRECT的话将app_buffer写到io_queue里面
io_queue一方面将写邻近扇区的内容进行merge,另外一方面进行排序确保磁头和磁 盘旋转最少。
io_queue的工作也需要结合IO调度算法。不过这些仅仅对于physical disk有效。
对于ssd而言的话,因为完全是随机写,基本没有调度算法。
driver(filesystem module)通过DMA写入disk_cache之后(使用fsync就可以强制刷新)到disk上面了。
直接操作设备(RAW)方式直接写disk_cache.
O_DIRECT 和 RAW设备最根本的区别是O_DIRECT是基于文件系统的,也就是在应用层来看,其操作对象是文件句柄,内核和文件层来看,其操作是基于inode和数据块,这些概念都是和ext2/3的文件系统相关,写到磁盘上最终是ext3文件。而RAW设备写是没有文件系统概念,操作的是扇区号,操作对象是扇区,写出来的东西不一定是ext3文件(如果按照ext3规则写就是ext3文件)。一般基于O_DIRECT来设计优化自己的文件模块,是不满系统的cache和调度策略,自己在应用层实现这些,来制定自己特有的业务特色文件读写。但是写出来的东西是ext3文件,该磁盘卸下来,mount到其他任何linux系统上,都可以查看。而基于RAW设备的设计系统,一般是不满现有ext3的诸多缺陷,设计自己的文件系统。自己设计文件布局和索引方式。举个极端例子:把整个磁盘做一个文件来写,不要索引。这样没有inode限制,没有文件大小限制,磁盘有多大,文件就能多大。这样的磁盘卸下来,mount到其他linux系统上,是无法识别其数据的。两者都要通过驱动层读写;在系统引导启动,还处于实模式的时候,可以通过bios接口读写raw设备。
操作系统为了提高文件读写效率,在内核层提供了读写缓冲区。对于磁盘的写并不是立刻写入磁盘, 而是首先写入页面缓冲区然后定时刷到硬盘上。但是这种机制降低了文件更新速度,并且如果系统发生故障 的话,那么会造成部分数据丢失。这里的3个sync函数就是为了这个问题的。
sync.是强制将所有页面缓冲区都更新到磁盘上。
fsync.是强制将某个fd涉及到的页面缓存更新到磁盘上(包括文件属性等信息).
fdatasync.是强制将某个fd涉及到的数据页面缓存更新到磁盘上。
参考:《linux c 编程一站式学习》
http://dirlt.com/apue.html
read函数从打开的设备或文件中读取数据。
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);
返回值:成功返回读取的字节数,出错返回-1并设置errno,如果在调read之前已到达文件末尾,则这次read返回0
参数count是请求读取的字节数,读上来的数据保存在缓冲区buf中,同时文件的当前读写位置向后移。注意这个读写位置和使用C标准I/O库时的读写位置有可能不同,这个读写位置是记在内核中的,而使用C标准I/O库时的读写位置是用户空间I/O缓冲区中的位置。比如用fgetc读一个字节,fgetc有可能从内核中预读1024个字节到I/O缓冲区中,再返回第一个字节,这时该文件在内核中记录的读写位置是1024,而在FILE结构体中记录的读写位置是1。注意返回值类型是ssize_t,表示有符号的size_t,这样既可以返回正的字节数、0(表示到达文件末尾)也可以返回负值-1(表示出错)。read函数返回时,返回值说明了buf中前多少个字节是刚读上来的。有些情况下,实际读到的字节数(返回值)会小于请求读的字节数count,例如:
1、读常规文件时,在读到count个字节之前已到达文件末尾。例如,距文件末尾还有30个字节而请求读100个字节,则read返回30,下次read将返回0。
2、从终端设备读,通常以行为单位,读到换行符就返回了。
3、从网络读,根据不同的传输层协议和内核缓存机制,返回值可能小于请求的字节数。
write函数向打开的设备或文件中写数据。
#include <unistd.h>
ssize_t write(int fd, const void *buf, size_t count);
返回值:成功返回写入的字节数,出错返回-1并设置errno
写常规文件时,write的返回值通常等于请求写的字节数count,而向终端设备或网络写则不一定。
读常规文件是不会阻塞的,不管读多少字节,read一定会在有限的时间内返回。从终端设备或网络读则不一定,如果从终端输入的数据没有换行符,调用read读终端设备就会阻塞,如果网络上没有接收到数据包,调用read从网络读就会阻塞,至于会阻塞多长时间也是不确定的,如果一直没有数据到达就一直阻塞在那里。同样,写常规文件是不会阻塞的,而向终端设备或网络写则不一定。
二、(非)阻塞I/O的概念
现在明确一下阻塞(Block)这个概念。当进程调用一个阻塞的系统函数时,该进程被置于睡眠(Sleep)状态,这时内核调度其它进程运行,直到该进程等待的事件发生了(比如网络上接收到数据包,或者调用sleep指定的睡眠时间到了)它才有可能继续运行。与睡眠状态相对的是运行(Running)状态,在Linux内核中,处于运行状态的进程分为两种情况:
1、正在被调度执行。CPU处于该进程的上下文环境中,程序计数器(eip)里保存着该进程的指令地址,通用寄存器里保存着该进程运算过程的中间结果,正在执行该进程的指令,正在读写该进程的地址空间。
2、就绪状态。该进程不需要等待什么事件发生,随时都可以执行,但CPU暂时还在执行另一个进程,所以该进程在一个就绪队列中等待被内核调度。系统中可能同时有多个就绪的进程,那么该调度谁执行呢?内核的调度算法是基于优先级和时间片的,而且会根据每个进程的运行情况动态调整它的优先级和时间片,让每个进程都能比较公平地得到机会执行,同时要兼顾用户体验,不能让和用户交互的进程响应太慢。
如果在open一个设备时指定了O_NONBLOCK标志,read/write就不会阻塞。以read为例,如果设备暂时没有数据可读就返回-1,同时置errno为EWOULDBLOCK(或者EAGAIN,这两个宏定义的值相同),表示本来应该阻塞在这里(would block,虚拟语气),事实上并没有阻塞而是直接返回错误,调用者应该试着再读一次(again)。这种行为方式称为轮询(Poll),调用者只是查询一下,而不是阻塞在这里死等,这样可以同时监视多个设备:
while(1)
{
非阻塞read(设备1);
if(设备1有数据到达)
处理数据;
非阻塞read(设备2);
if(设备2有数据到达)
处理数据;
..............................
}
如果read(设备1)是阻塞的,那么只要设备1没有数据到达就会一直阻塞在设备1的read调用上,即使设备2有数据到达也不能处理,使用非阻塞I/O就可以避免设备2得不到及时处理。
非阻塞I/O有一个缺点,如果所有设备都一直没有数据到达,调用者需要反复查询做无用功,如果阻塞在那里,操作系统可以调度别的进程执行,就不会做无用功了。在使用非阻塞I/O时,通常不会在一个while循环中一直不停地查询(这称为Tight Loop),而是每延迟等待一会儿来查询一下,以免做太多无用功,在延迟等待的时候可以调度其它进程执行。
while(1)
{
非阻塞read(设备1);
if(设备1有数据到达)
处理数据;
非阻塞read(设备2);
if(设备2有数据到达)
处理数据;
..............................
sleep(n);
}
这样做的问题是,设备1有数据到达时可能不能及时处理,最长需延迟n秒才能处理,而且反复查询还是做了很多无用功。而select/poll/epoll 等函数可以阻塞地同时监视多个设备,还可以设定阻塞等待的超时时间,从而圆满地解决了这个问题。
三、整个write过程
http://blog.chinaunix.net/uid-27105712-id-3270102.html
下面是整个write过程
glibc write是将app_buffer->libc_buffer->page_cache
write是将app_buffer->page_cache
mmap可以直接获取page_cache直写
write+O_DIRECT的话将app_buffer写到io_queue里面
io_queue一方面将写邻近扇区的内容进行merge,另外一方面进行排序确保磁头和磁 盘旋转最少。
io_queue的工作也需要结合IO调度算法。不过这些仅仅对于physical disk有效。
对于ssd而言的话,因为完全是随机写,基本没有调度算法。
driver(filesystem module)通过DMA写入disk_cache之后(使用fsync就可以强制刷新)到disk上面了。
直接操作设备(RAW)方式直接写disk_cache.
O_DIRECT 和 RAW设备最根本的区别是O_DIRECT是基于文件系统的,也就是在应用层来看,其操作对象是文件句柄,内核和文件层来看,其操作是基于inode和数据块,这些概念都是和ext2/3的文件系统相关,写到磁盘上最终是ext3文件。而RAW设备写是没有文件系统概念,操作的是扇区号,操作对象是扇区,写出来的东西不一定是ext3文件(如果按照ext3规则写就是ext3文件)。一般基于O_DIRECT来设计优化自己的文件模块,是不满系统的cache和调度策略,自己在应用层实现这些,来制定自己特有的业务特色文件读写。但是写出来的东西是ext3文件,该磁盘卸下来,mount到其他任何linux系统上,都可以查看。而基于RAW设备的设计系统,一般是不满现有ext3的诸多缺陷,设计自己的文件系统。自己设计文件布局和索引方式。举个极端例子:把整个磁盘做一个文件来写,不要索引。这样没有inode限制,没有文件大小限制,磁盘有多大,文件就能多大。这样的磁盘卸下来,mount到其他linux系统上,是无法识别其数据的。两者都要通过驱动层读写;在系统引导启动,还处于实模式的时候,可以通过bios接口读写raw设备。
操作系统为了提高文件读写效率,在内核层提供了读写缓冲区。对于磁盘的写并不是立刻写入磁盘, 而是首先写入页面缓冲区然后定时刷到硬盘上。但是这种机制降低了文件更新速度,并且如果系统发生故障 的话,那么会造成部分数据丢失。这里的3个sync函数就是为了这个问题的。
sync.是强制将所有页面缓冲区都更新到磁盘上。
fsync.是强制将某个fd涉及到的页面缓存更新到磁盘上(包括文件属性等信息).
fdatasync.是强制将某个fd涉及到的数据页面缓存更新到磁盘上。
参考:《linux c 编程一站式学习》
http://dirlt.com/apue.html

相关文章推荐
- linux系统编程之基础必备(七):read/write函数与(非)阻塞I/O的概念
- linux系统编程之基础必备(七):read/write函数与(非)阻塞I/O的概念
- linux系统编程之基础必备(三):文件描述符file descriptor与inode的相关知识
- Linux下的C语言编程——系统调用read和write函数实现文件拷贝
- linux系统编程之基础必备(三):文件描述符file descriptor与inode的相关知识
- linux系统编程之基础必备(二):C 标准IO 库函数与Unbuffered IO函数
- linux系统编程之基础必备(五):Linux进程地址空间和虚拟内存
- Linux 中的read系统调用到底是阻塞还是非阻塞的
- linux基础之 c语言编程中 write 和 read 注意
- Linux系统编程手册一 :Linux系统基本概念。
- linux 网络编程基础(四)read,write,connect, accept 超时封装
- Linux基础入门及系统管理01-Linux运维必备知识-用户及权限详解10
- linux基础编程:IO模型:阻塞/非阻塞/IO复用 同步/异步 Select/Epoll/AIO
- Linux基础系统概念与基础知识
- Python基础(八)-系统编程之进程--multiprocessing(阻塞非阻塞)
- linux文件设备与I/O:read/write函数与阻塞 Block
- 嵌入式linux系统基础与编程笔记汇总
- (转)linux下bluetooth编程(一)基础概念
- Linux基础入门及系统管理01-bash脚本编程之二if等条件判断脚本知识17
- Linux系统进程控制编程(一)————基本概念和函数getpid的使用