网上找的一个读取wave文件的代码片段
2013-05-04 10:49
295 查看
struct RIFF_HEADER
{
char szRiffID[4]; // 'R','I','F','F'
DWORD dwRiffSize;
char szRiffFormat[4]; // 'W','A','V','E'
};
struct WAVE_FORMAT
{
WORD wFormatTag;
WORD wChannels;
DWORD dwSamplesPerSec;
DWORD dwAvgBytesPerSec;
WORD wBlockAlign;
WORD wBitsPerSample;
};
struct waveHead
{
RIFF_HEADER riff;
char szFmtID[4]; // 'f','m','t',' '
DWORD dwFmtSize;
WAVE_FORMAT wavFormat;
};
struct FACT_BLOCK
{
char szFactID[4]; // 'f','a','c','t'
DWORD dwFactSize;
};
struct DATA_BLOCK
{
char szDataID[4]; // 'd','a','t','a'
DWORD dwDataSize;
};
#define WAVE_FORMAT_PCM 0x0001
#define WAVE_FORMAT_ADPCM 0x0002
else if (m_iSoundType == wavesound)
{
waveHead aHeader;
fseek(m_soundf, 0, SEEK_SET);
fread(&aHeader, 1, sizeof(waveHead), m_soundf);
if (aHeader.wavFormat.wFormatTag != WAVE_FORMAT_PCM)
{
PGELOG(LOG_ERROR, "不支持的Wave格式:%s", caFile);
fclose(m_soundf);
m_soundf = 0;
return -1;
}
memcpy(&m_wformat, &(aHeader.wavFormat), sizeof(WAVE_FORMAT));
m_wformat.cbSize = 0;
//if (aHeader.dwFmtSize == 18)
//fread(&(m_wformat.cbSize), 1, sizeof(WORD), m_soundf);
fseek(m_soundf, aHeader.dwFmtSize-16, SEEK_CUR);
FACT_BLOCK fact;
DATA_BLOCK data;
fread(&fact, 1, sizeof(FACT_BLOCK), m_soundf);
if (*((DWORD*)fact.szFactID) == *((DWORD*)"fact"))
{
fseek(m_soundf, fact.dwFactSize, SEEK_CUR);
fread(&data, 1, sizeof(DATA_BLOCK), m_soundf);
}
else if (*((DWORD*)fact.szFactID) == *((DWORD*)"data"))
memcpy(&data, &fact, sizeof(DATA_BLOCK));
m_iDataStart = ftell(m_soundf);
m_iDataSize = data.dwDataSize;
fread(m_pWaveData, 1, m_iDataSize, m_soundf);
}附上wave文件格式:
下面我们具体地分析 WAVE 文件的格式
| endian | field name | Size | |
| big | ChunkID | 4 | 文件头标识,一般就是" RIFF" 四个字母 |
| little | ChunkSize | 4 | 整个数据文件的大小,不包括上面ID和Size本身 |
| big | Format | 4 | 一般就是" WAVE" 四个字母 |
| big | SubChunk1ID | 4 | 格式说明块,本字段一般就是"fmt " |
| little | SubChunk1Size | 4 | 本数据块的大小,不包括ID和Size字段本身 |
| little | AudioFormat | 2 | 音频的格式说明 |
| little | NumChannels | 2 | 声道数 |
| little | SampleRate | 4 | 采样率 |
| little | ByteRate | 4 | 比特率,每秒所需要的字节数 |
| little | BlockAlign | 2 | 数据块对齐单元 |
| little | BitsPerSample | 2 | 采样时模数转换的分辨率 |
| big | SubChunk2ID | 4 | 真正的声音数据块,本字段一般是"data" |
| little | SubChunk2Size | 4 | 本数据块的大小,不包括ID和Size字段本身 |
| little | Data | N | 音频的采样数据 |
| ChunkID | 4bytes | ASCII 码表示的“RIFF”。(0x52494646) |
| ChunkSize | 4bytes | 36+SubChunk2Size,或是 4 + ( 8 + SubChunk1Size ) + ( 8 + SubChunk2Size ), 这是整个数据块的大小(不包括ChunkID和ChunkSize的大小) |
| Format | 4bytes | ASCII 码表示的“WAVE”。(0x57415645) |
| SubChunk1ID | 新的数据块(格式信息说明块) ASCII 码表示的“fmt ”——最后是一个空格。(0x666d7420) | |
| SubChunk1Size | 4bytes | 本块数据的大小(对于PCM,值为16)。 |
| AudioFormat | 2bytes | PCM = 1 (比如,线性采样),如果是其它值的话,则可能是一些压缩形式 |
| NumChannels | 2bytes | 1 => 单声道 | 2 => 双声道 |
| SampleRate | 4bytes | 采样率,如 8000,44100 等值 |
| ByteRate | 4bytes | 等于: SampleRate * numChannels * BitsPerSample / 8 |
| BlockAlign | 2bytes | 等于:NumChannels * BitsPerSample / 8 |
| BitsPerSample | 2bytes | 采样分辨率,也就是每个样本用几位来表示,一般是 8bits 或是 16bits |
| SubChunk2ID | 4bytes | 新数据块,真正的声音数据 ASCII 码表示的“data ”——最后是一个空格。(0x64617461) |
| SubChunk2Size | 4bytes | 数据大小,即,其后跟着的采样数据的大小。 |
| Data | N bytes | 真正的声音数据 |
1. 8 Bit 单声道:
| 采样1 | 采样2 |
| 数据1 | 数据2 |
| 采样1 | 采样2 | ||
| 声道1数据1 | 声道2数据1 | 声道1数据2 | 声道2数据2 |
| 采样1 | 采样2 | ||
| 数据1低字节 | 数据1高字节 | 数据1低字节 | 数据1高字节 |
| 采样1 | |||
| 声道1数据1低字节 | 声道1数据1高字节 | 声道2数据1低字节 | 声道2数据1高字节 |
| 采样2 | |||
| 声道1数据2低字节 | 声道1数据2高字节 | 声道2数据2低字节 | 声道2数据2高字节 |
52 49 46 46 24 08 00 00 57 41 56 45 66 6d 74 20 10 00 00 00 01 00 02 00 22 56 00 00 88 58 01 00 04 00 10 00 64 61 74 61 00 08 00 00 00 00 00 00 24 17 1e f3 3c 13 3c 14 16 f9 18 f9 34 e7 23 a6 3c f2 24 f2 11 ce 1a 0d
对应的分析如下图所示:
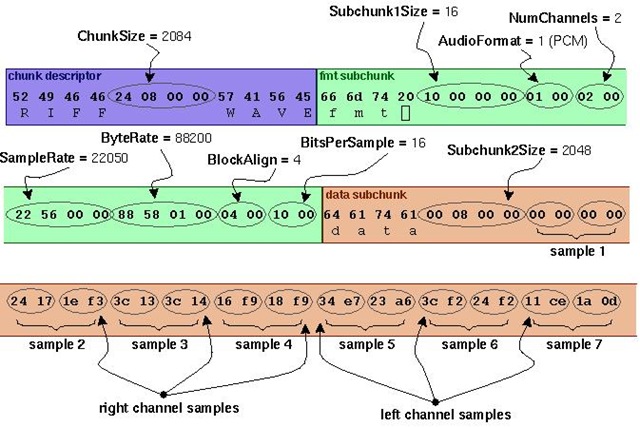
自己测试了下暂时还没有弄通。

相关文章推荐
- 网上找的一个读取wave文件的代码片段
- 花一天时间搜索,居然找到一个德国人写的论文里面有用Matlab读取*.spa文件的程序片段
- 网上只写了一个文件断点下载的例子! 我仿照别人得例子 自己增加了自己代码,异步下载文件 支持断点下载 多任务下载! 如有问题 请联系我
- ResourceBundle读取properties文件 代码片段
- C#.NET读取一个文件夹下所有excel文件的代码
- java处理国际化和读取properties文件代码片段
- C# 读取Excel文件代码的几种片段收集
- 在网上找的一个Flex文件上传代码,记录下来,以后用到的时候可以马上能用:
- 常用java代码片段之读取资源文件
- C# 读取Excel文件代码的几种片段收集(转)
- python 从两个配置文件读取数据,形成一个url思路代码
- 【转载】C# 读取Excel文件代码的几种片段收集
- C# 读取Excel文件代码的几种片段收集
- java读取txt文件代码片段
- JS读取client端的文件的代码片段
- C# 读取Excel文件代码的几种片段收集
- java读取文件封装的一个类(有部分代码借鉴别人的)
- 常用java代码片段之读取删除文件
- C# 读取Excel文件代码的几种片段收集
- java读取文件封装的一个类(有部分代码借鉴别人的)