Oracle教程之深入Oracle Buffer Cache
2013-04-19 09:44
162 查看
用最简单的语言来描述Oracle数据库的本质,其实就是能够用磁盘上的一堆文件来存储数据,并提供了各种各样的手段对这些数据进行管理。作为管理数据的最基本要求就是能够保存和读取磁盘上文件中的数据。众所周知,读取磁盘的速度相对来说是非常慢的,而读取内存的速度相对则要快得多。因此为了能够加快处理数据的速度,Oracle必须将读取过的数据缓存在内存里。而Oracle对这些缓存在内存里的数据起了个名字:数据块缓存区(Database buffer cache),通常就叫做buffer cache。按照Oracle官方的说法,buffer cache就是一块含有许多数据块的内存区域,而这些数据块主要都是数据文件中数据块内容的副本。通过初始化参数buffer_cache_size来指定buffer cache的大小。Oracle实例一旦启动,该区域大小就被分配好了。 1、Buffer Cache的功能: 通过缓存数据块,从而减少I/O。 通过构造CR(Consistent Read)块,从而提供读一致性功能。 通过提供各种lock、latch机制,从而提供多个进程并发访问同一个数据块的功能。内存里的数据块通常叫做buffer,而数据文件里的数据块通常叫做block,二者是一个意思。一般我们会混用这两个名词。 2、Buffer Cache的内存结构Oracle内部在实现其管理的过程中,有两个非常有名的名词:链表和hash算法。链表是一种数据结构,通过将对象串联在一起,从而构成链表结构。这样,如果要修改、删除、查找某个对象的话,都可以先到链表中去查找,而不必实际地访问物理介质。Oracle中最有名的链表大概就是LRU链表了,我们后面会介绍它。而hash算法则在前面描述shared pool时已经做过介绍。我们先来看图5-4。这幅图从逻辑上说明了整个buffer cache的结构是怎么样的。
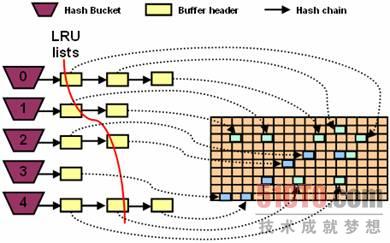
图5-4 buffer cache结构图
从图5-4中我们可以看到,buffer cache就像一个水池,水池的最小单位就是数据块。当每个数据块被读入buffer cache时,Oracle都会抽取数据块的头部,在内存中构建buffer header,并将这些buffer header串成链表的形式。而buffer header里面记录的指针就指向buffer cache中的该数据块本身。于是,Oracle在搜索某个数据块时,就不用去buffer cache中找,而是直接扫描链表上该数据块所对应的buffer header,然后根据找到的buffer header所记录的指针就能到buffer cache中直接定位该数据块了。 在管理buffer header的过程中,Oracle同样借助了hash算法。通过对buffer header里记录的数据块地址和数据块类型运用hash函数以后,得到该数据块所属的组号。这里的组号就是图5-4中的hash bucket。 这里的hash chain就是属于同一个hash bucket的所有buffer header所串起来的链表。实际上,hash bucket只是一个逻辑上的概念。每个hash bucket都是通过不同的hash chain体现出来的。每个hash chain都会由一个cache buffers chains latch来管理其并发操作。 启动数据库以后,Oracle究竟产生多少个hash bucket,则由Oracle自己计算。 当前台进程发出SELECT或者其他DML语句时,Oracle根据SQL语句的执行计划找到符合SQL条件的数据块,然后Oracle会根据对请求的数据块的地址以及数据块的类型作为参数,应用hash函数以后,得到要找的数据块所处的hash bucket,也就是确定该数据块在哪条hash chain上。然后,Oracle进入该hash chain,从上面所挂的第一个buffer header开始,根据buffer header所含有的指针找到对应的块体,然后扫描其中的数据,确认其是否是SQL语句所需要的块,如果是,则返回该块里所需要的数据;否则,如果不是,则继续往下搜索,一直搜索到最后一个buffer header为止。如果一直都没有找到,则调用物理I/O,到数据文件里把该块所含有
图5-4 buffer cache结构图
从图5-4中我们可以看到,buffer cache就像一个水池,水池的最小单位就是数据块。当每个数据块被读入buffer cache时,Oracle都会抽取数据块的头部,在内存中构建buffer header,并将这些buffer header串成链表的形式。而buffer header里面记录的指针就指向buffer cache中的该数据块本身。于是,Oracle在搜索某个数据块时,就不用去buffer cache中找,而是直接扫描链表上该数据块所对应的buffer header,然后根据找到的buffer header所记录的指针就能到buffer cache中直接定位该数据块了。 在管理buffer header的过程中,Oracle同样借助了hash算法。通过对buffer header里记录的数据块地址和数据块类型运用hash函数以后,得到该数据块所属的组号。这里的组号就是图5-4中的hash bucket。 这里的hash chain就是属于同一个hash bucket的所有buffer header所串起来的链表。实际上,hash bucket只是一个逻辑上的概念。每个hash bucket都是通过不同的hash chain体现出来的。每个hash chain都会由一个cache buffers chains latch来管理其并发操作。 启动数据库以后,Oracle究竟产生多少个hash bucket,则由Oracle自己计算。 当前台进程发出SELECT或者其他DML语句时,Oracle根据SQL语句的执行计划找到符合SQL条件的数据块,然后Oracle会根据对请求的数据块的地址以及数据块的类型作为参数,应用hash函数以后,得到要找的数据块所处的hash bucket,也就是确定该数据块在哪条hash chain上。然后,Oracle进入该hash chain,从上面所挂的第一个buffer header开始,根据buffer header所含有的指针找到对应的块体,然后扫描其中的数据,确认其是否是SQL语句所需要的块,如果是,则返回该块里所需要的数据;否则,如果不是,则继续往下搜索,一直搜索到最后一个buffer header为止。如果一直都没有找到,则调用物理I/O,到数据文件里把该块所含有

相关文章推荐
- 8.Oracle深度学习笔记——BUFFER CACHE深入一
- Oracle教程之深入Log Buffer
- Oracle教程之深入Log Buffer
- Oracle 学习之--Buffer Cache深入解析
- Oracle 学习之--Buffer Cache深入解析
- Oracle存储结构深入分析与管理_超越OCP精通Oracle视频教程培训07
- Oracle教程之深入Shared Pool
- Oracle技术之ASM Buffer Cache的作用和功能
- 深入分析Oracle字符集(zt)
- 安装修改CentOS 5.5上安装ORACLE 11g R2最完全安装教程
- Linux下完美卸载Oracle教程
- 索引临时表【Oracle】比较快的删除重复数据的方式Strut2教程-java教程
- Spring MVC 教程,快速入门,深入分析
- Linux 7.4上安装配置Oracle 11.2.0.4图文教程
- python3深入学习教程
- Spring MVC 教程,快速入门,深入分析
- 深入了解Oracle的体系结构
- WPF入门教程系列(二) 深入剖析WPF Binding的使用方法
- oracle教程之oracle动态采样(一)
- Spring MVC 教程,快速入门,深入分析