数据结构知识:链表,队列和栈的区别
2013-04-14 15:47
477 查看
链表,队列和栈都是数据结构的一种。Sartaj Sahni 在他的《数据结构、算法与应用》一书中称:“数据结构是数据对象,以及存在于该对象的实例和组成实例的数据元素之间的各种联系。这些联系可以通过定义相关的函数来给出。”他将数据对象(data
object)定义为“一个数据对象是实例或值的集合”。
一. 链表
1.定义
链表(Linked list)是一种常见的基础数据结构,是一种线性表,但是并不会按线性的顺序存储数据,而是在由一个个节点组成,每个节点(node)中储存着数据变量(data)和指针变量(node next),又有一个头节点(head)连接下面的节点,而最后一个节点指向空(null)。可以在链表类中定义增加,删除,插入,遍历,修改等方法,故常用来储存数据。
2. 优点
(1).使用链表结构可以克服数组链表需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。
(2).数据的存取往往要在不同的排列顺序中转换,而链表是一种自我指示数据类型,因为它包含指向另一个相同类型的数据的指针(链接)。链表允许插入和移除表上任意位置上的节点,但是不允许随机存取。
3. 缺点
链表失去了数组随机读取的优点,同时链表由于增加了结点的指针域,空间开销比较大。
4. 类型
主要有单向链表,双向链表以及循环链表。
5. 实例
(1).单向链表
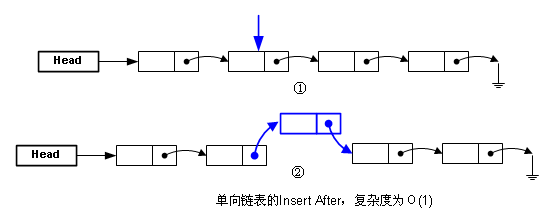
(2).双向链表

6. 与数组(Array)的对比
链表的使用不需要知道数据的大小,而数组在创建时必须指明数组的大小。
链表没有对应的下标,只有指向下一个数据的指针,而数组中每一个都有一个相对应的下标。
链表在内存中储存的数据可以是不连续的,而数组储存的数据占内存中连续的一段,用标识符标识。
二. 队列
1. 定义
队列是一种特殊的线性表,它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作。进行插入操作的端称为队尾,进行删除操作的端称为队头。队列中没有元素时,称为空队列。
在队列这种数据结构中,最先插入的元素将是最先被删除的元素;反之最后插入的元素将最后被删除的元素,因此队列又称为“先进先出”(FIFO—first in first out)的线性表。
2. 队列的方法
add(E e)
将指定的元素插入此队列(如果立即可行且不会违反容量限制),在成功时返回 true,如果当
前没有可用的空间,则抛出
IllegalStateException。返回boolean。
element() 获取不移除此队列的头,如果此队列为空,则抛出NoSuchElementException,返回泛型E。
offer(E e) 将指定的元素插入此队列(如果立即可行且不会违反容量限制),当使用有容量限制的队列时,
此方法通常要优于
add(E),后者可能无法插入元素,而只是抛出一个异常。返回boolean。
peek() 获取不移除此队列的头,如果此队列为空,则返回
null。返回泛型E。
poll()
获取并移除此队列的头,如果此队列为空,则返回 null。返回泛型E。
remove() 获取并移除此队列的头。返回泛型E。
3. 队列的使用和假溢出
队列可以用数组Q[1…m]来存储,数组的上界是m,最大容量是m。在队列的运算中需设两个指针:队头指针(head),指向实际队头元素的前一个位置;队尾指针(tail),指向实际队尾元素所在的位置,队列中拥有的元素个数为:N=tail-head。一般情况下,两个指针的初值设为0,这时队列为空,没有元素。
若数组定义Q[1…10],head=2,tail=8。如果要让排头的元素出队,则需将头指针加1。即head=head+1这时头指针向上移动一个位置,指向Q(3),表示Q(3)已出队。如果想让一个新元素入队,则需尾指针向上移动一个位置。即tail=tail+1这时Q(9)入队。当队尾已经处理在最上面时,即tail=10,如果还要执行入队操作,则要发生"上溢",但实际上队列中还有三个空位置,所以这种溢出称为"假溢出"。
4. 循环队列的概念
为充分利用向量空间,克服"假溢出"现象的方法是:将向量空间想象为一个首尾相接的圆环,并称这种向量为循环向量。存储在其中的队列称为循环队列(Circular
Queue)。
循环队列的入队算法:
(1). tail=tail+1;
(2). 若tail=m+1,则tail=1;
(3). 若head=tail尾指针与头指针重合了,判断空或满;
(4). 否则,Q[tail]=X,结束(X为新入出元素)。
循环队列的出队算法:
(1). 若head=tail尾指针与头指针重合了,判断空或满;
(2). 若不重合head=head+1;
(3). 若head=m+1,则head=1;
(4). 移除Q[head],结束。
循环队列中,由于入队时尾指针向前追赶头指针;出队时头指针向前追赶尾指针,造成队空和队满时头尾指针均相等。因此,无法通过条件front==rear来判别队列是"空"还是"满"。
解决这个问题的方法至少有两种:
① 另设一布尔变量以区别队列的空和满;
② 另一种方式就是数据结构常用的:队满时:(tail+1)%n=head,n为队列长度(所用数组大小),由于tail,head均为所用空间的指针,循环只是逻辑上的循环,所以需要求余运算。如图情况,队已满,但是tail+1=5+1=6,n=6,求余6%6=0=head。

5. 阻塞队列(BlockingQueue)的概念
三. 栈
1. 定义
栈(Stack),是硬件。主要作用表现为一种数据结构,是只能在某一端插入和删除的特殊线性表。它按照后进先出的原则存储数据,先进入的数据被压入栈底,最后的数据在栈顶,需要读数据的时候从栈顶开始弹出数据(最后一个数据被第一个读出来)。
栈是允许在同一端进行插入和删除操作的特殊线性表。允许进行插入和删除操作的一端称为栈顶(top),另一端为栈底(bottom);栈底固定,而栈顶浮动;栈中元素个数为零时称为空栈。插入一般称为进栈(PUSH),删除则称为退栈(POP)。栈也称为先进后出表。
2. 栈的方法
empty()
测试堆栈是否为空。返回boolean。
peek()
查看堆栈顶部的对象,但不从堆栈中移除它。返回泛型E。
pop()
移除堆栈顶部的对象,并作为此函数的值返回该对象。返回泛型E。
push(E item)
把项压入堆栈顶部。返回泛型E。
search(Object o)
返回对象在堆栈中的位置,以 1 为基数。返回int。
3. 栈的实现

1、进栈(PUSH)算法
①若TOP≥n时,则给出溢出信息,作出错处理(进栈前首先检查栈是否
已满,满则溢出;不满则作②);
②置TOP=TOP+1(栈指针加1,指向进栈地址);
③S(TOP)=X,结束(X为新进栈的元素);
2、退栈(POP)算法
①若TOP≤0,则给出下溢信息,作出错处理(退栈前先检查是否已为空栈,
空则下溢;不空则作②);
②X=S(TOP),(退栈后的元素赋给X):
③TOP=TOP-1,结束(栈指针减1,指向栈顶)。
object)定义为“一个数据对象是实例或值的集合”。
一. 链表
1.定义
链表(Linked list)是一种常见的基础数据结构,是一种线性表,但是并不会按线性的顺序存储数据,而是在由一个个节点组成,每个节点(node)中储存着数据变量(data)和指针变量(node next),又有一个头节点(head)连接下面的节点,而最后一个节点指向空(null)。可以在链表类中定义增加,删除,插入,遍历,修改等方法,故常用来储存数据。
2. 优点
(1).使用链表结构可以克服数组链表需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。
(2).数据的存取往往要在不同的排列顺序中转换,而链表是一种自我指示数据类型,因为它包含指向另一个相同类型的数据的指针(链接)。链表允许插入和移除表上任意位置上的节点,但是不允许随机存取。
3. 缺点
链表失去了数组随机读取的优点,同时链表由于增加了结点的指针域,空间开销比较大。
4. 类型
主要有单向链表,双向链表以及循环链表。
5. 实例
(1).单向链表
(2).双向链表
6. 与数组(Array)的对比
链表的使用不需要知道数据的大小,而数组在创建时必须指明数组的大小。
链表没有对应的下标,只有指向下一个数据的指针,而数组中每一个都有一个相对应的下标。
链表在内存中储存的数据可以是不连续的,而数组储存的数据占内存中连续的一段,用标识符标识。
二. 队列
1. 定义
队列是一种特殊的线性表,它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作。进行插入操作的端称为队尾,进行删除操作的端称为队头。队列中没有元素时,称为空队列。
在队列这种数据结构中,最先插入的元素将是最先被删除的元素;反之最后插入的元素将最后被删除的元素,因此队列又称为“先进先出”(FIFO—first in first out)的线性表。
2. 队列的方法
add(E e)
将指定的元素插入此队列(如果立即可行且不会违反容量限制),在成功时返回 true,如果当
前没有可用的空间,则抛出
IllegalStateException。返回boolean。
element() 获取不移除此队列的头,如果此队列为空,则抛出NoSuchElementException,返回泛型E。
offer(E e) 将指定的元素插入此队列(如果立即可行且不会违反容量限制),当使用有容量限制的队列时,
此方法通常要优于
add(E),后者可能无法插入元素,而只是抛出一个异常。返回boolean。
peek() 获取不移除此队列的头,如果此队列为空,则返回
null。返回泛型E。
poll()
获取并移除此队列的头,如果此队列为空,则返回 null。返回泛型E。
remove() 获取并移除此队列的头。返回泛型E。
3. 队列的使用和假溢出
队列可以用数组Q[1…m]来存储,数组的上界是m,最大容量是m。在队列的运算中需设两个指针:队头指针(head),指向实际队头元素的前一个位置;队尾指针(tail),指向实际队尾元素所在的位置,队列中拥有的元素个数为:N=tail-head。一般情况下,两个指针的初值设为0,这时队列为空,没有元素。
若数组定义Q[1…10],head=2,tail=8。如果要让排头的元素出队,则需将头指针加1。即head=head+1这时头指针向上移动一个位置,指向Q(3),表示Q(3)已出队。如果想让一个新元素入队,则需尾指针向上移动一个位置。即tail=tail+1这时Q(9)入队。当队尾已经处理在最上面时,即tail=10,如果还要执行入队操作,则要发生"上溢",但实际上队列中还有三个空位置,所以这种溢出称为"假溢出"。
4. 循环队列的概念
为充分利用向量空间,克服"假溢出"现象的方法是:将向量空间想象为一个首尾相接的圆环,并称这种向量为循环向量。存储在其中的队列称为循环队列(Circular
Queue)。
循环队列的入队算法:
(1). tail=tail+1;
(2). 若tail=m+1,则tail=1;
(3). 若head=tail尾指针与头指针重合了,判断空或满;
(4). 否则,Q[tail]=X,结束(X为新入出元素)。
循环队列的出队算法:
(1). 若head=tail尾指针与头指针重合了,判断空或满;
(2). 若不重合head=head+1;
(3). 若head=m+1,则head=1;
(4). 移除Q[head],结束。
循环队列中,由于入队时尾指针向前追赶头指针;出队时头指针向前追赶尾指针,造成队空和队满时头尾指针均相等。因此,无法通过条件front==rear来判别队列是"空"还是"满"。
解决这个问题的方法至少有两种:
① 另设一布尔变量以区别队列的空和满;
② 另一种方式就是数据结构常用的:队满时:(tail+1)%n=head,n为队列长度(所用数组大小),由于tail,head均为所用空间的指针,循环只是逻辑上的循环,所以需要求余运算。如图情况,队已满,但是tail+1=5+1=6,n=6,求余6%6=0=head。
5. 阻塞队列(BlockingQueue)的概念
三. 栈
1. 定义
栈(Stack),是硬件。主要作用表现为一种数据结构,是只能在某一端插入和删除的特殊线性表。它按照后进先出的原则存储数据,先进入的数据被压入栈底,最后的数据在栈顶,需要读数据的时候从栈顶开始弹出数据(最后一个数据被第一个读出来)。
栈是允许在同一端进行插入和删除操作的特殊线性表。允许进行插入和删除操作的一端称为栈顶(top),另一端为栈底(bottom);栈底固定,而栈顶浮动;栈中元素个数为零时称为空栈。插入一般称为进栈(PUSH),删除则称为退栈(POP)。栈也称为先进后出表。
2. 栈的方法
empty()
测试堆栈是否为空。返回boolean。
peek()
查看堆栈顶部的对象,但不从堆栈中移除它。返回泛型E。
pop()
移除堆栈顶部的对象,并作为此函数的值返回该对象。返回泛型E。
push(E item)
把项压入堆栈顶部。返回泛型E。
search(Object o)
返回对象在堆栈中的位置,以 1 为基数。返回int。
3. 栈的实现
1、进栈(PUSH)算法
①若TOP≥n时,则给出溢出信息,作出错处理(进栈前首先检查栈是否
已满,满则溢出;不满则作②);
②置TOP=TOP+1(栈指针加1,指向进栈地址);
③S(TOP)=X,结束(X为新进栈的元素);
2、退栈(POP)算法
①若TOP≤0,则给出下溢信息,作出错处理(退栈前先检查是否已为空栈,
空则下溢;不空则作②);
②X=S(TOP),(退栈后的元素赋给X):
③TOP=TOP-1,结束(栈指针减1,指向栈顶)。

相关文章推荐
- 数据结构知识:链表,队列和栈的区别
- [Python面试知识]数据结构之栈和队列实现
- 数据结构之用数组和链表实现队列
- 2013数据结构课程设计之通讯录(复习链表与文件知识)
- 数据结构知识整理-链表的建立 逆置
- 经典数据结构之队列的链表实现方法
- 数据结构之队列的链表实现
- 数据存储的常用结构 堆栈、队列、数组、链表
- 第十章 动态数据结构:栈、队列、单链表
- 数据结构(一)顺序表、链表以及队列
- 【数据结构】顺序队列与链表队列
- 【数据结构与算法学习笔记】PART3 线性结构(除向量外,数组、栈、队列、链表)
- 学习java数据结构基础知识之链表
- 数据结构与实现——数组、矩阵、链表、队列、栈、对象、二叉树和红黑树
- (8)数据结构——队列(链表)实现
- Java数据结构与算法—及实现 线性表 顺序表、链表、栈、队列详解
- 【数据结构】顺序队列(链表实现)
- 数据结构知识汇总1:线性表,栈和队列
- 数据结构——链表、栈和队列
- 高性能流媒体服务器-nebula之数据结构(8)--双链表实现的内存中立队列