【整理】如何学习Python + 如何有效利用Python有关的网络资源 + 如何利用Python自带手册(Python Manual)
2013-03-13 16:22
1306 查看
都差点忘了说了,在看下面所有的内容之前,对于python版本不了解的,请一定先看看这个:
【整理】总结Python2(Python
2.x版本)和Python3(Python 3.x版本)之间的区别
然后根据情况,选择自己需要的python版本,然后才涉及到,如何学习的问题。
【学习Python的基本流程】
1.先学习Python的基础知识
推荐资料:
Dive Into Python
中文主页是:
http://woodpecker.org.cn/diveintopython/
可以在线看:
深入 Python

ive Into Python 中文版
也可以下载各种格式:
HTML
HTML (单文件)
PDF (A4)
Microsoft Word 2003
Windows Help
纯文本
留本地看。
其他python资料,其实网上很多。
但是作为入门,这个是经典。
看完经典的,达到入门,就足够了。
2.在实践中锻炼
了解了Python基础后,剩下的,就是自己找找事情折腾。
所以想要学好一门语言,最重要的一点,永远都是:多练。
时间长了,自然熟能生巧,举一反三,触类旁通,见多识广。
3.遇到问题,先尽量靠自己解决,实在解决不了,再靠网络和别人
小问题靠自己查查Python自带手册;
大问题,靠网络搜索,即使没找到解决方法,也能找到有效的提示,所以就足够了。
【有效利用网络资源】
在学习过程中,以及后续的折腾python的过程中,要学会充分利用网络上已有的资源。
这里的网络资源,主要指的是第三方库函数,网络上已有的关于python方面的总结性资料。
1. Python的第三方库
python的第三方库,数量巨大,功能巨多,但是正是由于太多,不可能一一总结。
但是python官网,人家已经整理出来了,都放到这里了:
http://pypi.python.org/pypi?%3Aaction=index
该页面由于库太多,看着很不方便。
这里有分类查看:
http://pypi.python.org/pypi?%3Aaction=browse
如果需要某些方面的功能,可以去上述两个地址中,找找有没有现成的库,如果有的话,直接拿过来用,比你从头开发,要高效的多。
2. 各种Python的总结方面的资料
其中包括我写的Python语言总结,其中主要分两块:
(1)python学习心得和体会
总结了自己折腾python过程中的一些理解,和一些细节方面的注意事项。
(2)crifan的Python库:crifanLib.py
自己把一些常用的Python的函数,整理出来,供自己和别人使用。
尤其是很多网络方面的函数,等你用到了,就会知道会省你不少精力的。
有空多看看各种总结,有利于减少自己犯同样错误的几率。
【如何利用Python自带手册 Python Manual】
其中,关于查参考资料,特别要提示的一点是,对于很多不熟悉的python函数,最佳的学习方法,个人认为是先去Python自带手册中去查找。
而Python自带手册,是你安装好Python之后,(我的是windows环境,通过exe安装的python 2.7版的),可以通过开始->Python 27-> Python Mannuals:
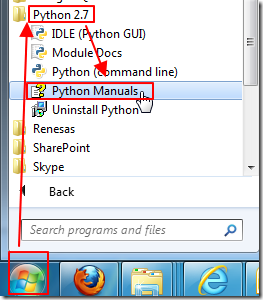
而找到。
随便举个例子。
比如涉及到网络编程,需要用到urllib2这个模块,你只是听说,但是不熟悉,想要搞懂urllib2。
那么第一步,就可以先去通过manual找到urllib2:
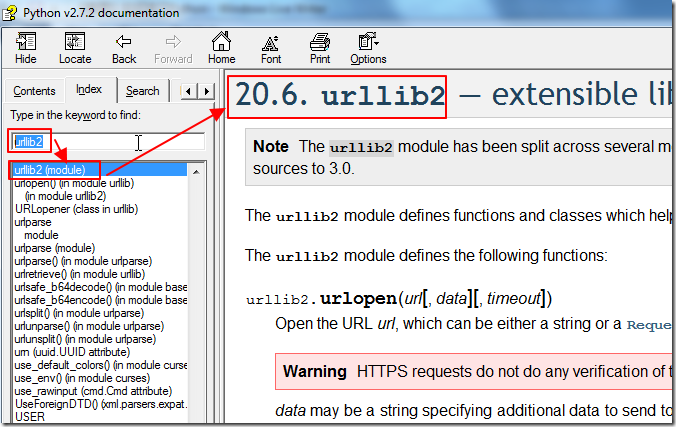
然后再去看看其语法:
urllib2.urlopen(url[, data][,
timeout])Open the URL url, which can be either a string or a Request object.
Warning
HTTPS requests do not do any verification of the server’s certificate.
data may be a string specifying additional data to send to the server, or
None if no such data is needed. Currently HTTP requests are the only ones that use
data; the HTTP request will be a POST instead of a GET when the data parameter is provided.
data should be a buffer in the standard application/x-www-form-urlencoded format. The
urllib.urlencode() function takes a mapping or sequence of 2-tuples and returns a string in this format. urllib2 module sends HTTP/1.1 requests with
Connection:close header included.
The optional timeout parameter specifies a timeout in seconds for blocking operations like the connection attempt (if not specified, the global default timeout setting will be used). This actually only works for HTTP, HTTPS and FTP connections.
This function returns a file-like object with two additional methods:
geturl() — return the URL of the resource retrieved, commonly used to determine if a redirect was followed
info() — return the meta-information of the page, such as headers, in the form of an
mimetools.Message instance (see
Quick Reference to HTTP Headers)
Raises URLError on errors.
Note that None may be returned if no handler handles the request (though the default installed global
OpenerDirector uses UnknownHandler to ensure this never happens).
In addition, default installed ProxyHandler makes sure the requests are handled through the proxy when they are set.
Changed in version 2.6: timeout was added.
如此,对于其有个基本的了解后,再去网上详细看看别人的示例代码。
这样,有助于你快速,准确的,学习此库函数。
至少,我对于很多很多的python内置库函数,都是这样慢慢逐渐学习和了解的。
【整理】总结Python2(Python
2.x版本)和Python3(Python 3.x版本)之间的区别
然后根据情况,选择自己需要的python版本,然后才涉及到,如何学习的问题。
【学习Python的基本流程】
1.先学习Python的基础知识
推荐资料:
Dive Into Python
中文主页是:
http://woodpecker.org.cn/diveintopython/
可以在线看:
深入 Python
ive Into Python 中文版
也可以下载各种格式:
HTML
HTML (单文件)
PDF (A4)
Microsoft Word 2003
Windows Help
纯文本
留本地看。
其他python资料,其实网上很多。
但是作为入门,这个是经典。
看完经典的,达到入门,就足够了。
2.在实践中锻炼
了解了Python基础后,剩下的,就是自己找找事情折腾。
所以想要学好一门语言,最重要的一点,永远都是:多练。
时间长了,自然熟能生巧,举一反三,触类旁通,见多识广。
3.遇到问题,先尽量靠自己解决,实在解决不了,再靠网络和别人
小问题靠自己查查Python自带手册;
大问题,靠网络搜索,即使没找到解决方法,也能找到有效的提示,所以就足够了。
【有效利用网络资源】
在学习过程中,以及后续的折腾python的过程中,要学会充分利用网络上已有的资源。
这里的网络资源,主要指的是第三方库函数,网络上已有的关于python方面的总结性资料。
1. Python的第三方库
python的第三方库,数量巨大,功能巨多,但是正是由于太多,不可能一一总结。
但是python官网,人家已经整理出来了,都放到这里了:
http://pypi.python.org/pypi?%3Aaction=index
该页面由于库太多,看着很不方便。
这里有分类查看:
http://pypi.python.org/pypi?%3Aaction=browse
如果需要某些方面的功能,可以去上述两个地址中,找找有没有现成的库,如果有的话,直接拿过来用,比你从头开发,要高效的多。
2. 各种Python的总结方面的资料
其中包括我写的Python语言总结,其中主要分两块:
(1)python学习心得和体会
总结了自己折腾python过程中的一些理解,和一些细节方面的注意事项。
(2)crifan的Python库:crifanLib.py
自己把一些常用的Python的函数,整理出来,供自己和别人使用。
尤其是很多网络方面的函数,等你用到了,就会知道会省你不少精力的。
有空多看看各种总结,有利于减少自己犯同样错误的几率。
【如何利用Python自带手册 Python Manual】
其中,关于查参考资料,特别要提示的一点是,对于很多不熟悉的python函数,最佳的学习方法,个人认为是先去Python自带手册中去查找。
而Python自带手册,是你安装好Python之后,(我的是windows环境,通过exe安装的python 2.7版的),可以通过开始->Python 27-> Python Mannuals:
而找到。
随便举个例子。
比如涉及到网络编程,需要用到urllib2这个模块,你只是听说,但是不熟悉,想要搞懂urllib2。
那么第一步,就可以先去通过manual找到urllib2:
然后再去看看其语法:
urllib2.urlopen(url[, data][,
timeout])Open the URL url, which can be either a string or a Request object.
Warning
HTTPS requests do not do any verification of the server’s certificate.
data may be a string specifying additional data to send to the server, or
None if no such data is needed. Currently HTTP requests are the only ones that use
data; the HTTP request will be a POST instead of a GET when the data parameter is provided.
data should be a buffer in the standard application/x-www-form-urlencoded format. The
urllib.urlencode() function takes a mapping or sequence of 2-tuples and returns a string in this format. urllib2 module sends HTTP/1.1 requests with
Connection:close header included.
The optional timeout parameter specifies a timeout in seconds for blocking operations like the connection attempt (if not specified, the global default timeout setting will be used). This actually only works for HTTP, HTTPS and FTP connections.
This function returns a file-like object with two additional methods:
geturl() — return the URL of the resource retrieved, commonly used to determine if a redirect was followed
info() — return the meta-information of the page, such as headers, in the form of an
mimetools.Message instance (see
Quick Reference to HTTP Headers)
Raises URLError on errors.
Note that None may be returned if no handler handles the request (though the default installed global
OpenerDirector uses UnknownHandler to ensure this never happens).
In addition, default installed ProxyHandler makes sure the requests are handled through the proxy when they are set.
Changed in version 2.6: timeout was added.
如此,对于其有个基本的了解后,再去网上详细看看别人的示例代码。
这样,有助于你快速,准确的,学习此库函数。
至少,我对于很多很多的python内置库函数,都是这样慢慢逐渐学习和了解的。

相关文章推荐
- 深度学习 13. 能力提升, 一步一步的介绍如何自己构建网络和训练,利用MatConvNet(二),思路整理
- 【Python开发】【神经网络与深度学习】如何利用Python写简单网络爬虫
- 如何利用网络资源来学习
- 有关TI DSP的一些东西(整理一些网络资源及手册资料)--外设寄存器和CPU控制寄存器、数据类型、中断的使用
- Python 学习资源 ( 整理日期2010-02-24 )
- 如何利用神经网络和Python生成指定模式的密码
- [Python系列实用教程]一、Python如何使用urllib2获取网络资源
- 如何利用Java库学习神经网络
- Python 学习资源 ( 整理日期2010-02-24 )
- eventlet引发的学习-python如何利用多核CPU
- PHP学习可以利用的有效资源,扩展
- 如何利用深度学习写诗歌(使用Python进行文本生成)
- Python如何使用urllib2获取网络资源
- Python如何使用urllib2获取网络资源
- 学习 | Python之高级特性:如何写出少而有效的代码
- 如何利用Google的WebService搜索网络资源
- Python如何使用urllib2获取网络资源
- python学习网络资源小总结
- android 开发零起步学习笔记(二十):Android开发笔记:如何使用预先制作好的SQLite数据库(整理自网络)
- 【转】Python如何使用urllib2获取网络资源(zz)