oracle查询语句中select from where group by having order by的解释与应用
2012-08-07 16:16
761 查看
oracle查询语句中select from where group by having order by的解释与应用
查询中用到的关键词主要包含六个,并且他们的顺序依次为
select--from--where--group by--having--order by
其中select和from是必须的,其他关键词是可选的,这六个关键词的执行顺序
与sql语句的书写顺序并不是一样的,而是按照下面的顺序来执行
from--where--group by--having--select--order by,
from:需要从哪个数据表检索数据
where:过滤表中数据的条件
group by:如何将上面过滤出的数据分组
having:对上面已经分组的数据进行过滤的条件
select:查看结果集中的哪个列,或列的计算结果
order by :按照什么样的顺序来查看返回的数据
select关键字 www.2cto.com
1、用*代替所有列
select * from emp;
2、指定需要返回的列
select ename,deptno ,job from emp;
3、为列取别名
select ename emloyee_name,job ,deptno from emp;
4、去除某列中的相同数据
select distinct deptno ,job from emp;
5、返回两个列进行运算后的数据
create table tab1(first_col number(3),second_col number(3));
insert into tab1 values(3,6);
insert into tab1 values(1,10);
select first_col,second_col,first_col+second_col from tab1;
返回结果如下
FIRST_COL SECOND_COL FIRST_COL+SECOND_COL
---------- ---------- --------------------
3 6 9
1 10 11
6、对单列进行运算后返回
select first_col,second_col,first_col*10 from tab1;
结果如下
FIRST_COL SECOND_COL FIRST_COL*10
---------- ---------- ------------
3 6 30
1 10 10
7、select 1+2 from dept;
返回结果如下
www.2cto.com
1+2
---------
3
3
3
3
这样的查询似乎看起来没有什么意义,出现四行是因为有四个部门,对每个部门
都要执行一次1+2并且返回。
假设建立一个表只有一条数据那么将只会返回一条数据,在oracle内部就存在这
样一个表dual,以前我们经常会看到这样的语句
select sysdate from dual;
SYSDATE
--------------
05-8月 -12
即返回系统日期
假如执行这样的语句,利用上面建立的表tab1
select sysdate from tab1;
看看结果会是什么
SYSDATE
-----------
05-8月 -12
05-8月 -12
返回了两个日期,因为表tab1中有两条数据,这也可以说明返回的数据只是一个
常量,并不是从dual表中取得的,
只是利用了dual表中有一条数据的特点,这个表完全可以自己建立,也会取得和
www.2cto.com
dual一样的效果
where关键字
一个简单的查询条件一般包含一个比较运算符(< <= > >+ = <>)
由比较运算符组成的语句能够判断为true和false,当为true时,则说明该行符
合条件,作为用户检索的数据返回给用户,例如
select * from emp where sal>4000;
order by关键字
如果想要检索返回的数据按照一定的顺序排列,就需要使用order by关键词,
select * from emp order by ename desc nulls last;
select * from emp order by ename asc nulls first;
其中asc是指按照指定的列按照升序排列,desc按降序排列,nulls first指将为
空的行显示在最前面,
nulls last是指将为空的数据所在行显示在最后,对于升序排列nulls last为默
认,如果按照降序排列nulls first 为默认
例如
select * from emp order by comm ;等价于
select * from emp order by comm asc nulls last;
select * from emp order by comm desc;等价于
select * from emp order by comm desc nulls first;
如果按照多个字段排序
select * from emp order by deptno asc,ename desc;
会先按照deptno进行升序排列,相同的deptno按照姓名的降序排列
运算符and or not
两个条件分别进行判断为true或者false
true or ...-->true
true and true-->true
false or false-->false
false and...-->false
例如
select 'true or false' from dual where (1=0) or (1=1);
返回结果为
'TRUEORFALSE'
-------------
true or false
select 'true or false' from dual where (1=0) and (1=1);
返回 no rows selected
对于not运算符可以放在任何一个条件面前,将true和和false反转
例如 www.2cto.com
select * from emp where deptno>20;
select * from emp where not deptno>20;(注意not必须放在整个条件的前面)
运算符between in like
between运算符是用一个范围值对数据进行过滤,这个范围两边是闭区间的
例如
select * from emp where sal between 2850 and 4000;
between运算符
in运算符是让某个列的值或者通过表达式运算出的结果和几个单独的值列表进行
比较,例如
select * from emp where sal in (2850,3000,5000);
like运算符,like运算符后面的表达式可以有几种情况
'%ab' 列的值最后两个字母是ab
'%ab%'列的值中包含ab,注意ab是一体的
'ab%' 列的值最开始两个字母是ab
'_ab%'列的值第二三个字母是ab,其中_为占位符,一个_占一位
select * from emp where ename like '_MI%';
case表达式,简单的语法格式如下图

例如
select ename ,case deptno
when 10 then '10部门'
when 20 then '20部门'
when 30 then '30部门'
when 40 then '40部门'
else '没有该部门'
end
from emp;
case的第二种表达式如下图
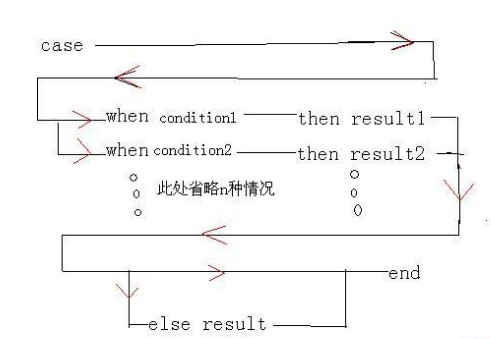
select ename,deptno,sal,
case www.2cto.com
when sal between 1000 and 2000 then '工资比较低'
when sal >2000 and sal<3000 then '工资还可以'
when not sal <3000 then '工资比较高'
else '工资太低啦'
end as salary
from emp order by sal;
group by
group by 与不带group by的查询语句的区别在于:不带group by的
情况下我们select跟的表达式无论是什么,都只是对满足where条件一行数据进行操做,利用group by根据某列内容对数据进行分组后我们可以对该组进行一些数据的统计与查询,例如统计该组的总数,查询该组的最大值平均值等内容
利用group by是有限制的,即select后面跟的列只能是两种情况
一是按照该列分组,而是对该列使用了分组函数(count sum max min avg median stats_mode stddev variance)
select count(*),avg(sal),deptno from emp group by deptno;
结果如下
COUNT(*) AVG(SAL) DEPTNO
---------- ---------- ----------
6 1566.66667 30
5 2175 20
3 2916.66667 10
having
group by 将数据按照某列进行分组后,有的组并不是我们想要的,这个时候可以通过having对组进行过滤,例如想得到部门员工数大于5人的部门,则可以
select count(ename) ,deptno from emp group by deptno having count(ename)>5;
结果如下 www.2cto.com
COUNT(ENAME) DEPTNO
------------ ----------
6 30
只显示了员工人数大于5的部门,having将人数小于等于5的部门过滤掉了
where与having的区别
虽然都是起着过滤的作用,但是where针对的是一行数据,having针对的是一组数据,where可以决定返回哪个行,having可以决定返回哪一组,同时在where子句中不允许使用分组函数,但是在having子句中可以使用非分组函数
select deptno ,count(*) from emp group by deptno having deptno>20;
但是这样的语句执行效率低于下面的写法
select count(*) ,deptno from emp where deptno>20 group by deptno;
查询中用到的关键词主要包含六个,并且他们的顺序依次为
select--from--where--group by--having--order by
其中select和from是必须的,其他关键词是可选的,这六个关键词的执行顺序
与sql语句的书写顺序并不是一样的,而是按照下面的顺序来执行
from--where--group by--having--select--order by,
from:需要从哪个数据表检索数据
where:过滤表中数据的条件
group by:如何将上面过滤出的数据分组
having:对上面已经分组的数据进行过滤的条件
select:查看结果集中的哪个列,或列的计算结果
order by :按照什么样的顺序来查看返回的数据
select关键字 www.2cto.com
1、用*代替所有列
select * from emp;
2、指定需要返回的列
select ename,deptno ,job from emp;
3、为列取别名
select ename emloyee_name,job ,deptno from emp;
4、去除某列中的相同数据
select distinct deptno ,job from emp;
5、返回两个列进行运算后的数据
create table tab1(first_col number(3),second_col number(3));
insert into tab1 values(3,6);
insert into tab1 values(1,10);
select first_col,second_col,first_col+second_col from tab1;
返回结果如下
FIRST_COL SECOND_COL FIRST_COL+SECOND_COL
---------- ---------- --------------------
3 6 9
1 10 11
6、对单列进行运算后返回
select first_col,second_col,first_col*10 from tab1;
结果如下
FIRST_COL SECOND_COL FIRST_COL*10
---------- ---------- ------------
3 6 30
1 10 10
7、select 1+2 from dept;
返回结果如下
www.2cto.com
1+2
---------
3
3
3
3
这样的查询似乎看起来没有什么意义,出现四行是因为有四个部门,对每个部门
都要执行一次1+2并且返回。
假设建立一个表只有一条数据那么将只会返回一条数据,在oracle内部就存在这
样一个表dual,以前我们经常会看到这样的语句
select sysdate from dual;
SYSDATE
--------------
05-8月 -12
即返回系统日期
假如执行这样的语句,利用上面建立的表tab1
select sysdate from tab1;
看看结果会是什么
SYSDATE
-----------
05-8月 -12
05-8月 -12
返回了两个日期,因为表tab1中有两条数据,这也可以说明返回的数据只是一个
常量,并不是从dual表中取得的,
只是利用了dual表中有一条数据的特点,这个表完全可以自己建立,也会取得和
www.2cto.com
dual一样的效果
where关键字
一个简单的查询条件一般包含一个比较运算符(< <= > >+ = <>)
由比较运算符组成的语句能够判断为true和false,当为true时,则说明该行符
合条件,作为用户检索的数据返回给用户,例如
select * from emp where sal>4000;
order by关键字
如果想要检索返回的数据按照一定的顺序排列,就需要使用order by关键词,
select * from emp order by ename desc nulls last;
select * from emp order by ename asc nulls first;
其中asc是指按照指定的列按照升序排列,desc按降序排列,nulls first指将为
空的行显示在最前面,
nulls last是指将为空的数据所在行显示在最后,对于升序排列nulls last为默
认,如果按照降序排列nulls first 为默认
例如
select * from emp order by comm ;等价于
select * from emp order by comm asc nulls last;
select * from emp order by comm desc;等价于
select * from emp order by comm desc nulls first;
如果按照多个字段排序
select * from emp order by deptno asc,ename desc;
会先按照deptno进行升序排列,相同的deptno按照姓名的降序排列
运算符and or not
两个条件分别进行判断为true或者false
true or ...-->true
true and true-->true
false or false-->false
false and...-->false
例如
select 'true or false' from dual where (1=0) or (1=1);
返回结果为
'TRUEORFALSE'
-------------
true or false
select 'true or false' from dual where (1=0) and (1=1);
返回 no rows selected
对于not运算符可以放在任何一个条件面前,将true和和false反转
例如 www.2cto.com
select * from emp where deptno>20;
select * from emp where not deptno>20;(注意not必须放在整个条件的前面)
运算符between in like
between运算符是用一个范围值对数据进行过滤,这个范围两边是闭区间的
例如
select * from emp where sal between 2850 and 4000;
between运算符
in运算符是让某个列的值或者通过表达式运算出的结果和几个单独的值列表进行
比较,例如
select * from emp where sal in (2850,3000,5000);
like运算符,like运算符后面的表达式可以有几种情况
'%ab' 列的值最后两个字母是ab
'%ab%'列的值中包含ab,注意ab是一体的
'ab%' 列的值最开始两个字母是ab
'_ab%'列的值第二三个字母是ab,其中_为占位符,一个_占一位
select * from emp where ename like '_MI%';
case表达式,简单的语法格式如下图
例如
select ename ,case deptno
when 10 then '10部门'
when 20 then '20部门'
when 30 then '30部门'
when 40 then '40部门'
else '没有该部门'
end
from emp;
case的第二种表达式如下图
select ename,deptno,sal,
case www.2cto.com
when sal between 1000 and 2000 then '工资比较低'
when sal >2000 and sal<3000 then '工资还可以'
when not sal <3000 then '工资比较高'
else '工资太低啦'
end as salary
from emp order by sal;
group by
group by 与不带group by的查询语句的区别在于:不带group by的
情况下我们select跟的表达式无论是什么,都只是对满足where条件一行数据进行操做,利用group by根据某列内容对数据进行分组后我们可以对该组进行一些数据的统计与查询,例如统计该组的总数,查询该组的最大值平均值等内容
利用group by是有限制的,即select后面跟的列只能是两种情况
一是按照该列分组,而是对该列使用了分组函数(count sum max min avg median stats_mode stddev variance)
select count(*),avg(sal),deptno from emp group by deptno;
结果如下
COUNT(*) AVG(SAL) DEPTNO
---------- ---------- ----------
6 1566.66667 30
5 2175 20
3 2916.66667 10
having
group by 将数据按照某列进行分组后,有的组并不是我们想要的,这个时候可以通过having对组进行过滤,例如想得到部门员工数大于5人的部门,则可以
select count(ename) ,deptno from emp group by deptno having count(ename)>5;
结果如下 www.2cto.com
COUNT(ENAME) DEPTNO
------------ ----------
6 30
只显示了员工人数大于5的部门,having将人数小于等于5的部门过滤掉了
where与having的区别
虽然都是起着过滤的作用,但是where针对的是一行数据,having针对的是一组数据,where可以决定返回哪个行,having可以决定返回哪一组,同时在where子句中不允许使用分组函数,但是在having子句中可以使用非分组函数
select deptno ,count(*) from emp group by deptno having deptno>20;
但是这样的语句执行效率低于下面的写法
select count(*) ,deptno from emp where deptno>20 group by deptno;

相关文章推荐
- oracle查询语句中select from where group by having order by的解释与应用
- oracle查询语句中select from where group by having order by的解释与应用
- 查询语句中select from where group by having order by的执行顺序
- 查询语句中select from where group by having order by的执行顺序
- 查询语句中select from where group by having order by的执行顺序
- 查询语句中select from where group by having order by的执行顺序
- SQL查询语句中select from where group by having order by的执行顺序
- 查询语句中select from where group by having order by的执行顺序
- 查询语句中select from where group by having order by的执行顺序
- 查询语句中select from where group by having order by的执行顺序
- 查询语句中select from where group by having order by的执行顺序
- 查询语句中select from where group by having order by的执行顺序
- 查询语句中select from where group by having order by的执行顺序
- 查询语句中select from where group by having order by的执行顺序
- Oracle基础知识(5)--select...from...where...group by...having...order by...
- SQL Server 和 MySQL中 from where group by having order select 执行顺序
- oracle 基础SQL语句 多表查询 子查询 分页查询 合并查询 分组查询 group by having order by
- select ... from ... where ... group by ... having ... order by ...
- sql篇 select from where group by having order by
- LINQ查询操作符之Select、Where、OrderBy、OrderByDescending、GroupBy、Join、GroupJoin及其对应的查询语法