控制sql语句查询出来的浮点类型数据小数点后的位数
2012-07-16 16:22
507 查看
实验前提:1、本次实验实验的是RHEL6.4(64bit)的系统2、确保每台服务器时间同步3、本次实验共有4台服务器,其相关的地址为:haproxy1:192.168.108.230haproxy2:192.168.108.231web1:192.168.108.199web2:192.168.108.201VIP:192.168.108.111 实验拓扑结构为:
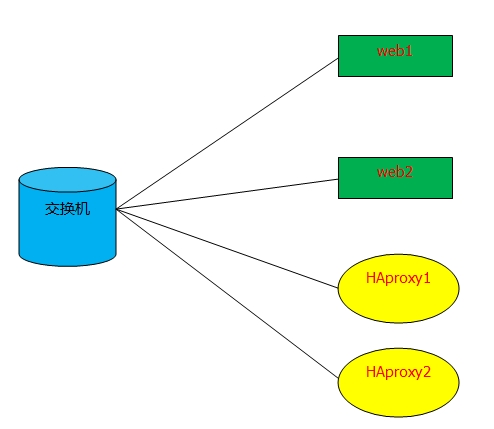
一、编译安装keepalived1、在两台haproxy(1和2上)上编译安装keepalived# tar xf keepalived-1.2.13.tar.gz# cd keepalived-1.2.13# ./configure –prefix=/# make && make install# chkconfig --add keepalived# chkconfig keepalived on 2、在haproxy1修改配置文件/etc/keepalived/keepalived.conf内容为如下:! Configuration File for keepalived global_defs { notification_email { xsl@localhost } notification_email_from root@localhost smtp_server 127.0.0.1 smtp_connect_timeout 120 router_id haproxy1} vrrp_instance web { state MASTER #haproxy1这台服务器为MASTER interface eth0 virtual_router_id 200 priority 100 #优先级为100 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.108.111 #虚拟ip地址为192.168.108.111 }} 3、将haproxy1上的配置文件/etc/keepalived/keepalived.conf复制给haproxy2# scp /etc/keepalived/keepalived.conf 192.168.108.231:/etc/keepalived/复制完成后,还需要在haproxy2修改这个配置文件的如下参数:router_id haproxy2state BACKUPpriority 90 4、修改完成后再haproxy1和haproxy2启动keepalived服务# service keepalived start 5、观察haproxy上是否有VIP地址# ip addr show1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo inet6 ::1/128 scope host valid_lft forever preferred_lft forever2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 00:0c:29:5f:a5:e3 brd ff:ff:ff:ff:ff:ff inet 192.168.108.230/24 brd 192.168.108.255 scope global eth0 inet 192.168.108.111/32 scope global eth0 #VIP地址已经有了 inet6 fe80::20c:29ff:fe5f:a5e3/64 scope link valid_lft forever preferred_lft forever 至此,keepalived的核心配置已经完成了。 二、配置安装haproxy由于在RHEL6.4系统平台上自带了haproxy的RPM包。因此,在这里我就使用RPM包的方式来安装haproxy。说明:以下步骤需要在两台服务器都完成的1、安装haproxy软件包# yum –y install haproxy# chkconfig haproxy on 2、修改器配置文件/etc/haproxy/haproxy.cfg为如下内容:global log 127.0.0.1 local2 chroot /var/lib/haproxy pidfile /var/run/haproxy.pid maxconn 4000 user haproxy group haproxy daemon # turn on stats unix socketstats socket /var/lib/haproxy/stats defaults mode http log global option httplog option dontlognull option http-server-close option forwardfor except 127.0.0.0/8 option redispatch retries 3 timeout http-request 10s timeout queue 1m timeout connect 10s timeout client 1m timeout server 1m timeout http-keep-alive 10s timeout check 10s maxconn 3000 frontend healthcheck bind 192.168.108.111:80 mode http option httpclose option forwardfor default_backend webserver backend webserver balance roundrobin server web1 192.168.108.199:80 inter 1000 rise 1 fall 2 check maxconn 2000 server web2 192.168.108.201:80 inter 1000 rise 1 fall 2 check maxconn 2000 3、添加日志文件编辑/etc/sysconfig/rsyslog,修改SYSLOGD_OPTIONS="-c 5"为SYSLOGD_OPTIONS="-c 2"然后再编辑/etc/rsyslog.conf,添加如下行信息:local2.* /var/log/haproxy.log 最后,重启2台服务器上的rsyslog服务# service rsyslog restart 三、配置安装后端web服务器说明:以下步骤需要在两台web服务器上都完成1、安装httpd# yum –y install httpd 2、修改站点根目录下的默认文件index.html的内容为如下:hello <h1>web1</h1> My ip is 192.168.108.199 注意:这是web1上的index.html文件的内容hello <h1>web2</h1> My ip is 192.168.108.201 注意:这是web2上的index.html文件的内容 四、测试说明:在测试时,请关闭所有服务器上的防火墙(执行iptables –F即可)和关闭selinux(执行getenforce 0即可)在浏览器上输入:http://192.168.108.111/,显示结果如下:
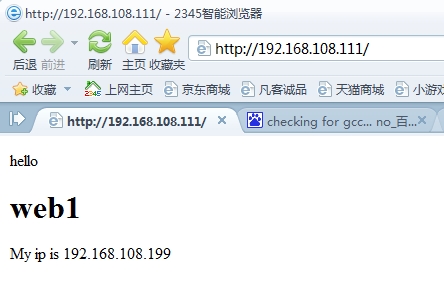
然后再执行刷新操作,显示结果如下:

默认haproxy采用的调度算法为加权轮调,因此,客户端的请求会均分的发送给后端的服务器进行处理。 五、为haproxy提供基于web界面的统计报告功能需要在两台haproxy服务器的配置文件添加如下信息:listen stats mode http bind 0.0.0.0:8080 stats enable stats hide-version stats uri /haproxyadmin?stats #访问时指定的uri stats realm "hello\ haproxy" stats auth xsl:xsl stats admin if TRUE 然后创建用户xsl# useradd xsl# passwd xsl 测试,访问http://192.168.108.111:8080/ haproxyadmin?stats,显示结果如下:

通过以上步骤,基于keepalived+haproxy实现httpd的高可用服务已经成功实现 六、通过检测脚本来实现MASTER/BACKUP的切换(可选部分)需要在两台haproxy服务器上编辑/etc/keepalived/keepalived.conf,添加如下内容:vrrp_script chk_haproxy {“[[ -f /etc/keepalived/down ]] && exit 1 || exit 0” interval 2 表示每隔2秒检测一次weight 20 如果/etc/keepalived/down文件存在,则这台服务器的优先级降低20fall 2 如果检测2次该服务器都不在是MASTER的话,则认为该服务器不在是MASTERrise 1 如果检测到一次该服务器成为MASTER,则认为该服务器成为MASTER}track_script { #这一段的配置需要配置在实例中 chk_haproxy} 测试,在作为MASTER的服务器上(此处为haproxy1)创建文件/etc/keepalived/down,观察VIP是否飘移到haproxy上了。# touch /etc/keepalived/down# ip addr show1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo inet6 ::1/128 scope host valid_lft forever preferred_lft forever2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 00:0c:29:5f:a5:e3 brd ff:ff:ff:ff:ff:ff inet 192.168.108.230/24 brd 192.168.108.255 scope global eth0 inet6 fe80::20c:29ff:fe5f:a5e3/64 scope link valid_lft forever preferred_lft forever上述结果可以看出,VIP已经不在haproxy1上了,此时haproxy不在作为MASTER服务器。在haproxy2上观察是否有VIP,需要执行如下命令即可观察VIP是否已经存在:# ip addr show1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo inet6 ::1/128 scope host valid_lft forever preferred_lft forever2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 00:0c:29:70:89:f4 brd ff:ff:ff:ff:ff:ff inet 192.168.108.231/24 brd 192.168.108.255 scope global eth0 inet 192.168.108.111/32 scope global eth0 inet6 fe80::20c:29ff:fe70:89f4/64 scope link valid_lft forever preferred_lft forever由此可以看出,haproxy2上已经有了VIP,此时haproxy将作为MASTER服务器来接受和转发请求。通过上述步骤,就可以实现手动完成MASTER/BACKUP的切换了,这样就不需要使用停止keepalived服务的方式来进行切换。
七、当keepalived与nginx或haproxy实现高可用时,如果nginx或haproxy服务本身不可用,此时将无法处理客户端请求,因此也必须实现主从切换,这个过程该如何实现?
其实这个过程和之前自写脚本完成MASTER/BACKUP切换过程是一样的。以haproxy为例,其配置如下:vrrp_script haproxy_check { script "killall -0 haproxy" //这个命令用来测试haproxy这个进程是否存在,不会真正执行 interval 2 weight -2}track_script { haproxy_check}
八、当VRRP切换事务发生时,如何发送警告给指定的管理员?
在所有的keepalived上服务器上修改配置文件,并添加如下配置
notify_master "/etc/keepalived/notify.sh master"
notify_backup "/etc/keepalived/notify.sh backup"
notify_fault "/etc/keepalived/notify.sh fault"这段配置是配置在vrrp_instance web {}实例中的
然后在每台keepalived服务器上创建如下脚本文件编写通知脚本
#vim notify.sh通知脚本如下:
#vim notify.sh
#!/bin/bash#author:xsl
#description: An example of notify script
#vip=192.168.108.111
contact='root@localhost'notify() {
mailsubjiect="`hostname` is to be $1 ,$vip floating" #这里是邮件的主题
mailbody="`date '+%F %H:%M:%S'`:vrrp transition,`hostname` changed to be $1 "
echo $mailbody | mail -s "$mailsubject" $contact
}case $1 in
master)
notify master
/etc/rc.d/init.d/haproxy start
exit 0
;;
backup)
notify backup
/etc/rc.d/init.d/haproxy stop
exit 0
;;
fault)
notify fault /etc/rc.d/init.d/haproxy stop
exit 0
;;
*)
echo "usage:`basename $0` {master|backup|fault}"
exit 1
;;
esac 给脚本加执行权限
#chmod +x notify.sh
测试,在haproxy1节点上添加down文件#touch /etc/keepalived/down 查看虚拟IP地址是否还位于haproxy1上
#ip addr show如果虚拟ip地址不存在了,则表示操作都成功了。一旦发生主从切换,root用户应该可以收到相关的邮件信息了。
本文出自 “linux学习之路” 博客,转载请与作者联系!
一、编译安装keepalived1、在两台haproxy(1和2上)上编译安装keepalived# tar xf keepalived-1.2.13.tar.gz# cd keepalived-1.2.13# ./configure –prefix=/# make && make install# chkconfig --add keepalived# chkconfig keepalived on 2、在haproxy1修改配置文件/etc/keepalived/keepalived.conf内容为如下:! Configuration File for keepalived global_defs { notification_email { xsl@localhost } notification_email_from root@localhost smtp_server 127.0.0.1 smtp_connect_timeout 120 router_id haproxy1} vrrp_instance web { state MASTER #haproxy1这台服务器为MASTER interface eth0 virtual_router_id 200 priority 100 #优先级为100 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.108.111 #虚拟ip地址为192.168.108.111 }} 3、将haproxy1上的配置文件/etc/keepalived/keepalived.conf复制给haproxy2# scp /etc/keepalived/keepalived.conf 192.168.108.231:/etc/keepalived/复制完成后,还需要在haproxy2修改这个配置文件的如下参数:router_id haproxy2state BACKUPpriority 90 4、修改完成后再haproxy1和haproxy2启动keepalived服务# service keepalived start 5、观察haproxy上是否有VIP地址# ip addr show1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo inet6 ::1/128 scope host valid_lft forever preferred_lft forever2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 00:0c:29:5f:a5:e3 brd ff:ff:ff:ff:ff:ff inet 192.168.108.230/24 brd 192.168.108.255 scope global eth0 inet 192.168.108.111/32 scope global eth0 #VIP地址已经有了 inet6 fe80::20c:29ff:fe5f:a5e3/64 scope link valid_lft forever preferred_lft forever 至此,keepalived的核心配置已经完成了。 二、配置安装haproxy由于在RHEL6.4系统平台上自带了haproxy的RPM包。因此,在这里我就使用RPM包的方式来安装haproxy。说明:以下步骤需要在两台服务器都完成的1、安装haproxy软件包# yum –y install haproxy# chkconfig haproxy on 2、修改器配置文件/etc/haproxy/haproxy.cfg为如下内容:global log 127.0.0.1 local2 chroot /var/lib/haproxy pidfile /var/run/haproxy.pid maxconn 4000 user haproxy group haproxy daemon # turn on stats unix socketstats socket /var/lib/haproxy/stats defaults mode http log global option httplog option dontlognull option http-server-close option forwardfor except 127.0.0.0/8 option redispatch retries 3 timeout http-request 10s timeout queue 1m timeout connect 10s timeout client 1m timeout server 1m timeout http-keep-alive 10s timeout check 10s maxconn 3000 frontend healthcheck bind 192.168.108.111:80 mode http option httpclose option forwardfor default_backend webserver backend webserver balance roundrobin server web1 192.168.108.199:80 inter 1000 rise 1 fall 2 check maxconn 2000 server web2 192.168.108.201:80 inter 1000 rise 1 fall 2 check maxconn 2000 3、添加日志文件编辑/etc/sysconfig/rsyslog,修改SYSLOGD_OPTIONS="-c 5"为SYSLOGD_OPTIONS="-c 2"然后再编辑/etc/rsyslog.conf,添加如下行信息:local2.* /var/log/haproxy.log 最后,重启2台服务器上的rsyslog服务# service rsyslog restart 三、配置安装后端web服务器说明:以下步骤需要在两台web服务器上都完成1、安装httpd# yum –y install httpd 2、修改站点根目录下的默认文件index.html的内容为如下:hello <h1>web1</h1> My ip is 192.168.108.199 注意:这是web1上的index.html文件的内容hello <h1>web2</h1> My ip is 192.168.108.201 注意:这是web2上的index.html文件的内容 四、测试说明:在测试时,请关闭所有服务器上的防火墙(执行iptables –F即可)和关闭selinux(执行getenforce 0即可)在浏览器上输入:http://192.168.108.111/,显示结果如下:
然后再执行刷新操作,显示结果如下:
默认haproxy采用的调度算法为加权轮调,因此,客户端的请求会均分的发送给后端的服务器进行处理。 五、为haproxy提供基于web界面的统计报告功能需要在两台haproxy服务器的配置文件添加如下信息:listen stats mode http bind 0.0.0.0:8080 stats enable stats hide-version stats uri /haproxyadmin?stats #访问时指定的uri stats realm "hello\ haproxy" stats auth xsl:xsl stats admin if TRUE 然后创建用户xsl# useradd xsl# passwd xsl 测试,访问http://192.168.108.111:8080/ haproxyadmin?stats,显示结果如下:
通过以上步骤,基于keepalived+haproxy实现httpd的高可用服务已经成功实现 六、通过检测脚本来实现MASTER/BACKUP的切换(可选部分)需要在两台haproxy服务器上编辑/etc/keepalived/keepalived.conf,添加如下内容:vrrp_script chk_haproxy {“[[ -f /etc/keepalived/down ]] && exit 1 || exit 0” interval 2 表示每隔2秒检测一次weight 20 如果/etc/keepalived/down文件存在,则这台服务器的优先级降低20fall 2 如果检测2次该服务器都不在是MASTER的话,则认为该服务器不在是MASTERrise 1 如果检测到一次该服务器成为MASTER,则认为该服务器成为MASTER}track_script { #这一段的配置需要配置在实例中 chk_haproxy} 测试,在作为MASTER的服务器上(此处为haproxy1)创建文件/etc/keepalived/down,观察VIP是否飘移到haproxy上了。# touch /etc/keepalived/down# ip addr show1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo inet6 ::1/128 scope host valid_lft forever preferred_lft forever2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 00:0c:29:5f:a5:e3 brd ff:ff:ff:ff:ff:ff inet 192.168.108.230/24 brd 192.168.108.255 scope global eth0 inet6 fe80::20c:29ff:fe5f:a5e3/64 scope link valid_lft forever preferred_lft forever上述结果可以看出,VIP已经不在haproxy1上了,此时haproxy不在作为MASTER服务器。在haproxy2上观察是否有VIP,需要执行如下命令即可观察VIP是否已经存在:# ip addr show1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo inet6 ::1/128 scope host valid_lft forever preferred_lft forever2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 00:0c:29:70:89:f4 brd ff:ff:ff:ff:ff:ff inet 192.168.108.231/24 brd 192.168.108.255 scope global eth0 inet 192.168.108.111/32 scope global eth0 inet6 fe80::20c:29ff:fe70:89f4/64 scope link valid_lft forever preferred_lft forever由此可以看出,haproxy2上已经有了VIP,此时haproxy将作为MASTER服务器来接受和转发请求。通过上述步骤,就可以实现手动完成MASTER/BACKUP的切换了,这样就不需要使用停止keepalived服务的方式来进行切换。
七、当keepalived与nginx或haproxy实现高可用时,如果nginx或haproxy服务本身不可用,此时将无法处理客户端请求,因此也必须实现主从切换,这个过程该如何实现?
其实这个过程和之前自写脚本完成MASTER/BACKUP切换过程是一样的。以haproxy为例,其配置如下:vrrp_script haproxy_check { script "killall -0 haproxy" //这个命令用来测试haproxy这个进程是否存在,不会真正执行 interval 2 weight -2}track_script { haproxy_check}
八、当VRRP切换事务发生时,如何发送警告给指定的管理员?
在所有的keepalived上服务器上修改配置文件,并添加如下配置
notify_master "/etc/keepalived/notify.sh master"
notify_backup "/etc/keepalived/notify.sh backup"
notify_fault "/etc/keepalived/notify.sh fault"这段配置是配置在vrrp_instance web {}实例中的
然后在每台keepalived服务器上创建如下脚本文件编写通知脚本
#vim notify.sh通知脚本如下:
#vim notify.sh
#!/bin/bash#author:xsl
#description: An example of notify script
#vip=192.168.108.111
contact='root@localhost'notify() {
mailsubjiect="`hostname` is to be $1 ,$vip floating" #这里是邮件的主题
mailbody="`date '+%F %H:%M:%S'`:vrrp transition,`hostname` changed to be $1 "
echo $mailbody | mail -s "$mailsubject" $contact
}case $1 in
master)
notify master
/etc/rc.d/init.d/haproxy start
exit 0
;;
backup)
notify backup
/etc/rc.d/init.d/haproxy stop
exit 0
;;
fault)
notify fault /etc/rc.d/init.d/haproxy stop
exit 0
;;
*)
echo "usage:`basename $0` {master|backup|fault}"
exit 1
;;
esac 给脚本加执行权限
#chmod +x notify.sh
测试,在haproxy1节点上添加down文件#touch /etc/keepalived/down 查看虚拟IP地址是否还位于haproxy1上
#ip addr show如果虚拟ip地址不存在了,则表示操作都成功了。一旦发生主从切换,root用户应该可以收到相关的邮件信息了。
本文出自 “linux学习之路” 博客,转载请与作者联系!

相关文章推荐
- 控制sql语句查询出来的浮点类型数据小数点后的位数
- Oracle Class2. SQL查询和SQL函数(Oracle数据类型,ddl,dml,dcl,事务控制语言tcl,sql操作符,sql函数,select语句,运算符,分析函数,临时表)
- C#Access数据应用Sql语句查询数据小数位数处理
- sql server 查询表信息,字段,数据类型的sql语句
- android中常用的查询、插入、更新、删除等SQL语句以及SQLite数据类型
- Mysql数据库理论基础之三 --- 数据类型及SQL结构化查询语句使用
- Informix数据表结构分析资料整理之字段类型说明和查询SQL语句
- Linux命令:MySQL系列之三--mysql数据类型及SQL结构化查询语句使用
- PL/SQL-数据类型、变量、控制语句
- 如何用SQL语句查询一个数据表所有字段的类型
- Informix数据表结构分析资料整理之字段类型说明和查询SQL语句
- 用一个Sql语句查询出表中的一个字段的数据类型
- 在Cout 输出浮点数据里控制小数点后数字位数
- Informix数据表结构分析资料整理之字段类型说明和查询SQL语句
- SQL语句:orac 3ff0 le中如何插入Date类型的数据和根据Date数据进行查询的方法
- Informix数据表结构分析资料整理之字段类型说明和查询SQL语句
- SQLServer中查询表结构(表主键 、列说明、列数据类型、所有表名)的Sql语句
- SQLServer中查询表结构(表主键 、列说明、列数据类型、所有表名)的Sql语句
- Informix数据表结构分析资料整理之字段类型说明和查询SQL语句
- pb中sql语句用to_char查询出来数据,居然无法检索出数据,oracle数据库,这是什么原因?