Google搜索引擎的奥秘
2012-06-18 20:35
211 查看
1、背景和问题
据统计超过80%的用户靠搜索引擎获取信息网站排名是网络搜索引擎的核心
目前Google数据库存储上百亿网页信息, 每天提供查询服务达到3亿多次
2、google查询过程示意图

3、Google搜索的核心算法
PageRank是 Google 用于评价一个网页的重要性的一种方法. 通过该方法, Google 将各个网站进行排名. 用户进行相关搜索时, Google 会将符合条件的网站按排名顺序输出.PageRank 算法中使用的数学知识包括:正矩阵性质、特征值和特征向量、幂迭代算法、Gauss-Seidel迭代算法等.
PageRank 得分是介于 0 和 1 之间的一个数,得分越大表示网页越重要.
4、PageRank算法思想简介
1)、 PageRank基于假设关系“许多优质的网页中超链接的网页,必定是优质网页”,以此判定所有网页的重要性。
重要性由该网页被访问的概率大小来刻画。
导入链接:单纯意义上的受欢迎度指标
导入链接是否来自受欢迎程度高的:有根据的受欢迎指标
导入链接源页面的导出链接:被选中的概率指标
2)、PageRank 是基于这样一个理论:
若 B 网页上有连接到 A 网页的链接( 称 B 为 A 的导入链接 ), 说明 B 认为 A 有链接价值,是一个“重要”的网页. 当 B 网页级别 ( 重要性 ) 比较高时, 则A 网页可从 B 网页这个导入链接分得一定的级别 ( 重要性 ), 并平均分配给 A 网页上的所有导出链接.(导出链接就是网站或者页面中有指向别的网站的链接)
在PageRank算法中, 一个网页的级别(重要性)大致由下面两个因素决定:该网页的导入链接的数量和这些导入链接的级别(重要性).
5、PageRank计算
1)、邻接矩阵互联网是一个有向图
每一个网页是图的一个顶点
网页间的每一个超链接是图的一个有向边
用邻接矩阵G来表示有向图, 即,若网页j到网页i有超链接, 则gij=1, 否则为gij=0.
邻接矩阵是一个十分庞大有相当稀疏的方阵(用黑色代表1, 用白色代表0)
用邻接矩阵G来表示图, 即,若网页j到网页i有超链接, 则gij=1, 否则为gij=0.
定义矩阵G的列和与行和

其中 cj(列和) 是页面j的导出链接数目,
ri(行和) 是页面
i 的导入链接数目.
2)、转移概率矩阵
假设我们在上网的时候浏览页面并选择下一个页面, 这个过程与过去浏览过哪些页面无关, 而仅依赖于当前所在的页面, 那么这一选择过程可以认为是一个有限状态、离散时间的随机过程, 其状态转移规律可用Markov链描述.
定义转移概率矩阵
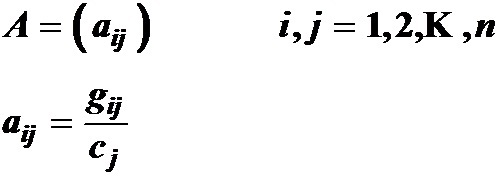
3)、85%与15%
但还要考虑到用户虽然在许多场合都顺着当前页面中的链接前进, 但时常又会跳跃到完全无关的页面.
经过统计, Google采用个15%来表示[时常], 即用户在85%的情况下沿着链接前进, 但有15%的情况下突然跳跃到无关的页面中去.
从而修正状态转移矩阵

4)、网页的最终PageRank值.
根据Markov链的基本性质,以上A' 是一个正则Markov链, 存在平稳分布x= (x1,x2,x3,
...,xm),满足

x表示在极限状态(转移次数趋于无限)下各网页被访问的概率分布.
x定义为网页的PageRank向量, xi
表示第 i 个网页的PageRank值. 显然概率越大, 其重要性越高是合理的.
分量 x 应满足方程
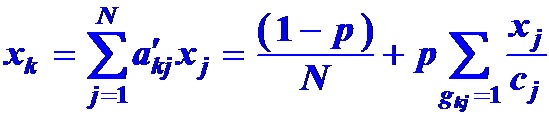
从另一角度看, 网页 j 将它的PageRank值xj 分成cj份, 分别“投票”给它链出的网页.
网页k 的PageRank值 xk就是所有页面投票给网页k的最终值.
5)、解的讨论
由Markov性质, A' 的最大特征值是1, 即求特征值1对应的特征向量.
问:上述方程组的解是否唯一解?解是否有意义(即不会出现负数或大于1的数)?
答:上述方程组的解唯一且分量都大于0!
理由:Perron-Frobnius 定理.
6、Perron-Frobnius 定理
1)、如果 A 是正的方阵(所有元素均大于0), 则A 的谱半径 r(A)>0,其中l1,l2, ... ,ln 为A 的特征值。
l =r (A) 是A 的特征值, 且代数重数为 1, 即为单特征值。
存在唯一的 x >0, 满足
A x = x, 且
若l 是A 的特征值, 且l ¹r (A), 则|l| <r(A) .
2)、l = 1 是 A 的特征值(Ax=x)的简单证明

7、网页排名举例
例:用PageRank 算法计算下面的小型网络中各网页的排名, 其中取p=0.85.
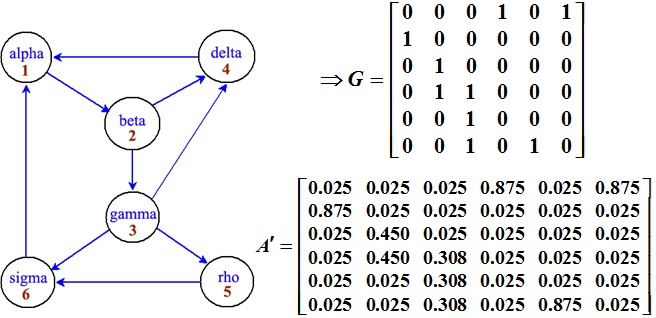
解得
x = (0.2675, 0.2524, 0.1323, 0.1698, 0.0625, 0.1156)T
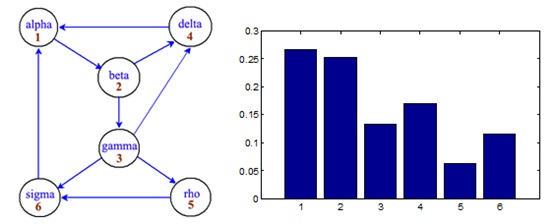
网页1的重要性最高, 虽然2的导入链接数只有1, 但却是网页1唯一的外链, 所以其重要性也显著提高!
网页3虽是网页2的外链, 但只能得到网页2一半的分数.
事实上, 问题还不是这么简单!
Google要面对上百亿的网页, 计算量特别大,尤其计算特征值Ax=x对计算能力要求特别高,需要关注计算的复杂度,这里用到许多数值计算工具。
此外还要讨论网页的索引、查询等方法。
参考资料:google查询搜索图示过程

相关文章推荐
- Google搜索引擎的奥秘
- Google搜索引擎的奥秘
- 探索Google App Engine背后的奥秘(5)- Datastore的设计
- 几个主要搜索引擎(Google和百度、雅虎)的站内搜索代码
- Google搜索引擎的使用技巧
- 微软做搜索引擎拼不过Google的真正原因
- google 搜索引擎的关键字
- 修改Chrome默认搜索引擎为Google.com
- 手把手教你把你的店铺放到google、百度、搜狐、一搜等大型搜索引擎上去
- 挑战Google!传Facebook与Yahoo要联手开发搜索引擎
- 如何使用google等一系列搜索引擎?
- 搜索引擎查询层的主要检索质量优化的方法,在参加完google的互联网大会后的总结
- 如何使用好搜索引擎(Google,Baidu)
- 新型智能搜索引擎,挑战google
- google 搜索引擎居然屏蔽"屁股"一词
- libibase - 实时增量全文检索搜索引擎系统(Instant and Incremental Full-Text Search Engine) - Google Project Hosting
- 搜索引擎 查询参数汇总(google、baidu、yahoo) 继续更新中。。
- 探索Google App Engine背后的奥秘(1)--Google的核心技术
- Google搜索引擎技术实现探究(化柏林)
- 探索Google App Engine背后的奥秘(4)- Google App Engine的架构