网友问题回答_百度知道的搜索结果采集
2012-05-15 19:53
267 查看
火车头论坛5-14日一个问题的解答:http://bbs.locoy.com/spider-75505-1-1.html
1、该百度知道的网址规则很容易分析,网址 http://zhidao.baidu.com/q?word=%CB%BC%D4%B4%D1%A7%D4%BA&lm=0&fr=search&ct=17&pn=0&tn=ikaslist&rn=10
中 传递的参数 "pn=0"定义的是分页号。可以发现,0表示第一页,10表示第二页,一次类推,110表示第12页。
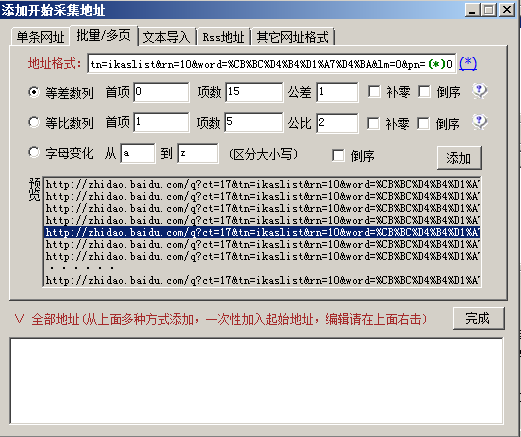
2、由上分析,在定义“采集网址规则”的时候,添加“起始网址”时可以利用等差数列实现多页网址。地址格式设置成:http://zhidao.baidu.com/q?ct=17&tn=ikaslist&rn=10&word=%CB%BC%D4%B4%D1%A7%D4%BA&lm=0&pn=(*)0
。如果采集15页,其他参数设置如图:
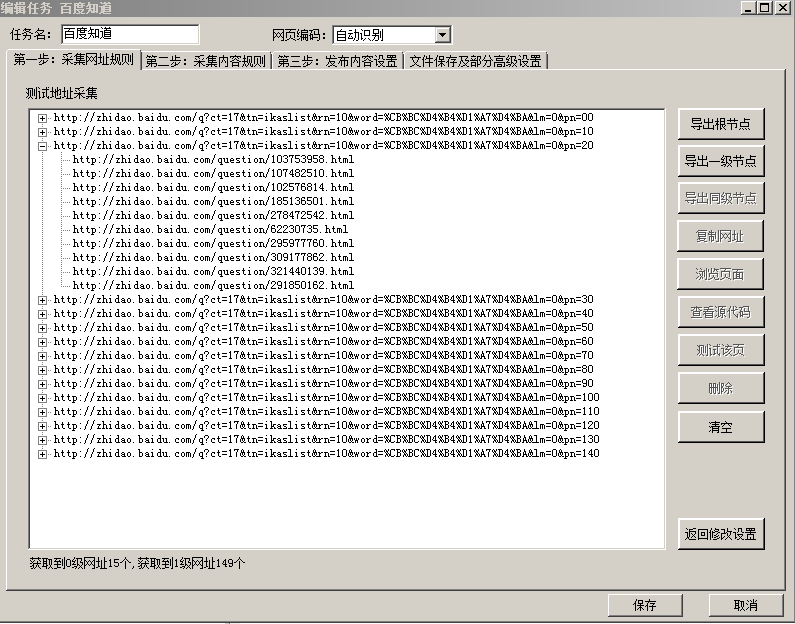
3、以上步骤定义了要采集的根页面,接下来定义每个分页的10个搜索结果的网址的规则。可以在“采集网址规则-->多级网址获取”中添加一条规则来达到目的。这里我采用从“指定区域中提取网址"的方式来实现网址的获取,如何确定区域得通过分析网址的源代码。可以任意选取一个搜索结果,打开页面并获取源代码,然后分析。
这里,我们可以得到一个区域: <table
border=0 cellpadding=0 cellspacing=0><tr><td class=f> 和 <div id="pg">;然后填写个结构过滤规则保证获取的网址是满足要求的。具体见图:

测试结果:
4、之前的步骤实现了"采集网址规则"的定义。接下来就该定义”采集内容规则“,获取每条搜索结果中有意义的内容。
由于提问者没有说明具体想要获取什么内容,我们以获取”满意答案“为目的来举例:
首先、选择任意一条搜索结果:http://zhidao.baidu.com/question/418614635.html 查看其源代码,如图。
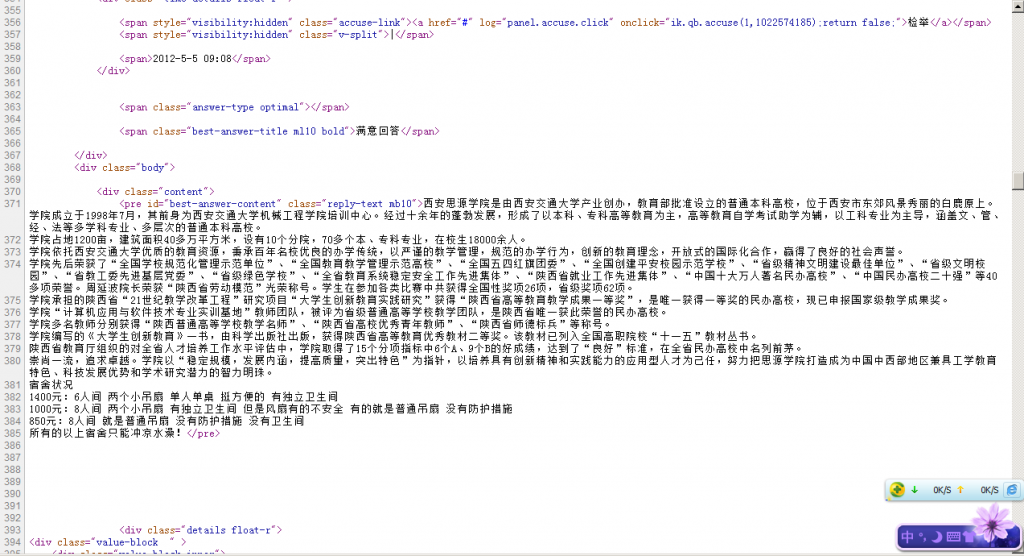
可以发现,对于每条”满意回答“,应该都有(这个就不需要证明了吧^^) <spanclass="best-answer-title ml10 bold">满意回答</span>
这个语句。于是我们可以利用“前后截取”的
数据提取方式来实现该内容的获取。开始字符串就填: <spanclass="best-answer-title
ml10 bold">满意回答</span>结尾字符串就填:</pre>
。然后添加一个“html标签排除”的数据处理规则,保存即可。
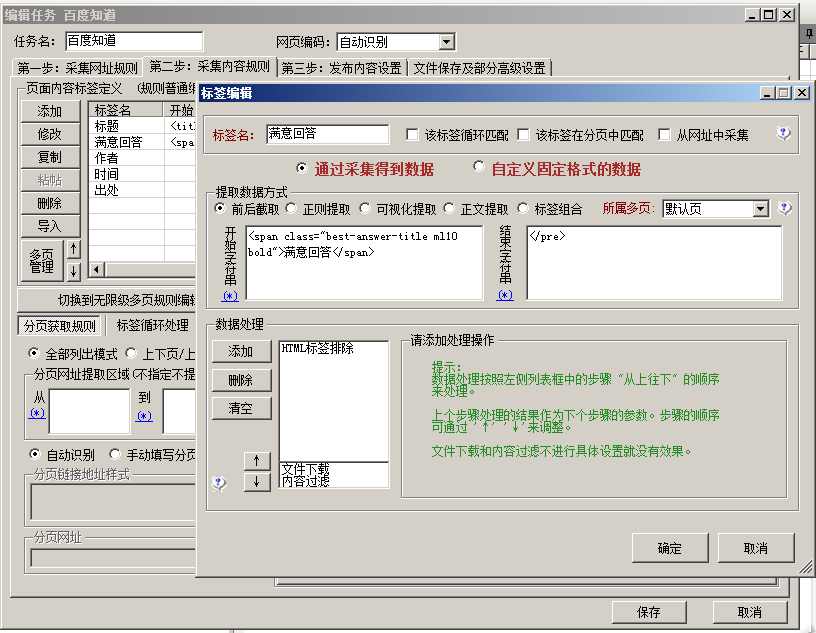
5、测试结果如下:
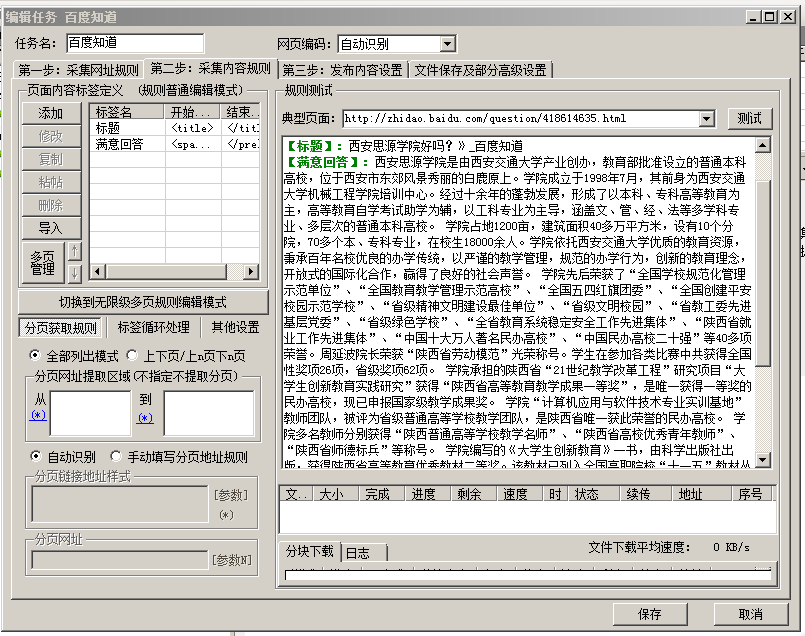
6、接下来定义一些发布规则,就可以将结构保存在数据库或文本中了。此步骤就不介绍了。
Ok, 这是这个专用博客开始的第一篇博文,写的可能有写啰嗦,例子也很简单。我也正在学习中,还请多多包涵了。大家如果还有什么问题可以在此博文后回复,我会争取一一解决。 thx!8
Q:http://zhidao.baidu.com/q?word=%CB%BC%D4%B4%D1%A7%D4%BA&lm=0&fr=search&ct=17&pn=0&tn=ikaslist&rn=10 此网址采集规则如何写?
A:1、该百度知道的网址规则很容易分析,网址 http://zhidao.baidu.com/q?word=%CB%BC%D4%B4%D1%A7%D4%BA&lm=0&fr=search&ct=17&pn=0&tn=ikaslist&rn=10
中 传递的参数 "pn=0"定义的是分页号。可以发现,0表示第一页,10表示第二页,一次类推,110表示第12页。
2、由上分析,在定义“采集网址规则”的时候,添加“起始网址”时可以利用等差数列实现多页网址。地址格式设置成:http://zhidao.baidu.com/q?ct=17&tn=ikaslist&rn=10&word=%CB%BC%D4%B4%D1%A7%D4%BA&lm=0&pn=(*)0
。如果采集15页,其他参数设置如图:
3、以上步骤定义了要采集的根页面,接下来定义每个分页的10个搜索结果的网址的规则。可以在“采集网址规则-->多级网址获取”中添加一条规则来达到目的。这里我采用从“指定区域中提取网址"的方式来实现网址的获取,如何确定区域得通过分析网址的源代码。可以任意选取一个搜索结果,打开页面并获取源代码,然后分析。
这里,我们可以得到一个区域: <table
border=0 cellpadding=0 cellspacing=0><tr><td class=f> 和 <div id="pg">;然后填写个结构过滤规则保证获取的网址是满足要求的。具体见图:
测试结果:
4、之前的步骤实现了"采集网址规则"的定义。接下来就该定义”采集内容规则“,获取每条搜索结果中有意义的内容。
由于提问者没有说明具体想要获取什么内容,我们以获取”满意答案“为目的来举例:
首先、选择任意一条搜索结果:http://zhidao.baidu.com/question/418614635.html 查看其源代码,如图。
可以发现,对于每条”满意回答“,应该都有(这个就不需要证明了吧^^) <spanclass="best-answer-title ml10 bold">满意回答</span>
这个语句。于是我们可以利用“前后截取”的
数据提取方式来实现该内容的获取。开始字符串就填: <spanclass="best-answer-title
ml10 bold">满意回答</span>结尾字符串就填:</pre>
。然后添加一个“html标签排除”的数据处理规则,保存即可。
5、测试结果如下:
6、接下来定义一些发布规则,就可以将结构保存在数据库或文本中了。此步骤就不介绍了。
Ok, 这是这个专用博客开始的第一篇博文,写的可能有写啰嗦,例子也很简单。我也正在学习中,还请多多包涵了。大家如果还有什么问题可以在此博文后回复,我会争取一一解决。 thx!8

相关文章推荐
- 网友问题回答---新浪博客怎么采集
- RFM模型数据处理结果分析(回答网友的问题)
- 解决google无法访问或搜索结果无法打开问题
- 回答网友的一个问题
- Dedecms搜索时 当然关键词和栏目名相同时 搜索结果为空的问题的解决方法
- C# IB Google 搜索结果采集模板
- 回答网友关于测试方面的问题
- 解决android 2.2 market搜索结果偏少的问题
- Magento搜索产品结果不精准的问题
- ThinkPHP-TPT360 文章分页不随搜索结果变化的问题
- Android拨号盘T9搜索号码中有空格就没有匹配结果的问题
- Magento网站搜索结果过多-搜索不准确的问题问题的解决
- 解决UISearchDisplayController搜索结果滚动时,顶部透明的问题
- 回答网友的问题,有C# ASP.NET 通用权权限系统源码下载收费
- C# IB Google 搜索结果采集模板
- 网上回答网友的问题
- 解决Outlook搜索功能的搜索结果不完整问题
- Magento搜索产品结果不精准的问题
- Magento搜索产品结果不精准的问题
- Web_PHP_DedeCMS_搜索结果列表页面描述信息截取问题;