社会化搜索与推荐浅析-朴素贝叶斯+laplace平滑文本分类器推导过程及java版实现
2012-03-26 18:28
477 查看
本文由larrylgq编写,转载请注明出处:http://blog.csdn.net/larrylgq/article/details/7395261
作者:吕桂强
邮箱:larry.lv.word@gmail.com
朴素贝叶斯文本分类器用处挺广的,但是网上很少有实现demo,所以写了个java的实现小demo
朴素贝叶斯分类用于文本分类的正式定义如下:
1、设为一个待分类项x,而每个xi为x的一个特征属性(关键字)。
2、有类别集合C。
3、计算。
P(c1|x)=P(x1|c1)*P(c1),P(x2|c1)*P(c1),...,P(xm|c1)*P(c1);=
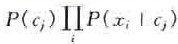
4、如果P(ci|x)的值最大,则i为最接近待分类项的。
本例子训练数据使用http://www.sogou.com/labs/dl/c.html中的mini版
上代码:(为了阅读方便全写在一个类里)
作者:吕桂强
邮箱:larry.lv.word@gmail.com
朴素贝叶斯文本分类器用处挺广的,但是网上很少有实现demo,所以写了个java的实现小demo
朴素贝叶斯分类用于文本分类的正式定义如下:
1、设为一个待分类项x,而每个xi为x的一个特征属性(关键字)。
2、有类别集合C。
3、计算。
P(c1|x)=P(x1|c1)*P(c1),P(x2|c1)*P(c1),...,P(xm|c1)*P(c1);=
4、如果P(ci|x)的值最大,则i为最接近待分类项的。
本例子训练数据使用http://www.sogou.com/labs/dl/c.html中的mini版
上代码:(为了阅读方便全写在一个类里)
/**
*
*/
package com.larry;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.StringReader;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import org.apache.log4j.Logger;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.wltea.analyzer.lucene.IKAnalyzer;
/**
* @author 吕桂强
* @email larry.lv.word@gmail.com
* @version 创建时间:2012-3-26 下午3:59:08
*/
public class my_bayes_demo {
static Logger logger = Logger.getLogger(my_bayes_demo.class.getName());
private String training_path = "/home/larry/桌面/lucenc/Sample";// 训练语料路径
private File traning_text_dir;// 训练语料
private String[] classes;// 训练语料分类集合
private Map<Double, String> classify_result = new HashMap<Double, String>();
/**
* @param args
*/
public static void main(String[] args) {
String text = "微软公司提出以446亿美元的价格收购雅虎中国网2月1日报道 美联社消息,微软公司提出以446亿美元现金加股票的价格收购搜索网站雅虎公司。微软提出以每股31美元的价格收购雅虎。微软的收购报价较雅虎1月31日的收盘价19.18美元溢价62%。微软公司称雅虎公司的股东可以选择以现金或股票进行交易。微软和雅虎公司在2006年底和2007年初已在寻求双方合作。而近两年,雅虎一直处于困境:市场份额下滑、运营业绩不佳、股价大幅下跌。对于力图在互联网市场有所作为的微软来说,收购雅虎无疑是一条捷径,因为双方具有非常强的互补性。(小桥)";
//String text = "联想THINKPAD近期几乎全系列笔记本电脑降价促销,最高降幅达到800美元,降幅达到42%。这是记者昨天从联想美国官方网站发现的。联想相关人士表示,这是为纪念新联想成立1周年而在美国市场推出的促销,产品包括THINKPADT、X以及Z系列笔记本。促销不是打价格战,THINK品牌走高端商务路线方向不会改变";
my_bayes_demo bayes = new my_bayes_demo();
bayes.load_training_data();
String[] terms = null;
terms = bayes.split(text, " ").split(" ");
double probility = 0.0;
for (int i = 0; i < bayes.classes.length; i++) {
String ci = bayes.classes[i];// 第i个分类
probility = bayes.conditional_probability(terms, ci);// 计算给定的文本属性向量terms在给定的分类ci中的分类条件概率
bayes.classify_result.put(probility, ci);// 分类,对应分类的概率
System.out.println(ci + ":" + probility);
}
//排序找到相似度最高的
Double max = null;
Iterator<Double> iterator = bayes.classify_result.keySet().iterator();
while(iterator.hasNext()){
double next = iterator.next();
if(max != null){
max = Math.max(next, max);
}else{
max = next;
}
}
System.out.println(bayes.classify_result.get(max));
}
/**
* @param terms
* @param ci
* @return 当前类别与输入文本的相似度
*/
private double conditional_probability(String[] terms, String ci) {
double ret = 1.0;
// 类条件概率连乘
for (int i = 0; i < terms.length; i++) {
String xi = terms[i];
ret *= calculate_pxc(xi, ci);
}
double nc = get_trainingfile_count_of_classification(ci);// 当前分类的训练文本数目
double nall = get_training_filecount();//全部文本数目
// 再乘以先验概率(全部文本数目比上当前类别的文本数目)
ret *= nc / nall;
return ret;
}
/**
* P(xi∣cj)=P(cjxi)/P(cj)=>
* @param x
* @param c
* @return 关键字为xi且类别为cj的概率
*/
public double calculate_pxc(String x, String c) {
double ret = 0;
double nxc = get_count_containkey_of_classification(c, x);// 当前分类中包含当前关键字的训练文本的数目
double nc = get_trainingfile_count_of_classification(c);// 当前分类的训练文本数目
ret = (nxc + 1) / (nc + 1);//laplace平滑
return ret;
}
/**
* @return 训练文本集中所有的文本数目
*/
public int get_training_filecount()
{
int ret = 0;
for (int i = 0; i < classes.length; i++)
{
ret += get_trainingfile_count_of_classification(classes[i]);
}
return ret;
}
/**
* @param classification
* @return 当前类别下的所有训练文本的路径
*/
public String[] get_files_path(String classification) {
File class_dir = new File(traning_text_dir.getPath() + File.separator + classification);
String[] ret = class_dir.list();
for (int i = 0; i < ret.length; i++) {
ret[i] = traning_text_dir.getPath() + File.separator + classification + File.separator + ret[i];
}
return ret;
}
/**
* @param classification
* @param key
* @return 当前类型中包含关键字key的训练样本数目
*/
public int get_count_containkey_of_classification(String classification, String key) {
int ret = 0;
try {
String[] filepath = get_files_path(classification);
for (int j = 0; j < filepath.length; j++) {
String text = get_text(filepath[j]);
if (text.contains(key)) {
ret++;
}
}
} catch (FileNotFoundException fnfex) {
logger.error("#" + fnfex.getStackTrace());
} catch (IOException ioex) {
logger.error("#" + ioex.getStackTrace());
}
return ret;
}
/**
* @param filepath
* @return 给定文本的文本内容
* @throws FileNotFoundException
* @throws IOException
*/
public String get_text(String filepath) throws FileNotFoundException, IOException {
InputStreamReader isReader = new InputStreamReader(new FileInputStream(filepath), "GBK");
BufferedReader reader = new BufferedReader(isReader);
String aline;
StringBuilder sb = new StringBuilder("");
while ((aline = reader.readLine()) != null) {
sb.append(aline + " ");
}
isReader.close();
reader.close();
return sb.toString();
}
/**
* @param classification
* @return 当前类别下的样本数量
*/
public int get_trainingfile_count_of_classification(String classification) {
// /home/larry/桌面/lucenc/Sample/C000008
File classDir = new File(traning_text_dir.getPath() + File.separator + classification);
return classDir.list().length;
}
/**
* 初始化语料库
*/
private void load_training_data() {
traning_text_dir = new File(training_path);
if (!traning_text_dir.isDirectory()) {
throw new IllegalArgumentException("训练语料库搜索失败! [" + training_path + "]");
}
this.classes = traning_text_dir.list();
}
/**
* 中文分词->获取文本的关键字向量
*
* @param text
* @param splitToken
* @return
*/
public String split(String text, String splitToken) {
StringBuffer result = new StringBuffer("");
try {
Analyzer analyzer = new IKAnalyzer(true);
StringReader reader = new StringReader(text);
TokenStream ts = analyzer.tokenStream(null, reader);
ts.addAttribute(CharTermAttribute.class);
while (ts.incrementToken()) {
CharTermAttribute ta = ts.getAttribute(CharTermAttribute.class);
result.append(ta.toString() + splitToken);
}
} catch (IOException e) {
e.printStackTrace();
}
return result.toString();
}
}

相关文章推荐
- 社会化推荐系统浅析-欧几里德距离的java实现
- 社会化推荐系统浅析-皮尔逊相关系数的java实现
- 社会化搜索与推荐浅析-智能web浅析
- 社会化搜索与推荐浅析-大数据下的实时搜索
- Java实现lucene搜索功能的方法(推荐)
- 社会化搜索与推荐浅析-聚类与分类
- 社会化搜索与推荐浅析-常见推荐算法的比较和浅析
- java滑动窗口(实现平滑数据量)
- 布尔运算--java位图搜索实现
- LibRec:一个实现推荐系统的Java库包
- 基于内容的推荐 java实现
- [置顶] 协同过滤-矩阵分解推荐 java实现
- 分支界限法实现遗传算法中的局部搜索过程
- 给大家推荐一个LRU实现算法的java 代码
- Google 以图搜图 - 相似图片搜索原理 - Java实现
- 深度优先搜索解决 踏青问题 java实现
- java+redis 实现搜索附近人功能
- [置顶] java实现存储过程并同时得到out与return的值
- 【LeetCode-面试算法经典-Java实现】【035-Search Insert Position(搜索插入位置)】
- JAVA动态代理用法与实现过程