《编程卓越之道--第一卷:深入理解计算机》读书笔记
2012-02-26 16:14
260 查看
在看到这本书之前,我并没有读它的打算。我只是想读一些计算机体系结构的书,又不想读太理论化的、晦涩难懂的书。从图书架上拿到这本书之后,翻到它的目录部分。我看到了第九章"CPU体系结构"。这个章节讲到了cpu如何通过并行提高处理速度。因为看到了这个章节的目录,所以我才打算读这本书。现在已经读完了这本书,如果按照读书之前的想法,那么这本书满足了我的需求。我脑中不再有”流水线到底是什么?“、 ”乱序优化到底是什么?“、”为什么要设计流水线?“、”为什么要设计乱序优化?“这四个问题了。除了第九章之外,其他章节带给我得新知识很少。我对这本书有些失望!下面是这本书给我带来的新知识点。
第一,浮点表示法。
浮点数只能提供对实数的一个近似。这是因为计算机中只有有限的位数,只能表示有限数量的浮点数,但是实数却有无限多个。当计算机无法准确表示一个实数时,则会选择一个最接近的、能够精确表示的浮点数。
计算机使用"科学计数法“的原理来表示浮点数,即按照”x.xx * 2^n“的格式记录浮点数。一个浮点数的科学计数法形式有多种。例如,11.111可以记录为1.1111 * 2,也可以记录为11111 * 2^(-3)。如果每一种形式都需要记录在计算机,那么会进一步减少计算机可以表示的浮点数的数量。因此,定义了”规格化浮点数“。计算机中存储的都是规格化浮点数。规格化的定义为:浮点数只有唯一的整数位,这个整数位是1。例如,11.111的规格化表示是1.1111
* 2,0.000111的规格化表示是1.11 * 2^(-4)。从第二个例子可以看到,使用规格化浮点数还有一个好处”维持尽量多的有效位数“。
1.1111 * 2这个式子由三部分组成"符号位+",”尾数位1.1111“,“指数位1”。浮点数表示法中也存在三部分“符号位”,“尾数位”,“指数位”。目前存在三种浮点数表示法“单精度浮点数”、“双精度浮点数”、“扩展精度浮点数”。1) 单精度浮点数用32位二进制数表示浮点数。符号位占1个二进制位,尾数位占23个二进制位,指数位占8个二进制位。因为规格化浮点数肯定具有一个整数位1,所以不需要将这个1存入计算机。虽然单精度浮点数只提供了23个二进制位存储尾数,但是单精度浮点数实际可以表示24个有效位。 2)
双精度浮点数用64位二进制数表示浮点数。符号位占1个二进制位,尾数位占52个二进制位,指数位占11个二进制位。与单精度浮点数相同,双精度浮点数也不需要将整数位1存入计算机。因此,双精度浮点数可以表示53个有效位。3) 扩展精度浮点数使用80位二进制数表示浮点数。符号位占1个二进制位,尾数位占64个二进制位,指数位占15个二进制。同样地,扩展精度浮点数可以表示65个有效位。下图是符号位、尾数位、指数位的布局。
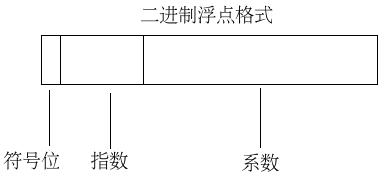
将一个浮点数转换为规格化浮点数存入计算机,要经过如下几个计算过程:1)使用二进制计数法记录浮点数;2) 将二进制浮点数转换为规格化二进制浮点数;3) 调整尾数、指数;4) 将符号位、尾数位、阶码拼成二进制位串。最后得到的二进制位串就是要存入计算机的规格化浮点数。下面是将3.14转换为单精度规格化浮点数的例子,
1) 3.14化为二进制为11.0010 0011 1101 0111 0000 1010 .... 指数为0 符号位为0
2) 进行规格化后的结果为1.1001 0001 1110 1011 1000 0101 0 .... 指数为1 符号位为0
3) 按照单精度格式存储这个数。
首先计算尾数。
只有24个有效位,整数位的1省略。剩下为1001 0001 1110 1011 1000 010 10....
实际计算时发现10...之后有非0的bit,按照四舍五入需要向高位进1。尾数变为
1001 0001 1110 1011 1000 011
然后计算阶数。
1+127 = 128,即1000000。
符号位仍然为0。
4) 最终单精度格式的数为 0 1000000 1001 0001 1110 1011 1000 011。
截止到目前为止,有两个问题没有解释。1)为什么要将指数位转换为阶码?2)当无法准确表示一个浮点数时,如何进行舍入? 关于第一个问题,这本书给的答案是:可以简化浮点数的比较。将指数加上(2^n - 1)之后,可以将阶数作为无符号整数了。对这种说法,我没有完全理解。首先,无符号的比较肯定比有符号比较简单吗?其次,-128(1000 0000)这个数加上127之后还是负数。关于第二个问题,本书给了三种舍入法。1)上舍入,将浮点数转换为大于等于真值的浮点数。2)下舍入,将浮点数转换为小于等于真值的浮点数。3)四舍五入。如果被舍去的部分大于或者等于可保留部分的一半,那么上舍入。如果被舍去的部分小于被保留部分的一半,那么下舍入。假设xxx表示被保留部分。形如x.xxx
1...的规格化数要做上舍入。形如x.xxx 0..的规格化数要做下舍入。
第二,数据总线的位数与内存对齐边界。
在16位数据总线的计算机上,读取偶数地址的两字节内容时只需要一次读操作,读取奇数地址的两字节内容时需要2次读操作。如果需要读写“地址为0处的字节”和“地址为1处的字节”,那么可以将“地址0”放在地址总线上,计算机会传递16位数据,即“字节0”和“字节1”两个字节。这是一次读操作。如果需要读“地址为1处的字节”和“地址为2处的字节”,那么先将“地址0”放在地址总线上,计算机传递“字节0”和“字节1”,然后再将“地址2”放在地址总线上,计算机传递“字节2”和“字节3”,最后将"字节1"和“字节2”拼成16位数作为结果。这是2次读操作。
在16位数据总线的计算机上,如果应用程序的数据需要占据偶数大小的内存空间,那么把数据放置在模2地址处的内存上可以减少读数据的耗时。如果应用程序的数据需要占据奇数大小的内存空间,那么无论把数据放在哪个地址上,都需要额外的一次读周期。同理,在32位数据总线的计算机上,如果应用程序的数据需要占据模4大小的内存空间,那么把数据放置在模2地址处的内存上可以减少读数据的耗时。如果应用程序的数据占用模4余1大小的内存空间,那么无论把数据放置在那个地址上,都需要额外的一次读周期。如果应用程序的数据占用模4余2大小的内存空间,那么将数据放置在模4余3地址处,会导致额外的1次读周期......
综上,在16位机上应该尽量按照2对齐内存地址。在32位机上,应该尽量按照4对齐内存地址。
第三,cpu内存访问。
如果某个应用必须访问速度慢的内存,那么选择合适的寻址模式通常能够允许应用使用更少的指令与更少的内存访问得到同样的结果。如下c/c++代码:
第四,cpu体系结构。
第一个新概念是:并行--提高处理速度的关键。举例如下,
80x86 的mov(srcReg, destReg)指令可能需要执行那些步骤为:1) 从内存中获取指令的操作码; 2) 更新EIP寄存器,将其值改为紧随操作码之后的字节地址; 3) 对操作码进行解码,得到其指定的指令; 4) 从原寄存器中取得数据; 5) 将取得的值存储到目标寄存器中。这5个步骤存在着某种依赖关系。cpu必须先取出指令的操作码,才可以更新EIP寄存器。只有解码之后,才知道指令的原操作数在哪里,目的操作数在哪里。但是第2步与第3步之间没有依赖关系。因此,可以通过让第2步与第3步同时执行来减小cpu执行指令的时间。合并之后的执行步骤变为:1)从内存中获取指令的操作码;
2)更新EIP寄存器,将其值改为紧随操作码之后的字节地址。同时,对操作码进行解码; 3) 从原寄存器中取得数据; 4) 将取得的数据存储到目标寄存器中。
第二个新概念是:预取指令。
32位数据总线一次传输4个字节。一条指令的长度很可能小于4个字节,额外的字节是下一条指令的操作码。如果将这些额外的字节保存下来,直至下一条指令运行时,那么可以减少一次内存读周期。
cpu在执行指令时,并非一直在占用数据总线。例如解码时就不会占用数据总线。cpu中存在一个总线接口单元(BIU)。这个接口单元负责控制控制对地址总线和数据总线的访问。当cpu不使用BIU的时候,BIU可以从内存中取得其他的包含机器指令的数据,并将这些数据存储在预取队列中。然后,当cpu需要指令码或者操作数的时候,它可以从预取队列获取下一个可用的字节。因为预取队列存在于cpu内部,所以可以近似认为从预取队列中取数据的耗时约等于从寄存器中的取数据耗时。
第三个新概念是:指令重叠。
从mov(srcReg, destReg)的描述中可以看到,最后两步“取源操作数”与“存储到目标寄存器”不会用到cpu的解码单元。在预取指令的前提下,取下一条指令肯定不需要用到数据总线和地址总线。因此,可以将下一条指令的“取指令”、“解码指令”与上一条指令的“取源操作数”、“存储到目标寄存器”同步执行。
第四个新概念是:流水线操作。
我认为流水线是指令重叠的一个扩大应用。指令重叠的实现依赖于两个要素1)指令预先获取到了cpu内,以保证"存储前一条指令的计算结果"与“取下一条指令”不会存在数据总线的竞争。2)“解码”与“取操作数”、“存计算结果”属于不同的电路,这些电路可以并行运行互不干扰。现在将第二个要素进行扩展。将cpu完成的多个功能划分为多个模块。不同的电路实现不同的模块,且这些模块可以并行运行互不干扰。这些电路模块组成的就是cpu流水线。下图描述了6个模块电路形成的流水线。 最好的情况下,T6时执行完第一条指令,T7时执行完第二条指令,T8时执行完第三条指令,T9时执行完第四条指令,T10时执行完第五条指令,T11执行完第六条指令....
可以认为从第六个时钟周期开始,每一个时钟周期都可以完成一条指令的执行。
T1 T2 T3 T4 T5 T6 T7 T8 T9
第五个新概念是:流水线停滞。
看上图中的红体字。T6时第一条指令的存值与第三条指令的取值也许都需要使用数据总线,会引起数据总线的竞争。同理T7时,第二条指令与第四条指令也会引起数据总线的竞争。当出现竞争总线的情况时,cpu赋予在流水线中更久的指令以高优先级,这使得流水线中后面的指令停滞。
在这里需要考虑一下跳转指令。假设有一条je label指令条件满足,发生了跳转。可以认为紧邻je label的下五条指令不会再被执行,但是这些指令已经在流水线中了。为了不产生错误的结果,cpu必须停止这些指令。可见,跳转语句会导致程序的性能下降。
第六个新概念是:流水线相关。
如果下一条指令的源操作数十前一条指令的目标操作数,那么下一条指令必须在取值阶段停滞,直至前一条指令执行完成。否则,下一条指令将会取到错误的源操作数。
第七个新概念是:乱序执行。
如果第一条与第二条指令之间存在着数据相关,那么第二条指令必须被延迟执行,直至第一条指令执行完毕。这导致了一次流水线停滞,也就增加了程序的执行时间。如果从第三条指令开始的连续几条指令不依赖于前两条指令,那么可以将这几条连续的指令插入到第一条、第二条之间。这种技术被称为乱序执行。
第一,浮点表示法。
浮点数只能提供对实数的一个近似。这是因为计算机中只有有限的位数,只能表示有限数量的浮点数,但是实数却有无限多个。当计算机无法准确表示一个实数时,则会选择一个最接近的、能够精确表示的浮点数。
计算机使用"科学计数法“的原理来表示浮点数,即按照”x.xx * 2^n“的格式记录浮点数。一个浮点数的科学计数法形式有多种。例如,11.111可以记录为1.1111 * 2,也可以记录为11111 * 2^(-3)。如果每一种形式都需要记录在计算机,那么会进一步减少计算机可以表示的浮点数的数量。因此,定义了”规格化浮点数“。计算机中存储的都是规格化浮点数。规格化的定义为:浮点数只有唯一的整数位,这个整数位是1。例如,11.111的规格化表示是1.1111
* 2,0.000111的规格化表示是1.11 * 2^(-4)。从第二个例子可以看到,使用规格化浮点数还有一个好处”维持尽量多的有效位数“。
1.1111 * 2这个式子由三部分组成"符号位+",”尾数位1.1111“,“指数位1”。浮点数表示法中也存在三部分“符号位”,“尾数位”,“指数位”。目前存在三种浮点数表示法“单精度浮点数”、“双精度浮点数”、“扩展精度浮点数”。1) 单精度浮点数用32位二进制数表示浮点数。符号位占1个二进制位,尾数位占23个二进制位,指数位占8个二进制位。因为规格化浮点数肯定具有一个整数位1,所以不需要将这个1存入计算机。虽然单精度浮点数只提供了23个二进制位存储尾数,但是单精度浮点数实际可以表示24个有效位。 2)
双精度浮点数用64位二进制数表示浮点数。符号位占1个二进制位,尾数位占52个二进制位,指数位占11个二进制位。与单精度浮点数相同,双精度浮点数也不需要将整数位1存入计算机。因此,双精度浮点数可以表示53个有效位。3) 扩展精度浮点数使用80位二进制数表示浮点数。符号位占1个二进制位,尾数位占64个二进制位,指数位占15个二进制。同样地,扩展精度浮点数可以表示65个有效位。下图是符号位、尾数位、指数位的布局。
将一个浮点数转换为规格化浮点数存入计算机,要经过如下几个计算过程:1)使用二进制计数法记录浮点数;2) 将二进制浮点数转换为规格化二进制浮点数;3) 调整尾数、指数;4) 将符号位、尾数位、阶码拼成二进制位串。最后得到的二进制位串就是要存入计算机的规格化浮点数。下面是将3.14转换为单精度规格化浮点数的例子,
1) 3.14化为二进制为11.0010 0011 1101 0111 0000 1010 .... 指数为0 符号位为0
2) 进行规格化后的结果为1.1001 0001 1110 1011 1000 0101 0 .... 指数为1 符号位为0
3) 按照单精度格式存储这个数。
首先计算尾数。
只有24个有效位,整数位的1省略。剩下为1001 0001 1110 1011 1000 010 10....
实际计算时发现10...之后有非0的bit,按照四舍五入需要向高位进1。尾数变为
1001 0001 1110 1011 1000 011
然后计算阶数。
1+127 = 128,即1000000。
符号位仍然为0。
4) 最终单精度格式的数为 0 1000000 1001 0001 1110 1011 1000 011。
截止到目前为止,有两个问题没有解释。1)为什么要将指数位转换为阶码?2)当无法准确表示一个浮点数时,如何进行舍入? 关于第一个问题,这本书给的答案是:可以简化浮点数的比较。将指数加上(2^n - 1)之后,可以将阶数作为无符号整数了。对这种说法,我没有完全理解。首先,无符号的比较肯定比有符号比较简单吗?其次,-128(1000 0000)这个数加上127之后还是负数。关于第二个问题,本书给了三种舍入法。1)上舍入,将浮点数转换为大于等于真值的浮点数。2)下舍入,将浮点数转换为小于等于真值的浮点数。3)四舍五入。如果被舍去的部分大于或者等于可保留部分的一半,那么上舍入。如果被舍去的部分小于被保留部分的一半,那么下舍入。假设xxx表示被保留部分。形如x.xxx
1...的规格化数要做上舍入。形如x.xxx 0..的规格化数要做下舍入。
第二,数据总线的位数与内存对齐边界。
在16位数据总线的计算机上,读取偶数地址的两字节内容时只需要一次读操作,读取奇数地址的两字节内容时需要2次读操作。如果需要读写“地址为0处的字节”和“地址为1处的字节”,那么可以将“地址0”放在地址总线上,计算机会传递16位数据,即“字节0”和“字节1”两个字节。这是一次读操作。如果需要读“地址为1处的字节”和“地址为2处的字节”,那么先将“地址0”放在地址总线上,计算机传递“字节0”和“字节1”,然后再将“地址2”放在地址总线上,计算机传递“字节2”和“字节3”,最后将"字节1"和“字节2”拼成16位数作为结果。这是2次读操作。
在16位数据总线的计算机上,如果应用程序的数据需要占据偶数大小的内存空间,那么把数据放置在模2地址处的内存上可以减少读数据的耗时。如果应用程序的数据需要占据奇数大小的内存空间,那么无论把数据放在哪个地址上,都需要额外的一次读周期。同理,在32位数据总线的计算机上,如果应用程序的数据需要占据模4大小的内存空间,那么把数据放置在模2地址处的内存上可以减少读数据的耗时。如果应用程序的数据占用模4余1大小的内存空间,那么无论把数据放置在那个地址上,都需要额外的一次读周期。如果应用程序的数据占用模4余2大小的内存空间,那么将数据放置在模4余3地址处,会导致额外的1次读周期......
综上,在16位机上应该尽量按照2对齐内存地址。在32位机上,应该尽量按照4对齐内存地址。
第三,cpu内存访问。
如果某个应用必须访问速度慢的内存,那么选择合适的寻址模式通常能够允许应用使用更少的指令与更少的内存访问得到同样的结果。如下c/c++代码:
int tmp[10]; ....//some code tmp[6] = 5; ....//some code如果在支持比例变址寻址模式的cpu上运行,那么上述代码可以被编译为:
mov(5, ax); mov(6, bx); mov(ax, tmp[bx * 4]);如果不支持比例变址寻址模式,那么上述代码可以被翻译为:
mov(tmp, bx); mov(6, cx); intmul(4, cx); add(cx, bx); mov(5, [bx]);可见,比例变址寻址模式减少2条指令。
第四,cpu体系结构。
第一个新概念是:并行--提高处理速度的关键。举例如下,
80x86 的mov(srcReg, destReg)指令可能需要执行那些步骤为:1) 从内存中获取指令的操作码; 2) 更新EIP寄存器,将其值改为紧随操作码之后的字节地址; 3) 对操作码进行解码,得到其指定的指令; 4) 从原寄存器中取得数据; 5) 将取得的值存储到目标寄存器中。这5个步骤存在着某种依赖关系。cpu必须先取出指令的操作码,才可以更新EIP寄存器。只有解码之后,才知道指令的原操作数在哪里,目的操作数在哪里。但是第2步与第3步之间没有依赖关系。因此,可以通过让第2步与第3步同时执行来减小cpu执行指令的时间。合并之后的执行步骤变为:1)从内存中获取指令的操作码;
2)更新EIP寄存器,将其值改为紧随操作码之后的字节地址。同时,对操作码进行解码; 3) 从原寄存器中取得数据; 4) 将取得的数据存储到目标寄存器中。
第二个新概念是:预取指令。
32位数据总线一次传输4个字节。一条指令的长度很可能小于4个字节,额外的字节是下一条指令的操作码。如果将这些额外的字节保存下来,直至下一条指令运行时,那么可以减少一次内存读周期。
cpu在执行指令时,并非一直在占用数据总线。例如解码时就不会占用数据总线。cpu中存在一个总线接口单元(BIU)。这个接口单元负责控制控制对地址总线和数据总线的访问。当cpu不使用BIU的时候,BIU可以从内存中取得其他的包含机器指令的数据,并将这些数据存储在预取队列中。然后,当cpu需要指令码或者操作数的时候,它可以从预取队列获取下一个可用的字节。因为预取队列存在于cpu内部,所以可以近似认为从预取队列中取数据的耗时约等于从寄存器中的取数据耗时。
第三个新概念是:指令重叠。
从mov(srcReg, destReg)的描述中可以看到,最后两步“取源操作数”与“存储到目标寄存器”不会用到cpu的解码单元。在预取指令的前提下,取下一条指令肯定不需要用到数据总线和地址总线。因此,可以将下一条指令的“取指令”、“解码指令”与上一条指令的“取源操作数”、“存储到目标寄存器”同步执行。
第四个新概念是:流水线操作。
我认为流水线是指令重叠的一个扩大应用。指令重叠的实现依赖于两个要素1)指令预先获取到了cpu内,以保证"存储前一条指令的计算结果"与“取下一条指令”不会存在数据总线的竞争。2)“解码”与“取操作数”、“存计算结果”属于不同的电路,这些电路可以并行运行互不干扰。现在将第二个要素进行扩展。将cpu完成的多个功能划分为多个模块。不同的电路实现不同的模块,且这些模块可以并行运行互不干扰。这些电路模块组成的就是cpu流水线。下图描述了6个模块电路形成的流水线。 最好的情况下,T6时执行完第一条指令,T7时执行完第二条指令,T8时执行完第三条指令,T9时执行完第四条指令,T10时执行完第五条指令,T11执行完第六条指令....
可以认为从第六个时钟周期开始,每一个时钟周期都可以完成一条指令的执行。
T1 T2 T3 T4 T5 T6 T7 T8 T9
| 取指 | 解码 | 取址 | 取值 | 计算 | 存值 | |||
| 取指 | 解码 | 取址 | 取值 | 计算 | 存值 | |||
| 取指 | 解码 | 取址 | 取值 | 计算 | 存值 | |||
| 取指 | 解码 | 取址 | 取值 | 计算 | 存值 |
看上图中的红体字。T6时第一条指令的存值与第三条指令的取值也许都需要使用数据总线,会引起数据总线的竞争。同理T7时,第二条指令与第四条指令也会引起数据总线的竞争。当出现竞争总线的情况时,cpu赋予在流水线中更久的指令以高优先级,这使得流水线中后面的指令停滞。
在这里需要考虑一下跳转指令。假设有一条je label指令条件满足,发生了跳转。可以认为紧邻je label的下五条指令不会再被执行,但是这些指令已经在流水线中了。为了不产生错误的结果,cpu必须停止这些指令。可见,跳转语句会导致程序的性能下降。
第六个新概念是:流水线相关。
如果下一条指令的源操作数十前一条指令的目标操作数,那么下一条指令必须在取值阶段停滞,直至前一条指令执行完成。否则,下一条指令将会取到错误的源操作数。
第七个新概念是:乱序执行。
如果第一条与第二条指令之间存在着数据相关,那么第二条指令必须被延迟执行,直至第一条指令执行完毕。这导致了一次流水线停滞,也就增加了程序的执行时间。如果从第三条指令开始的连续几条指令不依赖于前两条指令,那么可以将这几条连续的指令插入到第一条、第二条之间。这种技术被称为乱序执行。

相关文章推荐
- 掀起计算机的盖头来——简评《编程卓越之道 第一卷 深入理解计算机》
- 《深入理解计算机系统 2nd》部分读书笔记---第9章 虚拟存储器(未完成)
- 20135202闫佳歆--week 7 深入理解计算机系统第七章--读书笔记
- 读《编程卓越之道:深入理解计算机》续四
- 深入理解计算机系统读书笔记之第一章:漫游
- 深入理解计算机系统--第二章(读书笔记)
- 深入理解计算机系统--读书笔记(第一章)
- 深入理解计算机系统2_信息存储(读书笔记)
- 深入理解计算机系统--读书笔记
- 读书笔记-深入理解计算机系统(第一章)
- 2013337朱荟潼 Linux&深入理解计算机系统第七章读书笔记——链接
- 读《编程卓越之道:深入理解计算机》
- 读书笔记:深入理解计算机系统 第一章
- Computer Systems A Programmer's Perspective(深入理解计算机系统)第一章读书笔记
- 读书笔记:深入理解计算机系统 第二章
- 【读书笔记】深入理解计算机系统
- 深入理解计算机系统读书笔记
- 《深入理解计算机系统 2nd》读书笔记----第7章 链接
- 【读书笔记】深入理解计算机系统(第七章)
- 读《编程卓越之道:深入理解计算机》续三