分享制作精良的知识管理系统 配置SQL Server文档数据库 完美实现博客文章的的下载,存储和浏览
2011-11-11 09:18
986 查看
前一篇文章《分享制作精良的知识管理系统 博客备份程序 Site Rebuild》已经提到如何使用Site Rebuild来下载您所喜欢的博客文章,但是还不能实现把下载的文件导入进数据库中,无法实现在线浏览服务器中的文档数据。这一篇文章则帮助您建立文档数据库,现博客文章的的下载,存储和浏览。
打开Data Loader程序,执行Setting程序,打开的界面效果如下
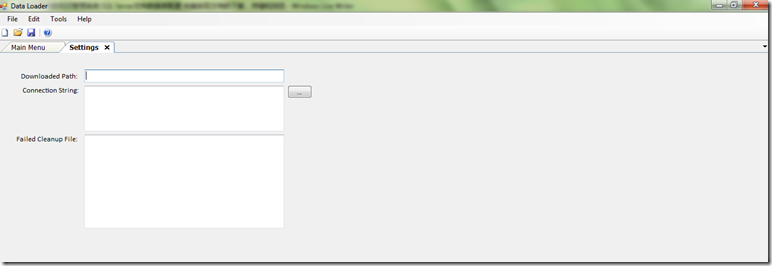
点击ConnectionString后面的按钮,填写正确的数据库配置,如下所示
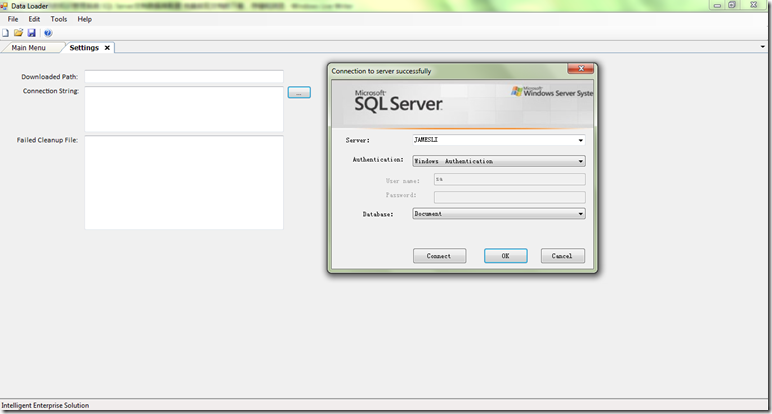
如下图所示,点击OK,返回主程序窗体。
打开SQL Server数据库管理程序,新创建一个名称为Document的数据库,运行下面的SQL 脚本以创建表结构
最后一句的脚本,是为了创建配置数据选项。再次打开Setting程序,会显示出这个表的内容。
这就是所需要做的所有动作,按照前一篇文章的介绍,你可以很容易的达到下面的效果
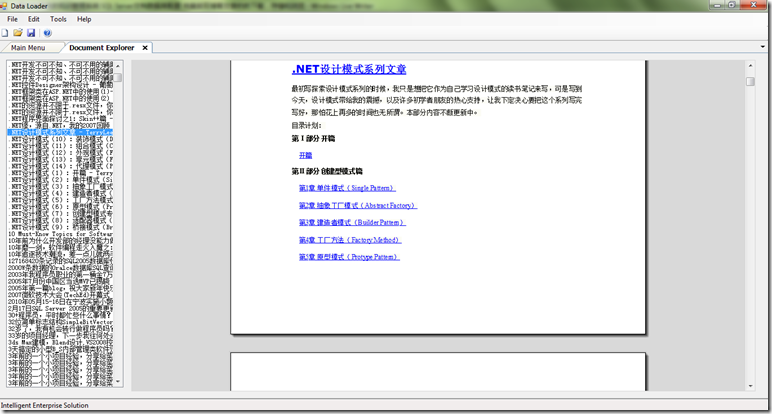
截图中的文章取自TerryLee的设计模式系列,成一个体系,放在一起阅读,很方便。
请到epn.codeplec.com(http://epn.codeplex.com/releases/view/68647)中下载最新的Data Loader程序,以体验离线阅读博客文章。所有的文章和数据文档都在您自己的电脑中,您可以对它进行编辑,加工,提炼,学习。
到目前为止,Data Loader还需要改善的地方
1 通常一篇文章中会带有一小段代码下载,自动下载文档的同时,也希望可以下载到它的附件。
2 增强搜索能力,创建新的Index Builder程序,以适应在海量的文档数据库中搜索您需要的文档。
3 文档的下载,导入,需要增加进度条(Progress Bar)以显示当前状态,这样界面会友好一些。
4 在分析,下载和导入各个模块中,增加多线程处理能力,以提高处理速度。
5 增加新的应用,比如PPT下载,以搜索好的PPT数据资料。Image Download是用于下载网站中的图片,比如,经常看到一些做的非常好的界面效果图,于是就想到这个批量方式来获取这些数据,以集中研究UI设计。
6 压缩与解压缩处理。相同内容的文章,RTF格式一般是DOC格式三到四倍的尺寸大小,导致RTF格式比较消耗硬盘空间。以我的本机为例,2723个DOC文档,一共是745MB,而RTF格式则达到5G,存到数据库中,数据库的尺寸增加达到8G左右。需要对文档作压缩处理,处理思路是使用我们熟悉的ICSharpCode.SharpZipLib.dll和zip格式。
希望对你有帮助,欢迎提出宝贵意见。
打开Data Loader程序,执行Setting程序,打开的界面效果如下
点击ConnectionString后面的按钮,填写正确的数据库配置,如下所示
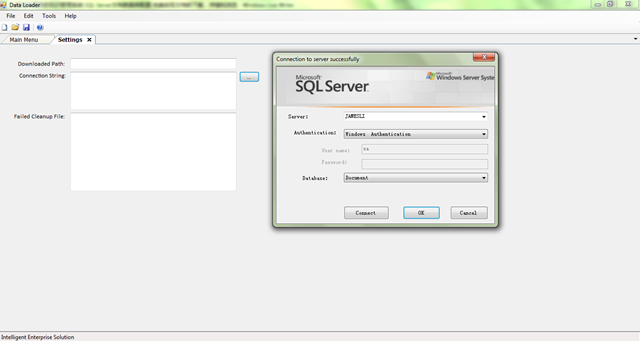
如下图所示,点击OK,返回主程序窗体。
打开SQL Server数据库管理程序,新创建一个名称为Document的数据库,运行下面的SQL 脚本以创建表结构
/****** 对象: Table [dbo].[CATEGORY] 脚本日期: 11/04/2011 10:27:21 ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[CATEGORY]( [RECNUM] [int] IDENTITY(1,1) NOT NULL, [NAME] [nvarchar](200) NULL, CONSTRAINT [PK_CATEGORY] PRIMARY KEY CLUSTERED ( [RECNUM] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] /****** 对象: Table [dbo].[DOCUMENT] 脚本日期: 11/04/2011 16:46:37 ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[DOCUMENT]( [RECNUM] [int] IDENTITY(1,1) NOT NULL, [SUBJECT] [nvarchar](2000) NULL, [BODY_TYPE] [nvarchar](50) NULL, [BODY] [ntext] NULL, [CREATE_DATE] [datetime] NULL, [CATEGORY] [int] NULL, [CREATE_BY] [nvarchar](50) NULL, [COMPUTER] [nvarchar](200) NULL, [PATH] [nvarchar](2000) NULL, CONSTRAINT [PK_DOCUMENT] PRIMARY KEY CLUSTERED ( [RECNUM] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY] /****** Object: Table [dbo].[SETTINGS] Script Date: 11/07/2011 00:04:28 ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[SETTINGS]( [RECNUM] [int] IDENTITY(1,1) NOT NULL, [DOWNLOADED_PATH] [nvarchar](800) NULL, [CONNECTION_STRING] [nvarchar](800) NULL, [FAILED_CLEANUP_FILE] [nvarchar](400) NULL, CONSTRAINT [PK_SETTINGS] PRIMARY KEY CLUSTERED ( [RECNUM] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO
INSERT dbo.SETTINGS ( DOWNLOADED_PATH , CONNECTION_STRING , FAILED_CLEANUP_FILE ) VALUES ( 'G:\Document', -- DOWNLOADED_PATH - nvarchar(800) NULL , -- CONNECTION_STRING - nvarchar(800) NULL -- FAILED_CLEANUP_FILE - nvarchar(400) )
最后一句的脚本,是为了创建配置数据选项。再次打开Setting程序,会显示出这个表的内容。
这就是所需要做的所有动作,按照前一篇文章的介绍,你可以很容易的达到下面的效果

截图中的文章取自TerryLee的设计模式系列,成一个体系,放在一起阅读,很方便。
请到epn.codeplec.com(http://epn.codeplex.com/releases/view/68647)中下载最新的Data Loader程序,以体验离线阅读博客文章。所有的文章和数据文档都在您自己的电脑中,您可以对它进行编辑,加工,提炼,学习。
到目前为止,Data Loader还需要改善的地方
1 通常一篇文章中会带有一小段代码下载,自动下载文档的同时,也希望可以下载到它的附件。
2 增强搜索能力,创建新的Index Builder程序,以适应在海量的文档数据库中搜索您需要的文档。
3 文档的下载,导入,需要增加进度条(Progress Bar)以显示当前状态,这样界面会友好一些。
4 在分析,下载和导入各个模块中,增加多线程处理能力,以提高处理速度。
5 增加新的应用,比如PPT下载,以搜索好的PPT数据资料。Image Download是用于下载网站中的图片,比如,经常看到一些做的非常好的界面效果图,于是就想到这个批量方式来获取这些数据,以集中研究UI设计。
6 压缩与解压缩处理。相同内容的文章,RTF格式一般是DOC格式三到四倍的尺寸大小,导致RTF格式比较消耗硬盘空间。以我的本机为例,2723个DOC文档,一共是745MB,而RTF格式则达到5G,存到数据库中,数据库的尺寸增加达到8G左右。需要对文档作压缩处理,处理思路是使用我们熟悉的ICSharpCode.SharpZipLib.dll和zip格式。
希望对你有帮助,欢迎提出宝贵意见。

相关文章推荐
- 分享制作精良的知识管理系统 博客园博客备份程序 Site Rebuild
- C# ASP.NET 走火入魔通用权限管理系统组件V3.2试用版下载地址【含数据库设计文档、使用手册】
- sql server 2005 (2008)能成功删除系统存储过程以实现安全配置吗?
- python实现下载韩寒博客中的所有文章,在本地存储
- 数据库系统实现-辅助存储管理
- Sybase数据库技术,数据库恢复---分享Sybase数据库知识(博客文章索引)
- 博客系统文章的数据库存储方式
- 博客系统文章的数据库存储方式
- C# ASP.NET 走火入魔通用权限管理系统组件V3.2试用版下载地址【含数据库设计文档、使用手册】
- 博客系统文章的数据库存储方式
- C# ASP.NET 走火入魔通用权限管理系统组件V3.2试用版下载地址【含数据库设计文档、使用手册】
- 不写代码开发信息管理系统-配置实现 下载地址:http://121.18.78.216
- Sybase数据库技术,数据库恢复---分享Sybase数据库知识(博客文章索引@51cto)
- ***博客系统文章的数据库存储方式
- 知识竞赛现场管理系统安装配置及使用疑难问题汇编
- 使用PHP制作 简易员工管理系统之七(MVC实现用户信息增、删、改、查)
- 用小猫统计制作运动员评价管理系统:先制作各个数据库表的excel模板
- SQL Server 2012笔记分享-54:数据库文件管理1
- 本体建模与语义Web知识发现 3 基于关系数据库的XML文档管理
- .NET 插件系统框架设计(二) 使用对象序列化实现自定义配置文件管理