Oracle 多表连接顺序与性能关系测试
2011-10-05 22:40
381 查看
一. 创建表并insert 数据
create table ta (id number,name varchar2(10));
create table tb(id number,job varchar2(10));
begin
for i in 1..1000000 loop
begin
insert into ta values(i,'dave');
commit;
end;
end loop;
end;
begin
for i in 1..1000000 loop
begin
if i<10 then
insert into tb values(i,'boy');
elsif i<20 and i>10 then
insert into tb values(i,'girl');
commit;
end if;
end;
end loop;
end;
二.在没有索引的情况关联ta 和 tb 查询
2.1 optimizer选择 CBO(10g 默认)
--ta 在前
ta.id, ta.name,tb.job from ta,tb where ta.id=tb.id;

--tb 在前
ta.id, ta.name,tb.job from tb,ta where ta.id=tb.id;
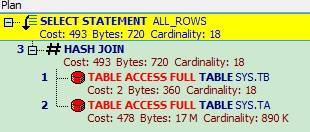
总结:
两条SQL 执行计划是一样的, ta和tb 的顺序没有影响。
因为ta和tb 的记录相差较大,ta是100万,tb 只有20条。 所以这里CBO 选择使用Hash Join。
CBO 选择2个表中记录较小的表tb,将其数据放入内存,对Join key构造hash 表,然后去扫描大表ta。 找出与散列表匹配的行。
2.2 对ta和tb 的ID 建b-tree 索引后在查看
--建索引
create index idx_ta_id on ta(id);
create index idx_tb_id on tb(id);
--tb 在前
select ta.id, ta.name,tb.job from tb,ta where ta.id=tb.id;

--ta 在前
select ta.id, ta.name,tb.job from ta,tb where ta.id=tb.id;
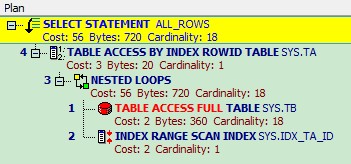
总结:
执行计划还是一样,不同的是表之间的关联模式发生的改变,从Hash Join 变成了Nested Loops。
Nested loop一般用在连接的表中有索引,并且索引选择性较好的时候. 在我们这个示例中,CBO 选择把返回结果集较小的表tb 作为outer table,CBO 下,默认把outer table 作为驱动表,然后用outer table 的每一行与inner table(我们这里是ta)进行Join,去匹配结果集。 由此可见,在tb(inner table) 有索引的情况,这种匹配就非常快。
这种情况下整个SQL的cost:
cost = outer access cost + (inner access cost * outer cardinality)
从某种角度上看,可以把Nested loop 看成2层for 循环。
2.3 使用RBO 查看
在10g里,optimizer 默认已经使用CBO了,如果我们想使用RBO, 只能通过Hint 来实现。
-- ta 在前
select /*+rule*/ta.id, ta.name,tb.job from ta,tb where ta.id=tb.id;
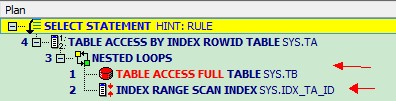
SYS@anqing2(rac2)> select /*+rule*/ta.id, ta.name,tb.job from ta,tb where ta.id<100 and ta.id=tb.id;
Elapsed: 00:00:00.00
-- 注意这个SQL里,我们加了ta.id<100 的条件
-- 当我们加上条件之后,就先走ta了,而不是tb。 因为先走ta,用ta的限制条件过滤掉一部分结果,这样剩下的匹配工作就会减少。
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("TA"."ID"<100)
5 - access("TA"."ID"="TB"."ID")
Note
------ rule based optimizer used (consider using cbo)
--tb 在前
select /*+rule*/ta.id, ta.name,tb.job from tb,ta where ta.id=tb.id;

总结:
这2个就区别很明显。 因为Oracle对sql的解析是从后向前的。 那么当先遇到tb时,那么会对tb进行全表扫描,然后用这个结果匹配ta。因为ta有索引,所以通过索引去匹配。
如果先遇到ta,那么就会对ta进行全表扫描。 因为2个表的差距很大,所以全表扫描的成本也就很大。
所以在RBO 下,大表在前,小表在后。这样就会先遇到小表,后遇到大表。 如果有指定限定的where 条件,会先走限定条件的表。
2.4 drop 索引之后,在走RBO
drop index idx_ta_id;
drop index idx_tb_id;
--ta 在前
select /*+rule*/ta.id, ta.name,tb.job from ta,tb where ta.id=tb.id;

--tb 在前
select /*+rule*/ta.id, ta.name,tb.job from tb,ta where ta.id=tb.id;

总结:
这里选择了Sort Merge Join 来连接2张表。Sort Merge join 用在没有索引,并且数据已经排序的情况.
我们表中的记录是按照顺序插叙的,所以符合这个条件。 SQL 的解析还是按照从后往前,所以这里ta和tb 在前先扫描的顺序不一样,不过都是全表扫描。 效率都不高。
2.5 引深一个问题:使用 字段名 代替 *
* 能方便很多,但在ORACLE解析的过程中, 会通过查询数据字典,会将’*’ 依次转换成所有的列名,这就需要耗费更多的时间. 从而降低了效率。
SYS@anqing2(rac2)> set timing on
SYS@anqing2(rac2)> select * from ta where rownum=1;
ID NAME
---------- ----------
1 dave
Elapsed: 00:00:00.03
SYS@anqing2(rac2)> desc ta
Name Null? Type
-------------------------------------
ID NUMBER
NAME VARCHAR2(10)
SYS@anqing2(rac2)> select id,name from ta where rownum=1;
ID NAME
---------- ----------
1 dave
Elapsed: 00:00:00.02
时间已经缩短。 但不明显,用Toad 来查看一下:

写全字段,执行时间是161 毫秒,用* 是561毫秒。 差距很明显。
注意:
使用 * 和 写全字段名,他们的执行计划是一样的,但是执行时间不一样。
create table ta (id number,name varchar2(10));
create table tb(id number,job varchar2(10));
begin
for i in 1..1000000 loop
begin
insert into ta values(i,'dave');
commit;
end;
end loop;
end;
begin
for i in 1..1000000 loop
begin
if i<10 then
insert into tb values(i,'boy');
elsif i<20 and i>10 then
insert into tb values(i,'girl');
commit;
end if;
end;
end loop;
end;
二.在没有索引的情况关联ta 和 tb 查询
2.1 optimizer选择 CBO(10g 默认)
--ta 在前
ta.id, ta.name,tb.job from ta,tb where ta.id=tb.id;
--tb 在前
ta.id, ta.name,tb.job from tb,ta where ta.id=tb.id;
总结:
两条SQL 执行计划是一样的, ta和tb 的顺序没有影响。
因为ta和tb 的记录相差较大,ta是100万,tb 只有20条。 所以这里CBO 选择使用Hash Join。
CBO 选择2个表中记录较小的表tb,将其数据放入内存,对Join key构造hash 表,然后去扫描大表ta。 找出与散列表匹配的行。
2.2 对ta和tb 的ID 建b-tree 索引后在查看
--建索引
create index idx_ta_id on ta(id);
create index idx_tb_id on tb(id);
--tb 在前
select ta.id, ta.name,tb.job from tb,ta where ta.id=tb.id;
--ta 在前
select ta.id, ta.name,tb.job from ta,tb where ta.id=tb.id;
总结:
执行计划还是一样,不同的是表之间的关联模式发生的改变,从Hash Join 变成了Nested Loops。
Nested loop一般用在连接的表中有索引,并且索引选择性较好的时候. 在我们这个示例中,CBO 选择把返回结果集较小的表tb 作为outer table,CBO 下,默认把outer table 作为驱动表,然后用outer table 的每一行与inner table(我们这里是ta)进行Join,去匹配结果集。 由此可见,在tb(inner table) 有索引的情况,这种匹配就非常快。
这种情况下整个SQL的cost:
cost = outer access cost + (inner access cost * outer cardinality)
从某种角度上看,可以把Nested loop 看成2层for 循环。
2.3 使用RBO 查看
在10g里,optimizer 默认已经使用CBO了,如果我们想使用RBO, 只能通过Hint 来实现。
-- ta 在前
select /*+rule*/ta.id, ta.name,tb.job from ta,tb where ta.id=tb.id;
SYS@anqing2(rac2)> select /*+rule*/ta.id, ta.name,tb.job from ta,tb where ta.id<100 and ta.id=tb.id;
Elapsed: 00:00:00.00
-- 注意这个SQL里,我们加了ta.id<100 的条件
-- 当我们加上条件之后,就先走ta了,而不是tb。 因为先走ta,用ta的限制条件过滤掉一部分结果,这样剩下的匹配工作就会减少。
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("TA"."ID"<100)
5 - access("TA"."ID"="TB"."ID")
Note
------ rule based optimizer used (consider using cbo)
--tb 在前
select /*+rule*/ta.id, ta.name,tb.job from tb,ta where ta.id=tb.id;
总结:
这2个就区别很明显。 因为Oracle对sql的解析是从后向前的。 那么当先遇到tb时,那么会对tb进行全表扫描,然后用这个结果匹配ta。因为ta有索引,所以通过索引去匹配。
如果先遇到ta,那么就会对ta进行全表扫描。 因为2个表的差距很大,所以全表扫描的成本也就很大。
所以在RBO 下,大表在前,小表在后。这样就会先遇到小表,后遇到大表。 如果有指定限定的where 条件,会先走限定条件的表。
2.4 drop 索引之后,在走RBO
drop index idx_ta_id;
drop index idx_tb_id;
--ta 在前
select /*+rule*/ta.id, ta.name,tb.job from ta,tb where ta.id=tb.id;
--tb 在前
select /*+rule*/ta.id, ta.name,tb.job from tb,ta where ta.id=tb.id;
总结:
这里选择了Sort Merge Join 来连接2张表。Sort Merge join 用在没有索引,并且数据已经排序的情况.
我们表中的记录是按照顺序插叙的,所以符合这个条件。 SQL 的解析还是按照从后往前,所以这里ta和tb 在前先扫描的顺序不一样,不过都是全表扫描。 效率都不高。
2.5 引深一个问题:使用 字段名 代替 *
* 能方便很多,但在ORACLE解析的过程中, 会通过查询数据字典,会将’*’ 依次转换成所有的列名,这就需要耗费更多的时间. 从而降低了效率。
SYS@anqing2(rac2)> set timing on
SYS@anqing2(rac2)> select * from ta where rownum=1;
ID NAME
---------- ----------
1 dave
Elapsed: 00:00:00.03
SYS@anqing2(rac2)> desc ta
Name Null? Type
-------------------------------------
ID NUMBER
NAME VARCHAR2(10)
SYS@anqing2(rac2)> select id,name from ta where rownum=1;
ID NAME
---------- ----------
1 dave
Elapsed: 00:00:00.02
时间已经缩短。 但不明显,用Toad 来查看一下:
写全字段,执行时间是161 毫秒,用* 是561毫秒。 差距很明显。
注意:
使用 * 和 写全字段名,他们的执行计划是一样的,但是执行时间不一样。

相关文章推荐
- Oracle 多表 连接 顺序 与 性能关系 测试
- Oracle 多表 连接 顺序 与 性能关系 测试
- Oracle 多表 连接 顺序 与 性能关系 测试
- Oracle 多表 连接 顺序 与 性能关系 测试
- Oracle 多表 连接 顺序 与 性能关系 测试
- Oracle 多表 连接 顺序 与 性能关系 测试
- Oracle 多表 连接 顺序 与 性能关系 测试
- Oracle 多表 连接 顺序 与 性能关系 测试
- Oracle性能优化学习笔记之WHERE子句中的连接顺序
- 各方式连接oracle db 的性能测试(c#)
- 关于OleDB\Oracle\SQLClient连接数据库的性能测试
- 【读书笔记】【收获,不止Oracle】不同连接类型表下,驱动顺序对查询性能的影响
- Oracle性能优化学习笔记WHERE在连接顺序的条款
- oracle技术之提高短连接性能方法测试
- Oracle性能优化学习笔记之WHERE子句中的连接顺序
- oracle连接数据库测试代码
- JMeter学习(八)JDBC测试计划-连接Oracle
- Neutron OVS Bridge 连接方式 (veth pair / ovs peer) 的选型和性能测试
- 在性能测试时,如何观察服务器端Oracle在执行的Sql语句【监控】
- Nginx 72万连接性能测试(一)