字符串匹配算法 Boyer-Moore
2011-09-03 16:11
323 查看
1.问题描述
求在给定的字符创string中搜索pat(模式字符串)第一次出现的位置i
2.Boyer-Moore算法的原理
算法的基本思想是:从字符串的右边开始匹配比较比从字符串左面开始匹配比较能够获得更多的信息,以减少字符的比较次数。
如果pat从string的最左面(开始处)进行匹配,那么pat和string的开始字符是对齐的。下面考虑从后往前的方法能够为我们带来什么好处,设取string的第patlen个字符char,那么char与pat的最后一个字符对齐,我们有一下结论:
结论1:如果我们知道char没有在pat中出现,那么我们就不需要考虑pat在string的第1-patlen个位置上出现的可能性(pat可能出现在第1到patlen个位置上的条件是char在pat中出现)
结论2:更一般的,如果char在pat中最接近尾部出现的位置是delta1(计数是从pat的右边往左数),那么我们可以无需比较,直接将pat后移delta1个位置。
基于以上两点,我们可以尽可能多的后移pat,同时减少比较次数。当char没有出现在pat中,delta1就等于patlen,这时可以直接将pat后移,而不用比较string的前patlen-1个字符与pat的关系。
现在假设char与pat的最后一个字符匹配,这时就采用回退比较的方式来比较剩余的字符是否匹配,即比较pat倒数第二个与char前面一个,以此类推。这时如果匹配成功,该算法就退出。如果在pat中的后m个字符已经匹配成功时,出现了一个新的字符char匹配失败,这时需要考虑如何尽可能多的后退pat!
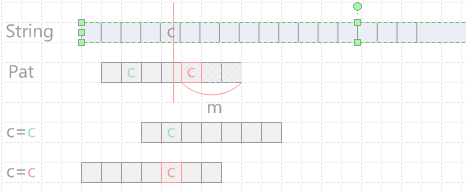
原文中关于后退的第一个方案描述,我使用上图进行解释,c为不匹配的字符,当c出现在已匹配的m个字符中时,这时的效率是低下的,出现了pat回退的现象;当c出现在不匹配的字符中时,pat前移的长度为delta1(c)-m。
前面提到了delta1是一个函数,返回字符距离pat末尾的距离。
在这里提出了一个新的问题,即第一个不匹配位置的字符如果出现在了pat的已匹配的串中(上图中的最后一个移动的情况),那么移动显然是低效的。如果记已经匹配的m个字符为subpat,同时在不匹配位置,记string对应位置为c,pat中对应位置为a。用c+subpat表示以c引导的subpat串,为了保证最大右移和正确性,这时我们需要找到pat自a起前面的串中是否含有形如x+subpat(x!=a)的子串,如果存在则可以将pat后移,使得第一个x+subpat的x与string的c对齐。
上文中的绿色部分我称为后移方案1,红色部分称之为后移方案2。实际上这两种方案是互为补充的,当方案1出现了低效的情况,则使用方案2代替。这一点在后面的为算法中有所体现。
算法的伪代码如下:

上图中使用红色框标识的部分就是上文中提到的方案1和方案2的互补措施。
下面来说说delta1和delta2
delta1(char) = patlen if char 没有在pat中出现
delta1(char) = patlen - j if char出现在pat中,j为char在pat中的最后一个出现位置
delta2
定义:设有序列[C1,C2,...,Cn]和[B1,B2,...,Bn],如果对于i(i=1-n),有Ci=Bi或者Ci=$或者Bi=$,我们就说两个序列是一致的($代表空)。
例子:序列[$,$,$,a,b,c]和[a,b,$,a,b,c]就是一致的
定义rpr(j):粗略的说来,rpr(j)代表的是subpat重现位置。严格定义如下
rpr(j) = max{k|k<=patlen && [pat(j+1),...pat(patlen)]与[pat(k),...,pat(k+patlen-j-1)]是一致的 && pat(k-1)!=pat(j) || k<=1 }
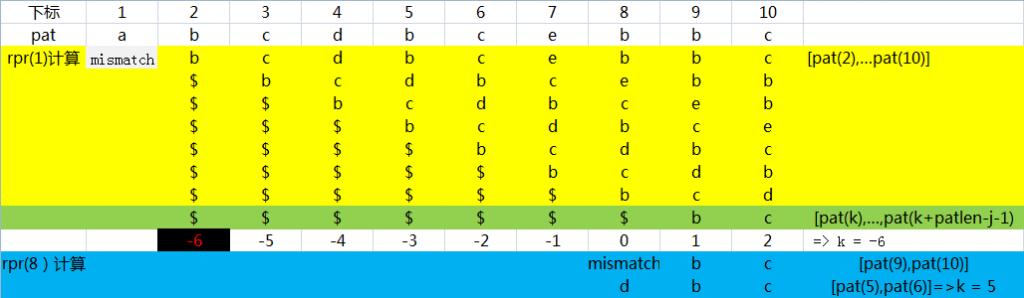
这个图演示了如何来计算rpr(j)
有了rpr(j),我们可以计算出pat需要后移步数为 j+1-rpr(j),同时将匹配位置移动到pat尾部需要patlen-j步。由于在实际操作过程中,pat是不动的,这种移动被相对的转移到了string上,因此string上的匹配位置应该后移delta2 = { j+1-rpr(j)} + {patlen-j} = patlen + 1 - rpr(j).
小结:个人觉得花了这么长时间还是把这个算法的基本原理是弄懂了,它的关键就应该在我说的方案2的计算上,这一点好像和KMP算法有相似之处。关于算法的其它问题,例如实现,请参看我下面的参考文献。如发现错误,敬请您留言。
参考文献:
Boyer-Moore的wiki主页:http://en.wikipedia.org/wiki/Boyer%E2%80%93Moore_string_search_algorithm
Boyer-Moore的论文:http://www.cs.utexas.edu/~moore/publications/fstrpos.pdf
小北的家:http://blog.csdn.net/ijuliet/article/details/4200771 (主要还是参考了上面的论文,不过她把关键的英文部分弄懂了,我也是受其启发,才在文章中的关键部分的解释上有所领悟)
求在给定的字符创string中搜索pat(模式字符串)第一次出现的位置i
2.Boyer-Moore算法的原理
算法的基本思想是:从字符串的右边开始匹配比较比从字符串左面开始匹配比较能够获得更多的信息,以减少字符的比较次数。
如果pat从string的最左面(开始处)进行匹配,那么pat和string的开始字符是对齐的。下面考虑从后往前的方法能够为我们带来什么好处,设取string的第patlen个字符char,那么char与pat的最后一个字符对齐,我们有一下结论:
结论1:如果我们知道char没有在pat中出现,那么我们就不需要考虑pat在string的第1-patlen个位置上出现的可能性(pat可能出现在第1到patlen个位置上的条件是char在pat中出现)
结论2:更一般的,如果char在pat中最接近尾部出现的位置是delta1(计数是从pat的右边往左数),那么我们可以无需比较,直接将pat后移delta1个位置。
基于以上两点,我们可以尽可能多的后移pat,同时减少比较次数。当char没有出现在pat中,delta1就等于patlen,这时可以直接将pat后移,而不用比较string的前patlen-1个字符与pat的关系。
现在假设char与pat的最后一个字符匹配,这时就采用回退比较的方式来比较剩余的字符是否匹配,即比较pat倒数第二个与char前面一个,以此类推。这时如果匹配成功,该算法就退出。如果在pat中的后m个字符已经匹配成功时,出现了一个新的字符char匹配失败,这时需要考虑如何尽可能多的后退pat!
原文中关于后退的第一个方案描述,我使用上图进行解释,c为不匹配的字符,当c出现在已匹配的m个字符中时,这时的效率是低下的,出现了pat回退的现象;当c出现在不匹配的字符中时,pat前移的长度为delta1(c)-m。
前面提到了delta1是一个函数,返回字符距离pat末尾的距离。
在这里提出了一个新的问题,即第一个不匹配位置的字符如果出现在了pat的已匹配的串中(上图中的最后一个移动的情况),那么移动显然是低效的。如果记已经匹配的m个字符为subpat,同时在不匹配位置,记string对应位置为c,pat中对应位置为a。用c+subpat表示以c引导的subpat串,为了保证最大右移和正确性,这时我们需要找到pat自a起前面的串中是否含有形如x+subpat(x!=a)的子串,如果存在则可以将pat后移,使得第一个x+subpat的x与string的c对齐。
上文中的绿色部分我称为后移方案1,红色部分称之为后移方案2。实际上这两种方案是互为补充的,当方案1出现了低效的情况,则使用方案2代替。这一点在后面的为算法中有所体现。
算法的伪代码如下:
上图中使用红色框标识的部分就是上文中提到的方案1和方案2的互补措施。
下面来说说delta1和delta2
delta1(char) = patlen if char 没有在pat中出现
delta1(char) = patlen - j if char出现在pat中,j为char在pat中的最后一个出现位置
delta2
定义:设有序列[C1,C2,...,Cn]和[B1,B2,...,Bn],如果对于i(i=1-n),有Ci=Bi或者Ci=$或者Bi=$,我们就说两个序列是一致的($代表空)。
例子:序列[$,$,$,a,b,c]和[a,b,$,a,b,c]就是一致的
定义rpr(j):粗略的说来,rpr(j)代表的是subpat重现位置。严格定义如下
rpr(j) = max{k|k<=patlen && [pat(j+1),...pat(patlen)]与[pat(k),...,pat(k+patlen-j-1)]是一致的 && pat(k-1)!=pat(j) || k<=1 }
这个图演示了如何来计算rpr(j)
有了rpr(j),我们可以计算出pat需要后移步数为 j+1-rpr(j),同时将匹配位置移动到pat尾部需要patlen-j步。由于在实际操作过程中,pat是不动的,这种移动被相对的转移到了string上,因此string上的匹配位置应该后移delta2 = { j+1-rpr(j)} + {patlen-j} = patlen + 1 - rpr(j).
小结:个人觉得花了这么长时间还是把这个算法的基本原理是弄懂了,它的关键就应该在我说的方案2的计算上,这一点好像和KMP算法有相似之处。关于算法的其它问题,例如实现,请参看我下面的参考文献。如发现错误,敬请您留言。
参考文献:
Boyer-Moore的wiki主页:http://en.wikipedia.org/wiki/Boyer%E2%80%93Moore_string_search_algorithm
Boyer-Moore的论文:http://www.cs.utexas.edu/~moore/publications/fstrpos.pdf
小北的家:http://blog.csdn.net/ijuliet/article/details/4200771 (主要还是参考了上面的论文,不过她把关键的英文部分弄懂了,我也是受其启发,才在文章中的关键部分的解释上有所领悟)

相关文章推荐
- 字符串匹配算法之"Boyer Moore"
- Boyer-Moore(BM)算法,文本查找,字符串匹配问题
- 字符串匹配的 Boyer-Moore 算法
- 字符串匹配算法之KMP&Boyer-Moore
- 字符串匹配算法之 ---- Boyer-Moore 算法
- 字符串匹配的 Boyer-Moore 算法
- 字符串匹配算法之Boyer-Moore-Horspool Algorithm
- 浅谈字符串匹配的几种算法(KMP,Boyer-Moore)
- BM(Boyer-Moore)字符串匹配算法的实现(一种有效常用的字符串匹配算法)
- 字符串匹配算法 之 (Horspool )Boyer-Moore-Horspool
- 字符串匹配算法之Boyer-Moore
- 字符串匹配算法 之 BM(Boyer-Moore)
- 字符串匹配算法,Boyer-Moore 算法
- 高效字符串匹配之Boyer-Moore & Rabin-Karp
- 字符串匹配-BM算法改进SUNDAY--Boyer-Moore-Horspool-Sunday Aglorithm
- 字符串匹配(Boyer-Mooer 算法)
- 字符串匹配算法——Boyer-Moore算法
- 字符串匹配的Boyer-Moore算法 作者: 阮一峰 日期: 2013年5月 3日 上一篇文章,我介绍了KMP算法。 但是,它并不是效率最高的算法,实际采用并不多。各种文本编辑器的"查找"功能(Ct
- 字符串匹配算法集合
- 字符串匹配算法总结