以Object 为中心和以Database为中心进行应用程序设计导致的后期修改的分析
2011-07-16 17:00
711 查看
现在回想起来,当时触发了下面的这一段的思考的主要原因是当时在学习NHiberante的时候,对于基于NHibernate应用程序的设计方式的区别,是直接设计数据库然后设计对象模型还是先设计对象模型然后由对象模型生成数据库,当时主要是考虑到后期修改的影响。
进行分析的依据是从数据处理的过程来考虑的,主要是获取数据、处理数据、展现数据的过程,针对如果Schema修改的话,将会影响数据库处理的各个方面的那些内容。
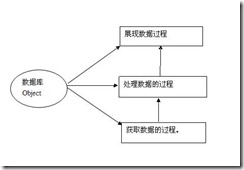
Database Schema修改影响分析:
1. 获取数据的过程。 如果获取数据的时候没有采用*,而是采用了具体的字段名,那么修改Schema必然导致对获取数据的表映射或者SQL或者视图或者存储过程等产生影响。而采用*的坏处就是存在效率问题,这在SQL中是不推荐使用的。另外还有一点,即便采用了*,如果有些新增字段或者其他表中计算字段依赖与*中的某些字段,这些地方也可能受到影响。
2. 处理数据的过程。 这个过程包含两部分:第一部分是获取数据后对数据进行处理,第二部分是保存数据时对数据进行处理。实现的方式有可能是通过服务器端代码来实现,也有可能借助数据库的存储过程或函数来实现。
a) 获取数据后对数据处理。比如将数据展现为用户希望的数据,求合计值, 翻译枚举值,根据业务逻辑处理数据(比如根据根据一堆的单据计算费用列表),这些过程中都存在着对某个明确字段的处理。这时候database schema 修改会对这一过程产生影响的。
b) 保存数据的时候对数据处理。这个过程主要是对用户输入的数据进行校验和处理。比如有效性校验,唯一性校验,业务算法处理,生成冗余表等。这个过程基本上没有通过*来处理数据的吧。所以这个过程受到 database Schema的影响是最多的。
3. 展现数据的过程。 这个过程中使用*的是有并不多见,基本上都是明确的字段。主要是因为根据用户的要求,字段存在展现顺序,字段有独特的展现方式,有些对字段只读、编辑方式的规则等(以公司的GSF为例),像这些地方都是以具体的列名呈现的。数据库的Database Schema修改对这里影响最大。当然这些变化可以隔离到获取数据的过程中,如果这样的话,就不能在获取数据的过程中使用*,因为获取数据的过程存在的一个任务就是要对界面呈现的字段和数据库的字段进行映射。界面处理比较麻烦的还有一个地方就是同一份数据可能在多个地方展现,比如说弹出窗体,列表,报表。从工作量上来说修改Database Schema,界面修改的工作量最大了。此时最好的做法就是界面的设置要文本化,可以批量替换,然后冒烟即可。
综上所述:当database schema修改的时候,在一个以Database为中心的Application中,获取数据、处理数据、展现数据的过程都会受到影响。其中展现数据和处理数据的过程受到的影响最大。
如果是采用Object的方式的:
1.获取数据的过程:如果是根据ID获取某个对象,那么当Domain Class修改的话,编译即可发现问题,如果是HSQL或者criteria方式或者SQL,这个过程中由于这些属性都是通过字符串形式展现的,比如上面的HSQL查询例子中,那么像这些地方只有运行时才能发现错误,编译时发现不了错误,Domain Class修改的还是会产生影响。想想,这个问题或许可以通过单元测试来解决。
2.处理数据的过程。 这个过程由于都是通过Object来进行处理的,所以基本上不受到影响。当然要保证获取的数据时正确的。
3.展现数据的过程。这个过程不了解,暂时留个疑问。
当然,上述假设的前提是可以根据Object Mapping Files来生成Database,在这种情况中,基本上不需要在Mapping Files中指定列名。如果指定了列名,那么可能修改的只有Mapping Files一处地方,比较集中。这也是比较好的事情。
综述:
依稀记得谁说过在设计一个数据结构或者类的时候,最好要有self-dected的信息,不过像这种DataSet 和Database的关联关系就比较麻烦了。如果都采用*还可以,如果通过具体的列名来指定映射,一旦Database Schema修改了,那么其后的一切都是要修改的。从目前对NHibernate了解来看,Database Schema修改后同样需要修改Mapping Files,不过从另一个角度来说,如果所有的一切都是以Object为中心,那么当Object某个属性修改后,首先在Class的层面可以通过工具都修改完毕,编译通过应该就没有什么事情了,然后根据Mapping Files生成相应的数据库。这貌似也是NHibernate的一个优点。
在一个应用程序中,数据库修改多是增删操作,而修改某个字段的名字的情况则比较少见。不过对于增删字段或者表的操作,如果能够在编译时就能发现或改正错误总比在运行时报出来好一些。运行时发现的错误多数都是地雷阵,有时候需要一个工兵集团军才能排除彻底。
进行分析的依据是从数据处理的过程来考虑的,主要是获取数据、处理数据、展现数据的过程,针对如果Schema修改的话,将会影响数据库处理的各个方面的那些内容。
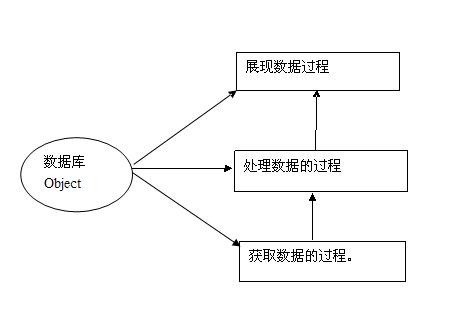
Database Schema修改影响分析:
1. 获取数据的过程。 如果获取数据的时候没有采用*,而是采用了具体的字段名,那么修改Schema必然导致对获取数据的表映射或者SQL或者视图或者存储过程等产生影响。而采用*的坏处就是存在效率问题,这在SQL中是不推荐使用的。另外还有一点,即便采用了*,如果有些新增字段或者其他表中计算字段依赖与*中的某些字段,这些地方也可能受到影响。
2. 处理数据的过程。 这个过程包含两部分:第一部分是获取数据后对数据进行处理,第二部分是保存数据时对数据进行处理。实现的方式有可能是通过服务器端代码来实现,也有可能借助数据库的存储过程或函数来实现。
a) 获取数据后对数据处理。比如将数据展现为用户希望的数据,求合计值, 翻译枚举值,根据业务逻辑处理数据(比如根据根据一堆的单据计算费用列表),这些过程中都存在着对某个明确字段的处理。这时候database schema 修改会对这一过程产生影响的。
b) 保存数据的时候对数据处理。这个过程主要是对用户输入的数据进行校验和处理。比如有效性校验,唯一性校验,业务算法处理,生成冗余表等。这个过程基本上没有通过*来处理数据的吧。所以这个过程受到 database Schema的影响是最多的。
3. 展现数据的过程。 这个过程中使用*的是有并不多见,基本上都是明确的字段。主要是因为根据用户的要求,字段存在展现顺序,字段有独特的展现方式,有些对字段只读、编辑方式的规则等(以公司的GSF为例),像这些地方都是以具体的列名呈现的。数据库的Database Schema修改对这里影响最大。当然这些变化可以隔离到获取数据的过程中,如果这样的话,就不能在获取数据的过程中使用*,因为获取数据的过程存在的一个任务就是要对界面呈现的字段和数据库的字段进行映射。界面处理比较麻烦的还有一个地方就是同一份数据可能在多个地方展现,比如说弹出窗体,列表,报表。从工作量上来说修改Database Schema,界面修改的工作量最大了。此时最好的做法就是界面的设置要文本化,可以批量替换,然后冒烟即可。
综上所述:当database schema修改的时候,在一个以Database为中心的Application中,获取数据、处理数据、展现数据的过程都会受到影响。其中展现数据和处理数据的过程受到的影响最大。
如果是采用Object的方式的:
1.获取数据的过程:如果是根据ID获取某个对象,那么当Domain Class修改的话,编译即可发现问题,如果是HSQL或者criteria方式或者SQL,这个过程中由于这些属性都是通过字符串形式展现的,比如上面的HSQL查询例子中,那么像这些地方只有运行时才能发现错误,编译时发现不了错误,Domain Class修改的还是会产生影响。想想,这个问题或许可以通过单元测试来解决。
2.处理数据的过程。 这个过程由于都是通过Object来进行处理的,所以基本上不受到影响。当然要保证获取的数据时正确的。
3.展现数据的过程。这个过程不了解,暂时留个疑问。
当然,上述假设的前提是可以根据Object Mapping Files来生成Database,在这种情况中,基本上不需要在Mapping Files中指定列名。如果指定了列名,那么可能修改的只有Mapping Files一处地方,比较集中。这也是比较好的事情。
综述:
依稀记得谁说过在设计一个数据结构或者类的时候,最好要有self-dected的信息,不过像这种DataSet 和Database的关联关系就比较麻烦了。如果都采用*还可以,如果通过具体的列名来指定映射,一旦Database Schema修改了,那么其后的一切都是要修改的。从目前对NHibernate了解来看,Database Schema修改后同样需要修改Mapping Files,不过从另一个角度来说,如果所有的一切都是以Object为中心,那么当Object某个属性修改后,首先在Class的层面可以通过工具都修改完毕,编译通过应该就没有什么事情了,然后根据Mapping Files生成相应的数据库。这貌似也是NHibernate的一个优点。
在一个应用程序中,数据库修改多是增删操作,而修改某个字段的名字的情况则比较少见。不过对于增删字段或者表的操作,如果能够在编译时就能发现或改正错误总比在运行时报出来好一些。运行时发现的错误多数都是地雷阵,有时候需要一个工兵集团军才能排除彻底。

相关文章推荐
- Symbian OS:MVC 设计模式在 SymbianOS 应用程序中的应用分析
- Android核心分析(20)----Android应用程序框架之无边界设计意图
- Android核心分析(20)----Android应用程序框架之无边界设计意图
- iOS应用程序安全(16)-使用iNalyzer对iOS应用进行动态分析
- 【原创】互斥锁使用分析 分类: Linux --- 应用程序设计 2015-07-22 11:57 6人阅读 评论(0) 收藏
- 软件开发中怎样有效地进行分析和设计
- 分析器错误信息: 在应用程序级别以外使用注册为 allowDefinition='MachineToApplication' 的节是错误的。导致该错误的原因可能是在 IIS 中没有将虚拟目录作为应用程序进行配置。
- 用UML进行面向构件分析与设计
- 类型的已垃圾回收委托进行了回调。这可能会导致应用程序崩溃、损坏和数据丢失。向非托管代码传递委托时,托管应用程序必须让这些委托保持活动状态,直到确信不会再次调用它们的问题的解决方法
- Vs2005之简单日志工具的制作--2.根据功能分析进行系统设计
- 【总结】在两个Activity之间进行跳转时出错原因分析(一)——findViewById位置不当导致
- 进行修改时,发现记录不完整及ognl.MethodFailedException: Method "delete" failed for object cn.chenbiao.house.web.ac
- .net CallBack::Invoke”类型的已垃圾回收委托进行了回调。这可能会导致应用程序崩
- iOS应用程序安全(4)-用Cycript进行运行时分析(Yahoo天气应用)
- 在 NetBeans IDE 中对 Java 应用程序进行性能分析的简介
- 使用UML类图进行Java应用程序设计
- QQ游戏设计中心:实例分析之活动设计方法
- 用EA轻松进行分析设计
- 未开启自定义菜单 由于开发者通过接口修改了菜单配置,当前菜单配置已失效并停用。你可以前往开发者中心进行停用。
- oracle rac环境下,修改参数cluster_database导致的ORA-29707与ORA-01102