数据表设计实例文档版本管理系统表设计
2010-10-08 13:29
771 查看
问题描述
文档版本管理最主要的是要维护文档的版本链。这很容易让人想到链表这种数据结构,所以我的那位朋友很快就给出了如下的表结构:
其中Docunment_PreId存放前一版本文档的Id,Docunment_NxtId存放下一版本文档的Id。
起初还没有感觉出什么问题,但当他试图向Table_Docunment填充测试数据或试图写一个存储过程来获取其链上最新的文档时,感觉非常痛苦。
在他的存储过程中需要进行循环,他自己知道这样性能不好,但又不清楚如何解决。
解决方案
问题的关键在于初始的设计并不适合系统的使用场景。原始的设计导致了取某文档的下一版本或上一版本都需要进行连接(Join)操作,若要获得最新版本文档,还需要进行循环。
对原始设计进行修改,新的表结构如下(省略了部分字段):
其中Docunment_ChainId为当前文档所属的版本链,Docunment_VersionId为当前文档在版本链中的版本号(从1开始的连续编号)。
在列(Docunment_ChainId, Docunment_VersionId)上可加unique约束。
举例来说,有如下两条文档链:

(图1)
其中文档上方的两个数字分别代表文档编号(Docunment_Id)和版本编号(Docunment_VersionId)。把这些信息存储到新的Table_Docunment中,结果如下:
对于给定的一个文档,要找其上一版本或下一版本的文档时,只要找其同一条链上版本号小1或大1的文档。若要找最新版本文档只要在链上对版本号取max就行了,也很方便。
新的需求
这样的设计已基本满足我那位朋友的需求了,但在某些使用场景下,情况可能会更复杂些。
若文档链有文档归并的情况,即两个文档链的最新文档版本是同一个文档,示意图如下:

(图2)
对于这个新的需求,先前的设计就会有一些问题,对于图中文档1007,其版本号对于链1应为5,对于链2应为4,实在是没办法填,我先用了一个问号。
新的需求改变了链和文档之间的关系。原先链和文档之间为1对多关系(注:标准情况下1对多关系会有两张表,但由于链在此系统中是一个虚概念,而且链实体也只会包含一个Id列,所以在先前设计中省去),现在链和文档之间变为多对多关系。多对多关系需要3张表,两个实体表,一个关系表。在此系统中链的实体表可以省去,所以我们只要引入一张关系表。
重构原先设计,脚本如下:
主要是添加了Table_DocChain这张关系表,对于我在此表上加的约束大家可以自己思考。
检验一下重构后的设计,把图2中的信息存入新的表结构中。
Table_Docunment:
Table_DocChain:
其中关键的两行记录已用粗体标出。
反过来思考
前一节讨论了文档归并的情况。有文档归并,就有可能出现文档分支,那该如何处理呢?是否需要修改设计?
我们先看一下文档分支的示意图:

(图3)
文档分支没有改变链和文档之间的关系,所以我自己觉得前面的表结构设计不需要修改。
那图3中分支链上的问号处如何填呢?
当文档进行分支时,其已经不归属于原先的链了,应新创建一条链。图3中,当文档1005分支时,在表Table_DocChain中应插入一条DocChain_ChainId:3, DocChain_VersionId: 1, Docunment_Id: 1005的记录,此分支的随后文档都归属此新链,这样问题就解决了。
防止文档链成环
对于文档链的一个重要约束是不能成环。这个约束可以在应用程序端实现,但数据库端的检查永远是我们最后的一道防线。我们应尽可能通过约束或其他手段来避免错误数据进入数据库。
如果能用check约束来避免链成环是最为直接的,在Table_DocChain中加如下约束:
其逻辑是在同一条链中,不存在版本号不同,且文档号相同的记录。
但非常可惜无论在SQL Server 2008还是Oracle中,check约束都不允许使用子查询(Subqueries)。
我们可以通过带有with check option的视图来达到目的,代码如下:
对于Table_DocChain的插入、修改,都通过View_DocChain来进行,就能防止文档链成环的发生。
文档版本管理最主要的是要维护文档的版本链。这很容易让人想到链表这种数据结构,所以我的那位朋友很快就给出了如下的表结构:
create table Table_Docunment ( Docunment_Id int not null identity(1000, 1) primary key, Docunment_Name nvarchar(64) not null, Docunment_SubmitDate datetime not null, Docunment_PreId int not null default(-1), Docunment_NxtId int not null default(-1), ....... );
其中Docunment_PreId存放前一版本文档的Id,Docunment_NxtId存放下一版本文档的Id。
起初还没有感觉出什么问题,但当他试图向Table_Docunment填充测试数据或试图写一个存储过程来获取其链上最新的文档时,感觉非常痛苦。
在他的存储过程中需要进行循环,他自己知道这样性能不好,但又不清楚如何解决。
解决方案
问题的关键在于初始的设计并不适合系统的使用场景。原始的设计导致了取某文档的下一版本或上一版本都需要进行连接(Join)操作,若要获得最新版本文档,还需要进行循环。
对原始设计进行修改,新的表结构如下(省略了部分字段):
create table Table_Docunment ( Docunment_Id int not null identity(1000, 1) primary key, Docunment_Name nvarchar(64) not null, Docunment_ChainId int not null default(-1), Docunment_VersionId int not null default(-1), Docunment_SubmitDate datetime not null, ...... );
其中Docunment_ChainId为当前文档所属的版本链,Docunment_VersionId为当前文档在版本链中的版本号(从1开始的连续编号)。
在列(Docunment_ChainId, Docunment_VersionId)上可加unique约束。
举例来说,有如下两条文档链:
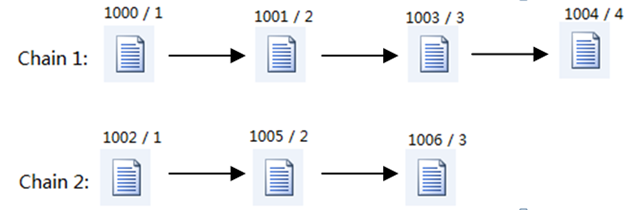
(图1)
其中文档上方的两个数字分别代表文档编号(Docunment_Id)和版本编号(Docunment_VersionId)。把这些信息存储到新的Table_Docunment中,结果如下:
| Docunment_Id | Docunment_Name | Docunment_ChainId | Docunment_VersionId | Docunment_SubmitDate | …… |
| 1000 | aaa | 1 | 1 | 2010-01-01 12:03:00 | …… |
| 1001 | bbb | 1 | 2 | 2010-01-02 06:02:00 | …… |
| 1002 | ccc | 2 | 1 | …… | …… |
| 1003 | …… | 1 | 3 | …… | …… |
| 1004 | …… | 1 | 4 | …… | …… |
| 1005 | …… | 2 | 2 | …… | …… |
| 1006 | …… | 2 | 3 | …… | …… |
新的需求
这样的设计已基本满足我那位朋友的需求了,但在某些使用场景下,情况可能会更复杂些。
若文档链有文档归并的情况,即两个文档链的最新文档版本是同一个文档,示意图如下:
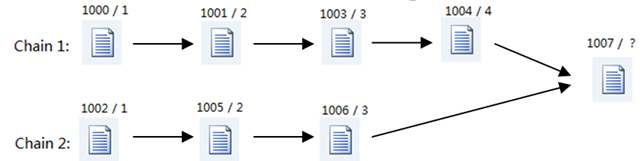
(图2)
对于这个新的需求,先前的设计就会有一些问题,对于图中文档1007,其版本号对于链1应为5,对于链2应为4,实在是没办法填,我先用了一个问号。
新的需求改变了链和文档之间的关系。原先链和文档之间为1对多关系(注:标准情况下1对多关系会有两张表,但由于链在此系统中是一个虚概念,而且链实体也只会包含一个Id列,所以在先前设计中省去),现在链和文档之间变为多对多关系。多对多关系需要3张表,两个实体表,一个关系表。在此系统中链的实体表可以省去,所以我们只要引入一张关系表。
重构原先设计,脚本如下:
create table Table_Docunment ( Docunment_Id int not null identity(1000, 1) primary key, Docunment_Name nvarchar(64) not null, ...... ); create table Table_DocChain ( DocChain_ChainId int not null, DocChain_VersionId int not null default(1) check(DocChain_VersionId >= 1), Docunment_Id int not null references Table_Docunment(Docunment_Id), DocChain_SubmitDate datetime not null, primary key(DocChain_ChainId, DocChain_VersionId) );
主要是添加了Table_DocChain这张关系表,对于我在此表上加的约束大家可以自己思考。
检验一下重构后的设计,把图2中的信息存入新的表结构中。
Table_Docunment:
| Docunment_Id | Docunment_Name | …… |
| 1000 | aaa | …… |
| 1001 | bbb | …… |
| 1002 | ccc | …… |
| 1003 | …… | …… |
| 1004 | …… | …… |
| 1005 | …… | …… |
| 1006 | …… | …… |
| 1007 | …… | …… |
| DocChain_ChainId | DocChain_VersionId | Docunment_Id | DocChain_SubmitDate |
| 1 | 1 | 1000 | 2010-01-01 12:03:00 |
| 1 | 2 | 1001 | 2010-01-02 06:02:00 |
| 2 | 1 | 1002 | …… |
| 1 | 3 | 1003 | …… |
| 1 | 4 | 1004 | …… |
| 1 | 5 | 1007 | …… |
| 2 | 2 | 1005 | …… |
| 2 | 3 | 1006 | …… |
| 2 | 4 | 1007 | …… |
反过来思考
前一节讨论了文档归并的情况。有文档归并,就有可能出现文档分支,那该如何处理呢?是否需要修改设计?
我们先看一下文档分支的示意图:

(图3)
文档分支没有改变链和文档之间的关系,所以我自己觉得前面的表结构设计不需要修改。
那图3中分支链上的问号处如何填呢?
当文档进行分支时,其已经不归属于原先的链了,应新创建一条链。图3中,当文档1005分支时,在表Table_DocChain中应插入一条DocChain_ChainId:3, DocChain_VersionId: 1, Docunment_Id: 1005的记录,此分支的随后文档都归属此新链,这样问题就解决了。
防止文档链成环
对于文档链的一个重要约束是不能成环。这个约束可以在应用程序端实现,但数据库端的检查永远是我们最后的一道防线。我们应尽可能通过约束或其他手段来避免错误数据进入数据库。
如果能用check约束来避免链成环是最为直接的,在Table_DocChain中加如下约束:
alter table Table_DocChain add constraint CK_LoopChain check(not exists (select * from Table_DocChain DC1 inner join Table_DocChain DC2 on DC1.DocChain_ChainId = DC2.DocChain_ChainId and DC1.DocChain_VersionId <> DC2.DocChain_VersionId and DC1.Docunment_Id = DC2.Docunment_Id ) );
其逻辑是在同一条链中,不存在版本号不同,且文档号相同的记录。
但非常可惜无论在SQL Server 2008还是Oracle中,check约束都不允许使用子查询(Subqueries)。
我们可以通过带有with check option的视图来达到目的,代码如下:
create view View_DocChain as select DC1.DocChain_ChainId, DC1.DocChain_VersionId, DC1.Docunment_Id, DC1.DocChain_SubmitDate from Table_DocChain DC1 where not exists (select * from Table_DocChain DC2 where DC1.DocChain_ChainId = DC2.DocChain_ChainId and DC1.DocChain_VersionId <> DC2.DocChain_VersionId and DC1.Docunment_Id = DC2.Docunment_Id ) with check option;
对于Table_DocChain的插入、修改,都通过View_DocChain来进行,就能防止文档链成环的发生。

相关文章推荐
- 文档版本管理系统 数据表设计
- 数据结构课程设计--图书管理系统
- Python备份文件、文件版本的学生管理系统如何实现(将数据保存在txt文件中)
- 用户权限设计(四)——基于RBAC模型的通用权限管理系统的设计(数据模型)的扩展【转】
- 通用数据权限管理系统设计
- 用户权限设计(三)——通用数据权限管理系统设计
- 周报——网络资源教学平台设计之课程管理系统E-R图及数据表
- 数据结构课程设计-通讯录管理系统c++版(顺序表存储,折半查找,递增排序)
- 模块管理常规功能自己定义系统的设计与实现(16--模块数据的导出和打印[1])
- 数据结构课程设计【家庭财务管理系统】
- 数据结构课程设计代码-家谱管理系统
- 数据结构课程设计—图书管理系统
- 大数据管理系统松耦合和紧耦合的架构设计及性能对比
- C# ASP.NET 走火入魔通用权限管理系统组件V3.2试用版下载地址【含数据库设计文档、使用手册】
- 用户权限设计(四)——基于RBAC模型的通用权限管理系统的设计(数据模型)的扩展
- 数据结构课程设计——通讯录管理系统
- 通用数据权限管理系统设计
- 数据结构课程设计-通讯录管理系统的设计与实现
- 通用数据权限管理系统设计
- 学生信息管理系统-数据结构课程设计