SQL 语句优化--IN语句优化案例
2008-09-15 20:15
330 查看
今天客户系统升级,通过DMVs性能分析查了一下,升级后发现一个语句执行时间比较长,执行语句要好几秒钟,调出语句如下:
select distinct field003 from ufi2j0n11179717502375 where
field003 not in ('','40288135120d660501120de2f8870140','40288135120d660501120de4b9ee014b',
'40288135120d660501120de9c3ba016c','40288135120d660501120df0460c01b2','40288135120d660501120df1dc2d01d3') and requestid in (select requestid from ufi8s6u81179717475734 where field001 in (select requestid from uft3a6h61176948132312 where field066 is not null and field197 between convert(datetime, '2008-08-16') and convert(datetime,'2008-09-15')) )
后来看了一下,这几表的数据
-- 表 dbo.uft3a6h61176948132312 : 988行
-- 表:dbo.ufi2j0n11179717502375 :713行
-- 表: dbo.ufi8s6u81179717475734 : 273行
发现这三张表都没有超过1千行数据,建立索引意义不大,为何如此慢,看看执行计划:
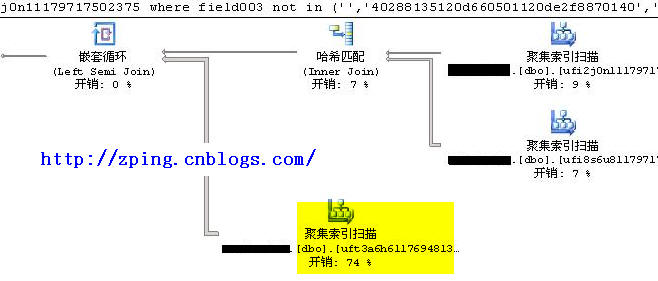
分析:发现是表dbo.uft3a6h61176948132312 访问开销最大,但表中数据不到一千行。执行看看结果:
(5 行受影响)
表 'uft3a6h61176948132312'。扫描计数 1,逻辑读取 27161 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'ufi8s6u81179717475734'。扫描计数 1,逻辑读取 37 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'ufi2j0n11179717502375'。扫描计数 1,逻辑读取 46 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
这里发现表uft3a6h61176948132312的访问有近3万次IO。 一开始以为是in的缘故,将in换成exists结果也是一样,这时考虑用inner join来重新写sql语句,语句如下:
select distinct a.field003 from ufi2j0n11179717502375 a
inner join ufi8s6u81179717475734 b on a.requestid=b.requestid
inner join uft3a6h61176948132312 c on b.field001=c.requestid
where a.field003 not in ('','40288135120d660501120de2f8870140','40288135120d660501120de4b9ee014b','40288135120d660501120de9c3ba016c','40288135120d660501120df0460c01b2','40288135120d660501120df1dc2d01d3') and c.field066 is not null and c.field197 between
convert(datetime, '2008-08-16') and convert(datetime,'2008-09-15')
查看执行计划:
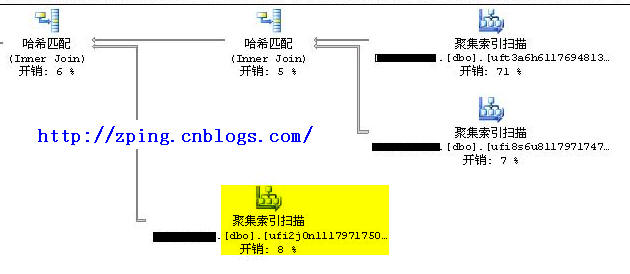
分析:这时发现执行计划发生了变化,最外层的表变成了dbo.ufi2j0n11179717502375,执行结果如下:
(5 行受影响)
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'ufi2j0n11179717502375'。扫描计数 1,逻辑读取 46 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'ufi8s6u81179717475734'。扫描计数 1,逻辑读取 37 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'uft3a6h61176948132312'。扫描计数 1,逻辑读取 421 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
这时发现整个IO次数比先前少了很多。
根据嵌套循环算法IO次数:421*(其他两个表的关联匹配行数)≈27163次 (访问表“uft3a6h61176948132312”IO次数),而这时由于返回的行数比较多,又没有建立索引,这时最佳的算法是使用“hash联结算法“
select distinct field003 from ufi2j0n11179717502375 where
field003 not in ('','40288135120d660501120de2f8870140','40288135120d660501120de4b9ee014b',
'40288135120d660501120de9c3ba016c','40288135120d660501120df0460c01b2','40288135120d660501120df1dc2d01d3') and requestid in (select requestid from ufi8s6u81179717475734 where field001 in (select requestid from uft3a6h61176948132312 where field066 is not null and field197 between convert(datetime, '2008-08-16') and convert(datetime,'2008-09-15')) )
后来看了一下,这几表的数据
-- 表 dbo.uft3a6h61176948132312 : 988行
-- 表:dbo.ufi2j0n11179717502375 :713行
-- 表: dbo.ufi8s6u81179717475734 : 273行
发现这三张表都没有超过1千行数据,建立索引意义不大,为何如此慢,看看执行计划:
分析:发现是表dbo.uft3a6h61176948132312 访问开销最大,但表中数据不到一千行。执行看看结果:
(5 行受影响)
表 'uft3a6h61176948132312'。扫描计数 1,逻辑读取 27161 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'ufi8s6u81179717475734'。扫描计数 1,逻辑读取 37 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'ufi2j0n11179717502375'。扫描计数 1,逻辑读取 46 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
这里发现表uft3a6h61176948132312的访问有近3万次IO。 一开始以为是in的缘故,将in换成exists结果也是一样,这时考虑用inner join来重新写sql语句,语句如下:
select distinct a.field003 from ufi2j0n11179717502375 a
inner join ufi8s6u81179717475734 b on a.requestid=b.requestid
inner join uft3a6h61176948132312 c on b.field001=c.requestid
where a.field003 not in ('','40288135120d660501120de2f8870140','40288135120d660501120de4b9ee014b','40288135120d660501120de9c3ba016c','40288135120d660501120df0460c01b2','40288135120d660501120df1dc2d01d3') and c.field066 is not null and c.field197 between
convert(datetime, '2008-08-16') and convert(datetime,'2008-09-15')
查看执行计划:
分析:这时发现执行计划发生了变化,最外层的表变成了dbo.ufi2j0n11179717502375,执行结果如下:
(5 行受影响)
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'ufi2j0n11179717502375'。扫描计数 1,逻辑读取 46 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'ufi8s6u81179717475734'。扫描计数 1,逻辑读取 37 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'uft3a6h61176948132312'。扫描计数 1,逻辑读取 421 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
这时发现整个IO次数比先前少了很多。
总结:
根据这两个执行计划分析,sql server 2005优化器对于in语句没有正确选择联结算法,错误的采用了采用了”嵌套循环算法“。根据嵌套循环算法IO次数:421*(其他两个表的关联匹配行数)≈27163次 (访问表“uft3a6h61176948132312”IO次数),而这时由于返回的行数比较多,又没有建立索引,这时最佳的算法是使用“hash联结算法“

相关文章推荐
- SQL 语句优化--IN语句优化案例
- SQL 语句优化--IN语句优化案例
- 性能优化分析案例---解决SQL语句过度消耗CPU问题
- Sql语句优化之explan分析案例
- sql语句优化之用EXISTS替代IN、用NOT EXISTS替代NOT IN的语句
- SQLServer 优化SQL语句 in 和not in的替代方案
- SQL 语句优化 案例1
- 如何用外部程序优化SQL语句中的IN和EXISTS
- 优化SQL语句:in 和not in的替代方案
- sql查询语句的优化,exists与in的更换
- 优化SQL语句:in 和not in的替代方案
- 关于in 和 exist 的区别-------------近期优化sql 语句的时候再次碰到
- 经典案例:如何优化Oracle使用DBlink的SQL语句
- sql查询语句的优化,exists与in的更换
- Oracle sql"NOT IN"语句优化,查询A表有、B表没有的数据
- SQLServer 优化SQL语句:in 和not in的替代方案
- 优化SQL 语句 in 和not in 的替代方案
- sql查询语句的优化,exists与in的更换
- 数据库性能优化分析案例---解决SQL语句过度消耗CPU问题
- SQL 语句优化--OR 语句优化案例